DeepSeek v3.2-exp cuts novel cost with sparse attention (DSA) while maintaining benchmark parity
DeepSeek Release DeepSeek-v3.2-exp, “Intermediate” update added for v3.1 DeepSeek Sparse Attention (DSA)– Trainable sparse paths for long cultural efficiency. DeepSeek has also been reduced API price + 50% +consistent with the specified efficiency improvement.
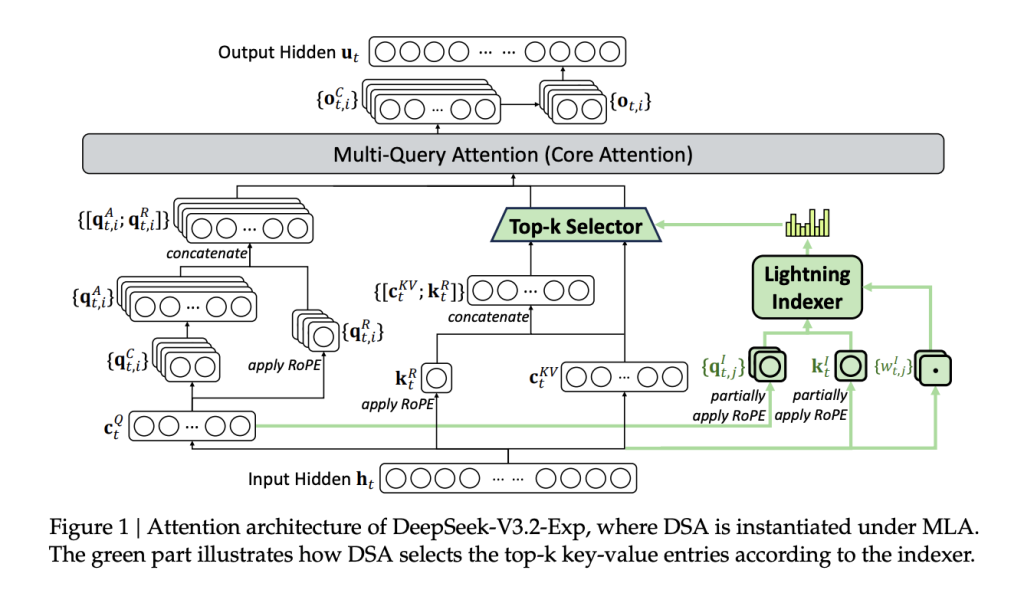
DeepSeek-V3.2-Exp Keep V3/v3.1 stack (MOE + MLA) and insert a Two stages of attention Path: (i) a lightweight “index” that scores context tokens; (ii) sparse attention to selected subsets.
FP8 index → TOP-K selection → Sparse core attention
DeepSeek Sparse Attention (DSA) Divide the attention path into two compute layers:
(1) Lightning indexer (FP8, several headers): For each query token ℎ∈𝑅Ht∈RD, the lightweight scoring function calculates the index logic 𝐼𝐼, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, s, for the previous token. It uses small index headers with relu nonlinearity for throughput. Because this stage runs in FP8 with few heads, its wall time and failure cost are smaller relative to intensive attention.
(2) Fine-grained token selection (TOP-K): The system only selects the top-k = 2048 key-value entry for each query, and then only performs standard attention on that subset. This changes the main item from 𝑂(𝐿2)o(l 2) to 𝑘(lk)o(lk), while retaining the ability to participate in any distant token if needed.
Training signal: The training indexer can be passed KL-Divergencefirst in short Intensive warm-up (The indexer learns the target when freezing the main model), then Sparse training The gradient of the indexer remains separated from the language loss of the main model. Warm up use ~2.1b Token sparse stage uses ~943.7b With token TOP-K = 2048,lr ~7.3e-6 For the main model.
Instantiation: DSA is already here MLA (Potential attention of bulls) MQA mode For decoding, therefore each potential KV entry is shared on the query header and is aligned with kernel-level requirements, i.e. reusing the KV entry in the query for throughput.
Let’s talk about its efficiency and accuracy
- Cost and location (128K): DeepSeek provides cost curve per million pounds Pre-filled and decoding exist H800 Cluster (reference price $2/gpu hour). The decoding cost of DSA is greatly reduced; pre-filling can also benefit from short-length masked MHA simulations. While the exact 83% of the numbers radiate to the social media map~6× Cheap Decoding 128K“see it as DeepSeek reported Until the third party replication lands.
