From training to training: Why language model hallucinations and how evaluation methods exacerbate the problem
Large language models (LLMS) often produce “illusions” – seemingly reasonable results but incorrect output. Despite improvements in training methods and architecture, the hallucination remains. A new study by Openai A rigorous explanation is provided: hallucinations stem from the statistical properties of supervised versus self-supervised learning and enhance their durability through misaligned evaluation benchmarks.
What makes hallucinations statistically inevitable?
The research team interprets hallucinations as errors inherent in generative modeling. Even with perfectly clean training data, the transcondensation objectives used for preprocessing introduces statistical pressure that produces errors.
The binary classification task that the research team reduces the problem to supervised is called is-it-it-valid(iiv): Determine whether the output of the model is valid or incorrect. They demonstrate that LLM generates error rates at least twice as much as its IIV error classification rate. In other words, the same reasons for hallucination occurring in supervised learning: cognitive uncertainty, poor models, allocation transfers, or noisy data.
Why do rare facts cause more hallucinations?
A main driver is Singleton Rate– Only a part of the fact appears once in the training data. If 20% of the facts are singletons, then at least 20% of the facts will be hallucinating compared to good mass estimates. This explains why LLM reliably answers to facts about widely repeated (such as Einstein’s birthday), but answers due to obscure or rarely mentioned facts.
Can poor model families lead to hallucinations?
Yes. When the model class cannot fully represent the pattern, hallucinations will also occur. Classic examples include N-Gram models that generate non-grammatical sentences, or because characters are hidden in sub-word tokens because characters hide letters. Even if the data itself is sufficient, these representation limits can lead to system errors.
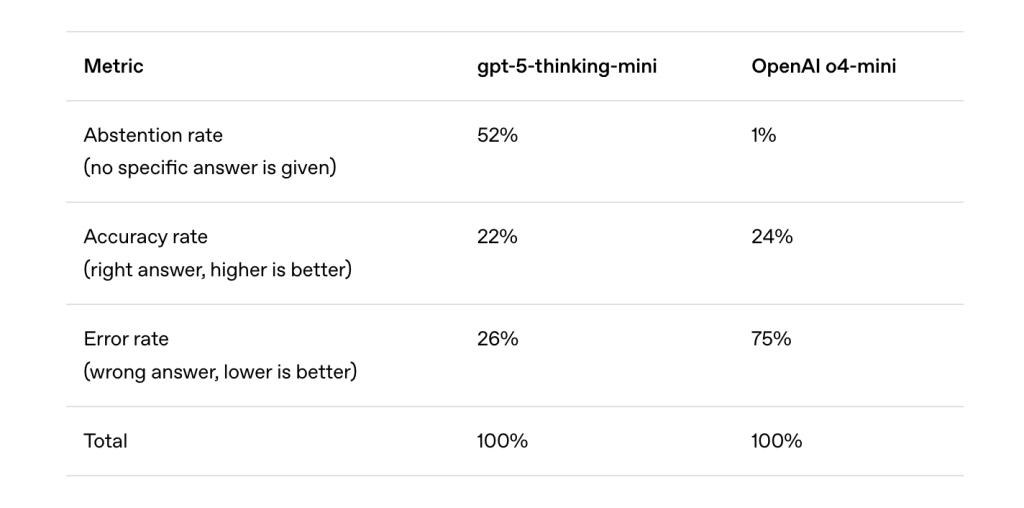
Why don’t hallucinations be eliminated after training?
Post-training methods such as RLHF (learning from human feedback), DPO and RLAIF reduce some errors, especially harmful or conspiring output. But because the assessment incentives are not aligned, there is still an hallucination of overconfidence.
Just like students guessing multiple choice exams, LLMS gets rewarded for bluffs when uncertain. Most benchmarks (such as MMLU, GPQA, and SWE benches) have binary ratings: the correct answer gets credit, the abstention (“I don’t know”) is not received, and the wrong answer gets punishment is no more severe than the abstention. Under this plan, guessing it can maximize the benchmark score even if hallucinations are promoted.
How to enhance illusion in rankings?
A review of popular benchmarks shows that nearly all people use binary hierarchies without partial uncertainty. As a result, models that express uncertainty are worse than models that always guess. This creates systematic pressure for developers to optimize confident answers rather than calibrate models.
What changes can reduce hallucinations?
The research team believes that repairing hallucinations requires socio-technical change, not just new evaluation kits. They suggest A clear confidence goal: The benchmark should clearly specify the fine and waiver of the partial credit for the wrong answer.
For example: “Only if you > 75% confidence. Lose 2 points in error; get 1 in correct answer; ‘I don’t know’ earn 0.”
The design reflects real-world exams, such as earlier SAT and GRE formats, and is guessed that fines are fines. It encourages Behavioral calibration– When their confidence is below the threshold, the model avoids hallucinations, thus making fewer hallucinations of overconfidence while still optimizing for benchmark performance.
What is the broader meaning?
This work reshapes hallucinations into predictable outcomes of training objectives and assessing misalignment, rather than inexplicable quirks. The survey results highlight:
- Expected inevitability: Hallucinations are parallel to misclassification errors in supervised learning.
- Reinforcement after training: Binary hierarchical scheme incentivizes guess.
- Evaluation reform: Adjusting mainstream benchmarks to reward uncertainty can re-adjust incentives and increase trust.
By connecting hallucinations with established learning theories, the study reveals its origins and proposes practical mitigation strategies for shifting responsibility from model architecture to evaluation design.
Check Paper and technical details are here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


