DeepReinforce team introduces CUDA-L1: Automatic reinforcement learning (RL) CUDA optimization framework unlocks 3x power from GPU
Estimated reading time: 6 minute
AI has just untied three times the power from the GPU without anyone intervening. Deepreinforce Team A new framework called CUDA-L1 Average provided 3.12×speed Then 120× Peak Acceleration In 250 real worlds, GPU tasks. It’s more than just an academic commitment: every result can be copied using open source code through widely used NVIDIA hardware.
Breakthrough: Reinforced learning for contrast (contrast is rl)
At the heart of CUDA-L1 is the main leap in AI learning strategies: Contrast enhanced learning (contrast-RL). Unlike traditional RL, AI is just generating solutions, getting numerical rewards and blindly updating its model parameters, contrast RL Feed performance scores and previous variants directly into the next generation tips.
- Performance scores and code variants are given to AI In each optimization round.
- Then it must Write “performance analysis” in natural language– Reflect which code is the fastest, Whyand which strategies have led to acceleration.
- Each step forces complex reasoning, guides the model not only to synthesize new code variants, but also to integrate more generalized, data-driven psychological models that make CUDA code faster.
result? AI Discovery is not only a well-known optimizationbut also Less obvious tricks Even human experts often overlook it – including mathematical shortcuts that bypass computing completely, or memory strategies that adjust to specific hardware quirks.
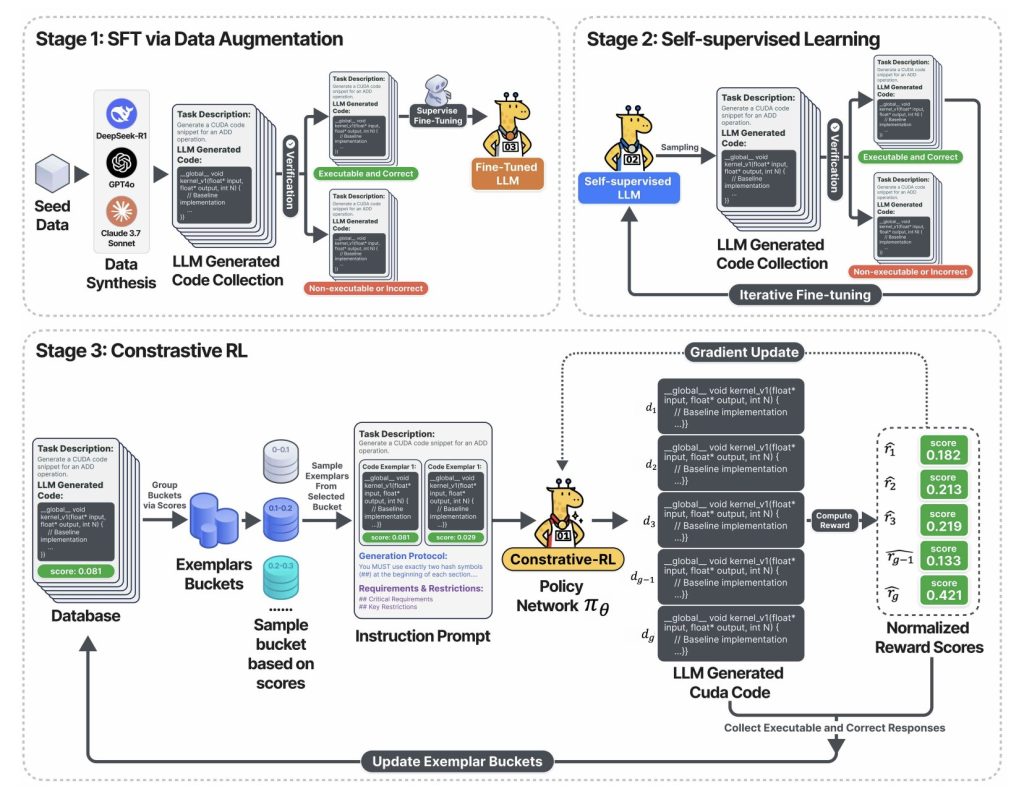
The image above captured Three-stage training pipeline:
- Stage 1: LLM is fine-tuned using proven CUDA code – sampled through leading base models (DeepSeek-R1, GPT-4O, Claude, etc.), but only the correct and executable output is preserved.