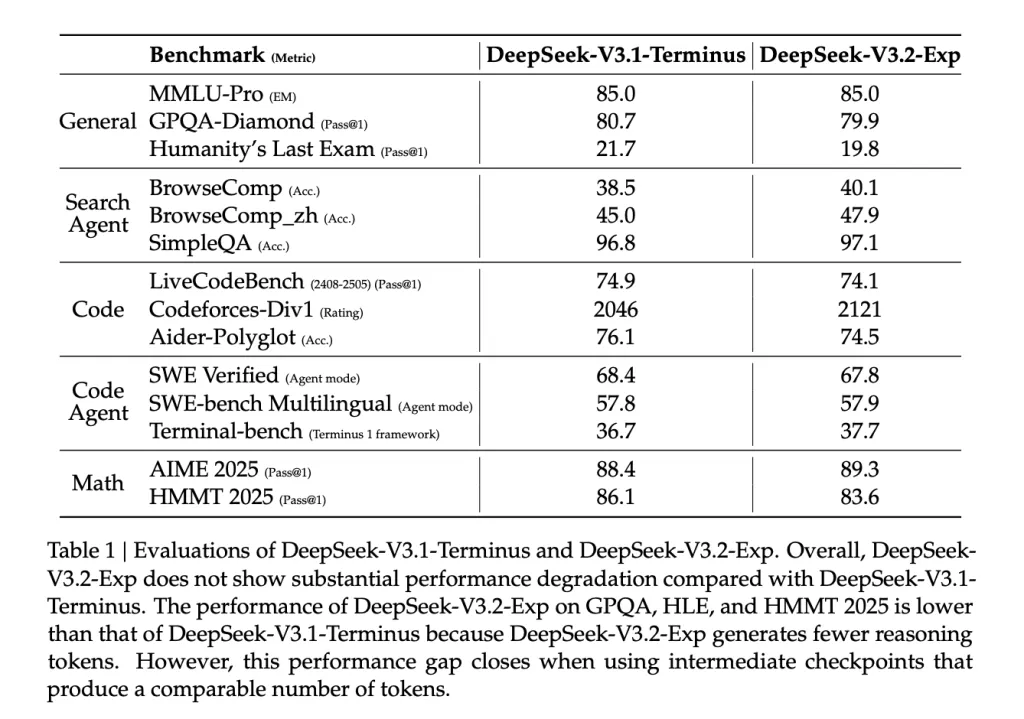
- Benchmark parity: Posted table display mmlu-pro = 85.0 (Unchanged), small actions on GPQA/HLE/HMMT due to fewer inference tokens and flat/positive movements to proxy/search tasks (e.g., BrowseComp 40.1 vs 38.5). The authors noticed that the gap when using intermediate checkpoints is closed, resulting in comparable token counts.
- Operation signal: Day 0 Support sglang and vllm It is recommended that kernel and scheduler changes are produced, not just studied. DeepSeek also reference Tilelang,,,,, deepgemm (index logits) and flashmla (Sparse kernel) is used in open source kernel.
- Pricing: DeepSeek says API prices are reduced 50%+consistent with model card messaging about efficiency, and this version targets lower novel reasoning economics.
Summary
DeepSeek v3.2-exp shows that trainable sparseness (DSA) can maintain benchmark equilibrium while essentially improving long-standing economics: Official documentation is dedicated to 50%+ API price reductionand Day-0 runtime support Already available, community threads claim greater decoding time benefits 128K This guarantees independent replication under matching batch and cache policies. The team’s recent gains are simple: Think of v3.2-exp as a rag and long-term document pipeline inserted into a/b, where o(l2)o(l2)o(l^2)o(l2)o(l2)o(l2)o(l2)o(l2) and validate end-to-end throughput/quality on the stack.
FAQ
1) What exactly is DeepSeek v3.2-exp?
v3.2-exp is a Experiment, middle Updated the v3.1 end and introduced DeepSeek sparse attention (DSA) to improve the efficiency of novels.
2) Is it truly open source?
Yes. Repository and model weights are MITaccording to the official hug facial model card (licensed part).
3) What is sparse attention (DSA) in practice?
DSA adds a lightweight indexing phase to score/select a small portion of related tokens, then pay attention only on that subset, and provides “fine-grained sparse attention” and reports long-term training/inference efficiency improvements while maintaining the output quality of v3.1.
Check Github page and Embrace Facial Model Card. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


