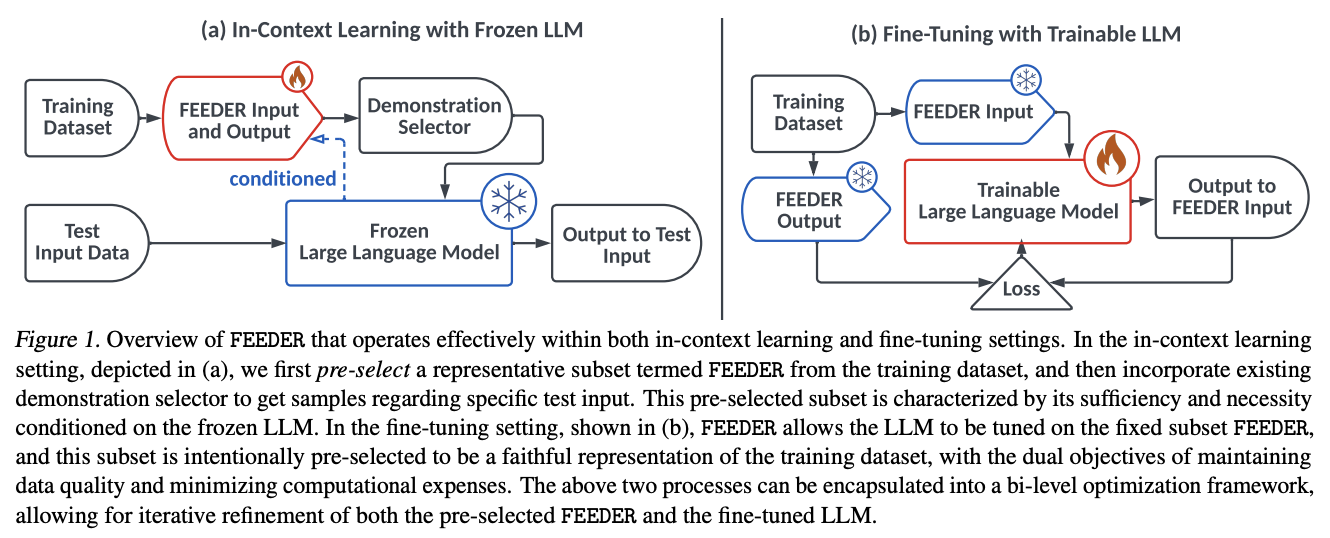
Feeder: Preselected frame for effective demonstration selection in LLMS
LLM shows excellent performance in multiple tasks by using very little shooting inference (also known as text learning (ICL). The main problem is to select the most representative presentations from large training datasets. Early methods selected a demonstration of correlation using similarity scores between each example and input questions. The current method recommends the use of additional selection rules and similarity to improve the efficiency of demonstration selection. These improvements introduce significant computational overhead as the number of lenses increases. The effectiveness of the selected demonstration should also consider the specific LLM in use, as different LLMs have different functional and knowledge areas.
Researchers at Shanghai Ruotang University, Beigang, Carnegie Mellon University, Peking University, No Affiliation, University College London and the University of Bristol have proposed the proposed breeder (little is necessary for pre-demonstration selectors), a core example of identifying the core demonstration, which contains the most representative examples of training data, adjusted to specific data, adjusted to specific data. To construct this subset, the “adequacy” and “necessity” metrics are in the pre-selection phase as well as the tree-based algorithm. Additionally, the feeder reduces the size of the training data by 20%, while maintaining performance and seamlessly integrating with various downstream demonstration selection techniques for ICL, ranging from 300m to 8b parameters.
Six text classification datasets were evaluated: SST-2, SST-5, COLA, TREC, SUBJ, and FPB, covering the tasks of emotion classification and language analysis to text tasks. Evaluation can also be performed on the inference dataset GSM8K, the semantic projection dataset SMCALFLOF, and the scientific question avoidance dataset GPQA. Follow the official segmentation of each dataset directly for training and testing data. Moreover, multiple LLM variants are utilized to evaluate the performance of the method, including two GPT-2 variants, GPT-neo with 1.3B parameters, GPT-3 with 6B parameters, Gemma-2 with 2B parameters, Llama-2 with 7B parameters, Llama-3 with 8B parameters, and Qwen-2.5 with 32B parameters as the LLM base.
