Google Research Unveils A pioneering approach for fine-tuning large language model (LLM) that cuts the amount of training data required to 10,000 timeswhile maintaining and even improving model quality. This approach focuses on active learning and expert labeling, labeling it as the most useful example, the “boundary case” where model uncertainty reaches its peak.
Traditional bottleneck
Fine-tuning LLMs for tasks requiring deep context and cultural understanding (such as AD content security or moderation) often require large, high-quality label datasets. Most data is benign, which means that only a small percentage of examples are important for detection of policy violations, increasing the cost and complexity of data curation. Standard approaches are also difficult to keep up with policy or problematic patterns, requiring expensive retraining.
Google’s active learning breakthrough
How it works:
- llm-as-scout: LLM is used to scan a large number of corpus (ten billions of examples) and determine the most uncertain case.
- Targeted expert tags: Instead of tagging thousands of random examples, human experts will comment only on these boundaries to confuse the project.
- Iterative planning: This process is repeated, and each batch of new “problem” examples are informed with confusion points of the latest model.
- Fast convergence: The model was fine-tuned over multiple rounds, and iterations continued until the model’s output was closely consistent with the expert’s judgment – Cohen’s Kappa kept the expert’s judgment consistent, which compared the chance annotator consistency.
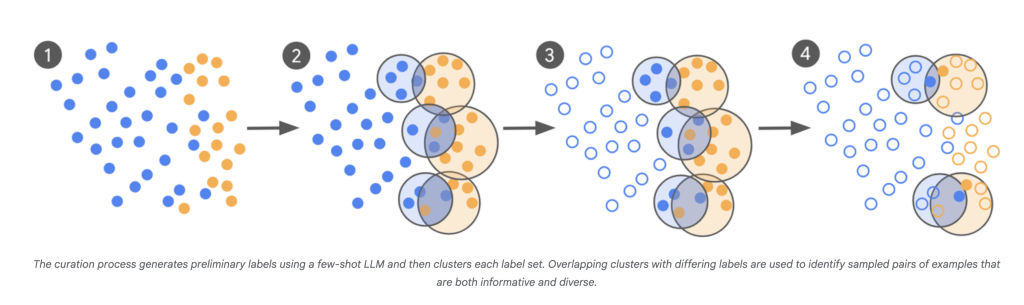
Influence:
- Data demand plummeted: In experiments using Gemini Nano-1 and Nano-2 models, consistency with human experts is equivalent to using parity 250–450 carefully selected examples Instead of ~100,000 random crowdsourcing tags, it is reduced by three to four orders of magnitude.
- Model quality increases: For more complex tasks and larger models, the performance improvement at baseline reaches 55-65%, demonstrating a more reliable consistency with policy experts.
- Tag efficiency: For reliable benefits of using tiny datasets, high label quality is always required (Cohen’s Kappa> 0.8).
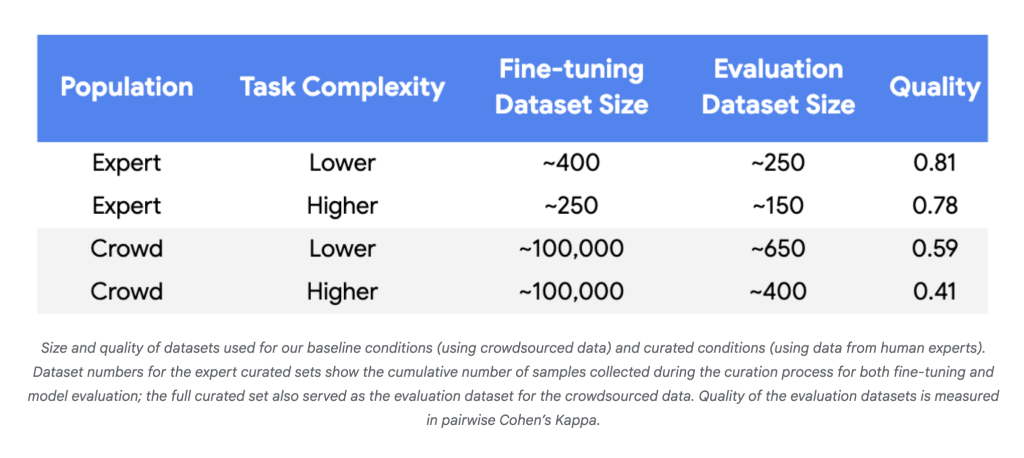
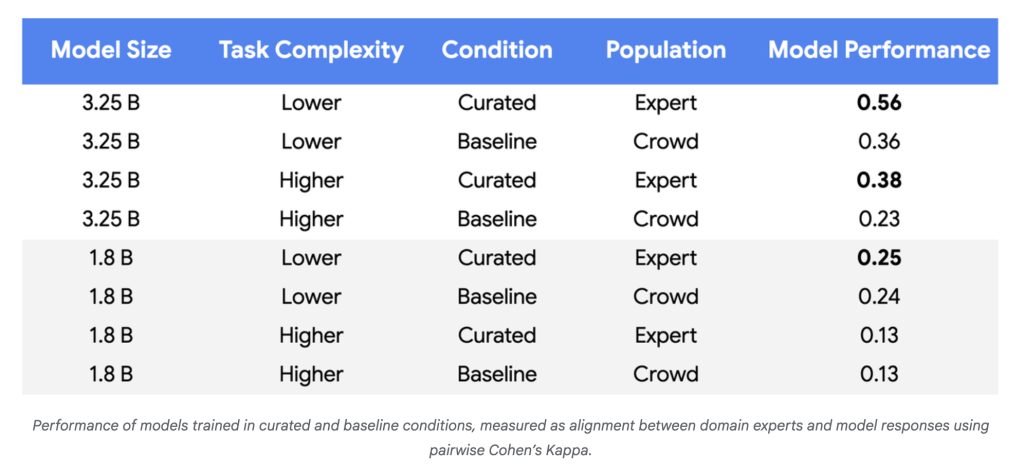
Why it matters
This approach flips the traditional paradigm. Instead of flooding the model in a large number of noisy, redundant data pools, it leverages LLMS’ ability to identify ambiguous cases and the domain expertise of human annotators, with its inputs with the most valuable capabilities. The benefits are profound:
- Reduce costs: The examples of marking are greatly reduced, greatly reducing labor and capital expenditures.
- Faster update speed: The ability to retrain the model in a few examples makes it possible to adapt to new abuse patterns, policy changes or rapid changes in areas and be feasible.
- Social impact: Enhanced capabilities in context and cultural understanding can improve the security and reliability of automated systems in processing sensitive content.
Anyway
Google’s new approach allows LLM to fine-tune complex, evolving tasks with only hundreds (no more than hundreds) of targeted high-fidelity tags – slimmer, more agile, more agile and cost-effective model development.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


