Falcon LLM team releases FALCON-H1 technical report: a hybrid attention-SSM model that matches 70B LLMS
introduce
The Falcon-H1 series developed by the Institute of Technology Innovation (TII) marks a significant advance in the evolution of the Big Language Model (LLMS). By integrating transformer-based attention with MAMBA-based state space model (SSM), Falcon-H1 achieves excellent performance, memory efficiency, and scalability. Released in a variety of sizes (0.5B to 34B parameters) and versions (basics, guided adjustments and quantization), the Falcon-H1 model redefined the tradeoff between computed budget and output quality, providing parameter efficiency compared to many contemporary models such as QWEN2.5-72B and LLAMA3.3-70B.
Key architectural innovation
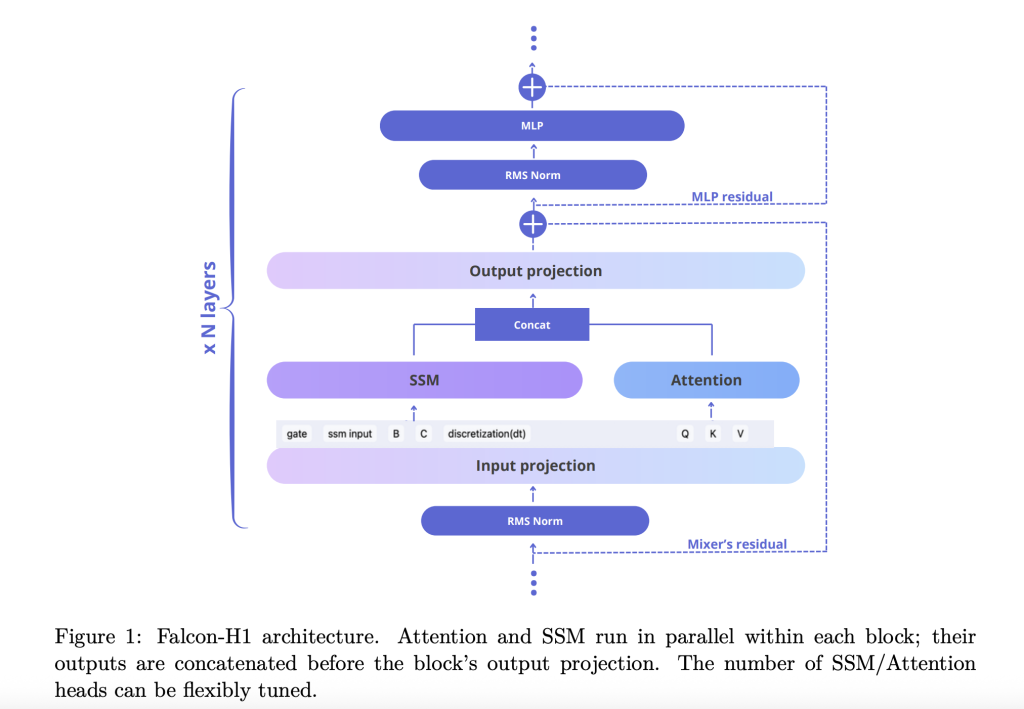
this Technical Report Explain how Falcon-H1 adopts novels Parallel hybrid architecture Both attention and SSM modules run simultaneously, and their outputs are connected before projection. The design deviates from traditional sequential integration and provides flexibility to adjust attention and SSM channels independently. The default configuration uses 2:1:5 ratios of SSM, Attention and MLP channels, respectively, optimizes efficiency and learning dynamics.

In order to further improve the model, Falcon-H1 explores:
- Channel allocation: Ablation indicates that increased attention channels can deteriorate performance, while balancing SSM and MLP produces strong growth.
- Block configuration: The SA_M configuration (semi-parallel, attention runs with SSM, followed by MLP) performs best in terms of training loss and computational efficiency.
- Rope basic frequency: In the rotational position embedding (rope), the abnormally high basic frequency is 10^11, which is proven to be optimal during training, which can improve the generalization.
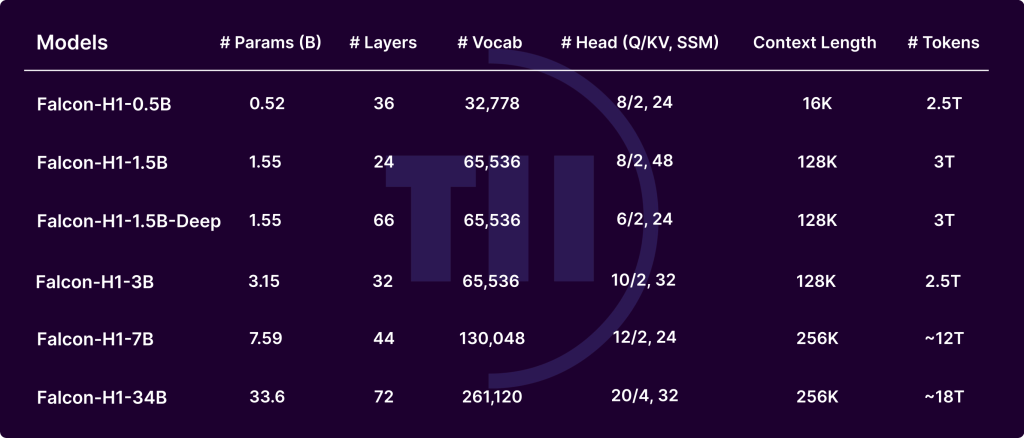
- Width and depth trade-offs: Experiments show that deeper models are better than wider models under fixed parameter budgets. The Falcon-H1-1.5B deep (66 layers) is better than many 3B and 7B models.
