From fine-tuning to rapid engineering: Theory and practice of effective transformer adaptation
Challenges of fine-tuning large transformer models
Self-spout allows transformer models to capture remote dependencies in text, which is essential for understanding complex language patterns. These models work efficiently in large datasets and achieve excellent performance without task-specific structures. As a result, they are widely used in various industries including software development, education and content generation.
A key limitation in applying these powerful models is reliance on supervised fine-tuning. Adjusting the base transformer to a specific task often involves retraining the model with marked data that requires a large amount of computing resources, sometimes forming thousands of GPU hours. This presents a major obstacle for organizations that do not have access to such hardware or seek faster adaptation times. Therefore, there is a need to cause task-specific functions from pre-trained transformers without modifying their parameters.
Reasoning time hints as an alternative to fine-tuning
To address this problem, the researchers explored inference time techniques that use example-based inputs to guide the behavior of the model, thus bypassing the need for parameter updates. Among these methods, a practical method emerges in which the model receives a series of input and output pairs to generate predictions of new inputs. Unlike traditional training, these techniques operate during inference, enabling the basic model to demonstrate the required behavior based on the context only. Despite their commitment, there is limited formal evidence to confirm that such techniques can consistently align with fine-tuned performance.
Theoretical framework: Approximate fine-tuning model through cultural learning
Patched Codes, Inc. The researchers introduced a Transformer Integrity-based approach, showing that the basic model can learn the behavior of the approximate model using the internal context, providing sufficient computing resources and accessing the original training dataset. Their theoretical framework provides a quantifiable way to understand how dataset size, context length, and task complexity affects approximate quality. The analysis specifically examines two task types: text generation and linear classification – and establishes boundaries on dataset requirements to achieve fine-tuned outputs with defined error margins.
Timely design and theoretical guarantee
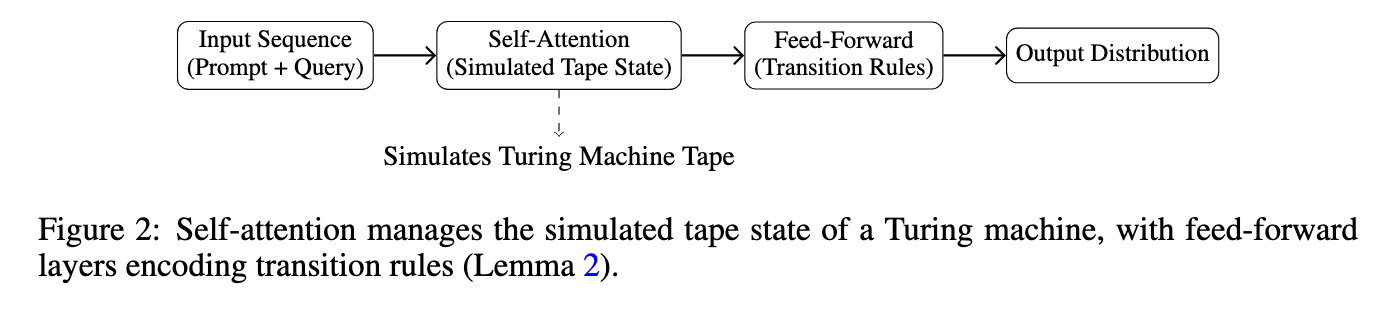
The method involves designing a prompt structure that connects the data set of tagged examples to the target query. The model processes this sequence, drawing the pattern from the example to generate a response. For example, the prompt may include input and output pairs, such as comments of emotional tags, and then make a new comment whose emotions must be predicted. The researchers constructed this process as a simulation of the Turing machine, where self-attention mimics the tape state and feeding layers as transitional rules. They also formalize the total change distance between the base and fine-tune output distributions, keeping within acceptable error ε. The paper provides constructs for this reasoning technique and quantifies its theoretical performance.
Quantitative results: Dataset size and task complexity
Researchers provide performance assurance based on dataset size and task type. Used for text generation tasks involving vocabulary size v, The dataset must be a dataset of sizeomvϵ2log1δ to ensure that the basic model approximates the model within the MMM context spans error ε. When the output length is fixed la smaller dataset of OL logvϵ2Log1Δ is sufficient. For linear classification tasks, the input has dimensions dthe required dataset size becomes ODϵ, or has context constraint O1ϵ2LOG1Δ. Under idealized assumptions, these results are reliable, but also applicable to practical constraints such as limited context length and partial dataset availability using techniques such as search effect generation.
Meaning: Going towards an efficient and scalable NLP model
This study presents a detailed and well-structured argument that the reasoning time cues can match with sufficient contextual data. It successfully identified a path to more resource-efficient deployment of large language models, both providing theoretical reasons and practical techniques. This study shows that leveraging the potential capabilities of models through structured cues is not only feasible, but also scalable and very effective for specific NLP tasks.
Check Paper. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.