Results on secret learning performance show that feeders can retain almost half of the training sample while achieving excellent or comparable performance. Evaluation of performance of a small amount of shooting on complex tasks using Gemma-2 (e.g. Gemma-2) shows that even if LLM works hard on challenging tasks, performance can be improved. It is effectively performed in large numbers of shots, and in the case of processing, when the number of examples increases from 5 to 10, LLM performance will generally degrade due to noisy or repeated demonstrations. In addition, the feeder minimizes the negative impact on LLM performance by evaluating the adequacy and necessity of each demonstration and contributes to the performance stability of the LLMS
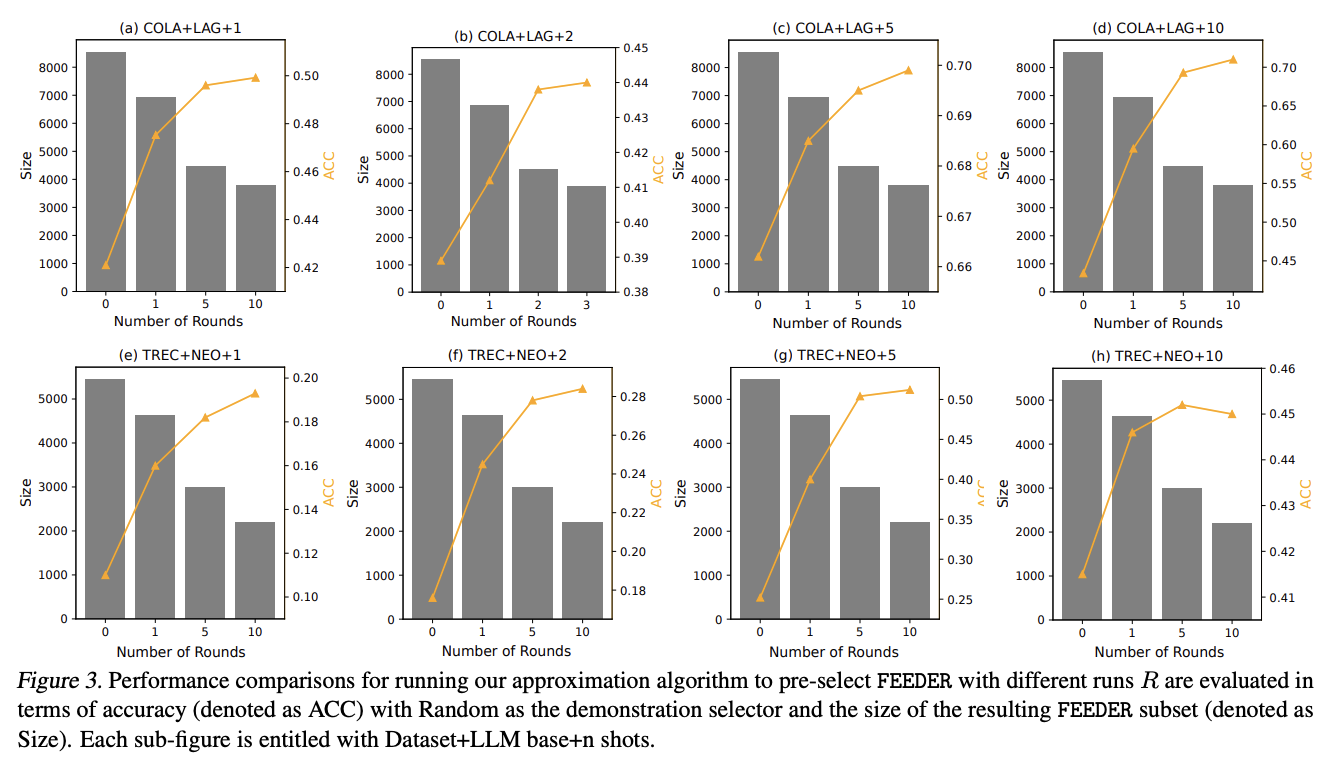
In terms of double-layer optimization, feeders improve performance by fine-tuning with a small but high-quality dataset while reducing computational expenses. The results show that fine-tuning LLMS provides greater performance improvements compared to enhancing LLM through context, while feeders achieve better performance improvements in fine-tuning settings. Performance analysis showed that feeder effectiveness first increased and then decreased with the increase in the number of runs or rounds (R and K, respectively), thus confirming that identifying the performance of representative subsets from the training dataset can enhance the performance of LLM. However, an overly narrowed subset may limit potential performance growth.
In summary, the researchers introduced the feeder, a pre-demo selector designed to use LLM functionality and domain knowledge to identify high-quality presentations through effective discovery methods. It reduces training data requirements while maintaining comparable performance, providing a practical solution for efficient LLM deployments. Future research directions include exploring applications using larger LLMs and extending the functionality of feeders to areas such as data security and data management. Feeders make valuable contributions to demonstration selection, providing researchers and practitioners with effective tools to optimize LLM performance while reducing computational overhead.
Check Paper. All credits for this study are to the researchers on the project.
Researchers with Nvidia, OpenAI, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgan, Amgan, Aflac, Aflac, Wells Fargo and 100s read AI Dev newsletters and researchers read. [SUBSCRIBE NOW]

Sajjad Ansari is a final year undergraduate student from IIT Kharagpur. As a technology enthusiast, he delves into the practical application of AI, focusing on understanding AI technology and its real-world impact. He aims to express complex AI concepts in a clear and easy way.

 and word error rate (WER) to mission success, barges and hallucinations")