Token policy
Falcon-H1 uses a custom Byte Pair Encoding (BPE) token suite with vocabulary sizes ranging from 32K to 261K. Key design options include:
- Numbers and punctuation marks: Empirically improve the performance of code and multilingual settings.
- Latex Token Injection: Improve the model accuracy of mathematical benchmarks.
- Multilingual support: Use optimized fertility and token metrics to cover 18 languages and scales for 100+.
Training corpus and data strategies
The Falcon-H1 model can be trained up to 18 tons of tokens in a carefully curated 20T token corpus, including:
- High-quality network data (Filtered Webb)
- Multilingual dataset: Featured resources for normal crawling, Wikipedia, arxiv, opensubtitles and 17 languages
- Code Corpus: 67 languages, treated with Minhash Dewlipication, Codebert Quality Filters and PII Scrub
- Mathematical dataset: Mathematics, GSM8K and internal latex-enhanced crawlers
- Synthesize data: Rewrite from RAW Corpora using different LLMs, and textbook-style QA with 30k Wikipedia theme
- Long cultural sequence: Enhanced by intermediate fill, reorder and synthesis inference tasks, up to 256K tokens
Training Infrastructure and Methodology
Training utilizes custom maximum update parameterization (µP) to support smooth scaling across model sizes. The model adopts advanced parallelism strategies:
- Mixer Parallelity (MP) and Contextual Parallelity (CP): Enhanced throughput of long text processing
- Quantification: Issued in BFLOAT16 and 4-bit variants to facilitate edge deployment
Evaluation and performance
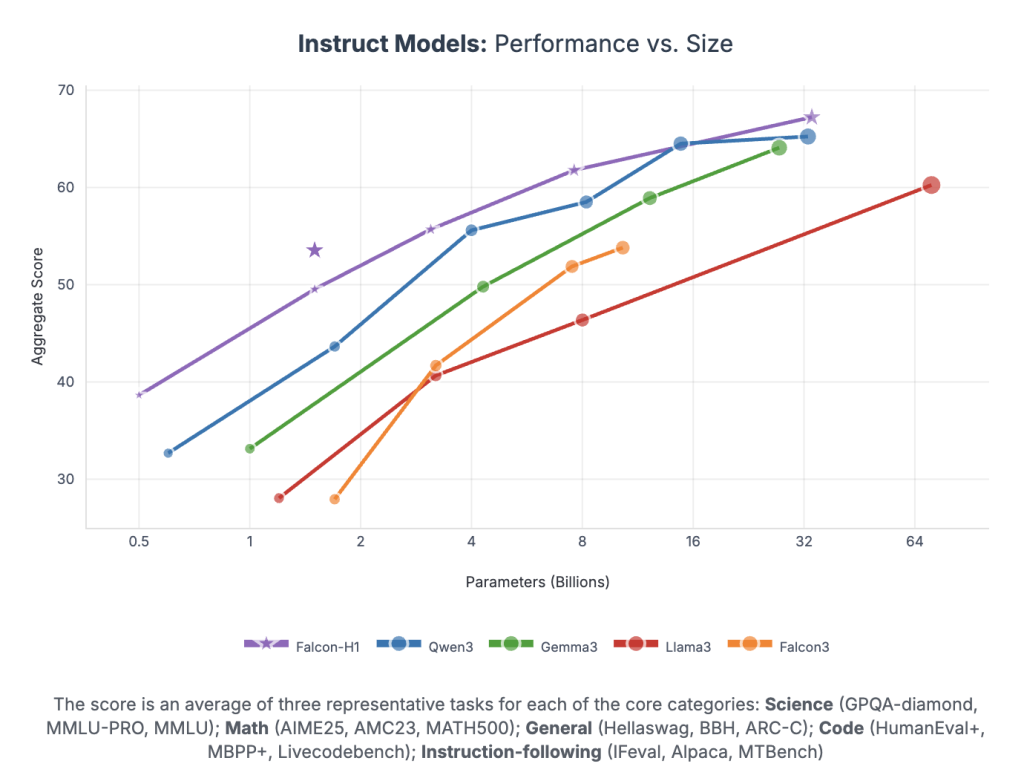
Falcon-H1 each parameter achieves unprecedented performance:
- Falcon-H1-34B teaching Beyond or match 70B-class models such as QWEN2.5-72B and LLAMA3.3-70B, across reasoning, math, mentoring and multilingual tasks
- Falcon-H1-1.5B Depth Competitor 7B – 10B Model
- Falcon-H1-0.5B Delivery of 2024-ERA 7B performance
The benchmarks span mmlu, gsm8k, HumaneVal and long lowercase tasks. These models show strong alignment through SFT and Direct Preference Optimization (DPO).
in conclusion
Falcon-H1 sets new standards for open-weight LLM by integrating parallel hybrid architectures, flexible tokenization, effective training dynamics and powerful multilingual capabilities. Its strategic combination of SSM and attention allows unrivalled performance in actual computing and memory budgets, making it ideal for research and deployment across a variety of environments.
Check Paper and model hugging face. random View various applications in our tutorial page on AI Agents and Agent AI. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