- Phase 2: The model enters a self-training loop: it generates a lot of CUDA code, retains only the functional code, and uses this code for further learning. Results: Quick improvement in code correctness and coverage – no manual marking for everyone.
- Stage 3: exist Contrast phasethe system sampled multiple code variants, displayed each code variant at its measurement speed, and challenged AI to debate, analyze and previous generations, and then proceeded to the next round of optimization. This reflection and improvement cycle is the key flywheel that provides huge acceleration.
How good is CUDA-L1? Hard data
accelerate
Kernel– Gold standard benchmark for GPU code generation (250 real-world Pytorch workloads) – for measuring CUDA-L1:
| Model/Stage | avg. accelerate | Maximum acceleration | Median | Success rate |
|---|---|---|---|---|
| Vanilla Camel-3.1-405b | 0.23× | 3.14× | 0× | 68/250 |
| DeepSeek-r1 (RL-Tuned) | 1.41× | 44.2× | 1.17× | 248/250 |
| CUDA-L1 (all stages) | 3.12× | 120× | 1.42× | 249/250 |
- 3.12×Average Speed: AI has found improvements on almost every task.
- 120×Maximum acceleration: Some computational bottlenecks and inefficient codes (such as diagonal matrix multiplication) are transformed by fundamentally excellent solutions.
- Work across hardware: Keep code optimized on NVIDIA A100 GPU Great benefits Ported to other architectures (L40, H100, RTX 3090, H20), with average speed 2.37× to 3.12×The median always grows above 1.1 times across all devices.
Case Study: Discover Hidden 64× and 120x Speed
Diag(a) * b – Diagonal matrix multiplication
- Reference (inefficiency):
torch.diag(A) @ BBuilding a complete diagonal matrix requires O(N²M) computing/memory. - CUDA-L1 optimization:
A.unsqueeze(1) * BUsing broadcasting, only O(NM) complexity is achieved –Causes 64×speed. - Why: AI believes that allocating a complete diagonal is unnecessary; this insight cannot be achieved through brute force mutations, but surfaces through comparative reflections across generated solutions.
3D transposed convolution-120× faster
- Original code: Complete convolution, summary and activation are performed – even if all zeros are guaranteed mathematically on input or hyperparameters.
- Optimization code: “Mathematical Short Circuit” used – Discover the given
min_value=0the output can be set to zero immediately, Bypass all computes and memory allocations. This insight is delivered Order of magnitude Faster than hardware-level micro-limiting.
Business Impact: Why This Is Important
For business leaders
- Direct cost savings: Every 1% speed in GPU workload reduces cloud GPUSECOND by 1% with lower energy costs and more model throughput. Here, AI delivery is average More than 200% of the additional calculations come from the same hardware investment.
- Faster product cycles: Automation optimization reduces the need for CUDA experts. Teams can release performance improvements in hours rather than months and focus on functionality and research speed, rather than low-level tweaks.
For AI practitioners
- Verified open source: All 250 optimized CUDA cores are open source. You can test the speed growth in A100, H100, L40, or 3090 GPUs without trust.
- No CUDA black magic required: The process does not rely on Secret Sauce, proprietary compiler, or loop tweaks.
For AI researchers
- Domain reasoning blueprint: Comparative RL provides a new way to train AI in domains of correctness and performance (not just natural language).
- Reward Hackers: The authors delve into how AI can detect subtle exploits and “cheating” (such as the speed of asynchronous flow manipulation errors) and outline reliable programs to detect and prevent such behavior.
Technical Insights: Why Comparative RL Wins
- Performance Feedback is now an article: Unlike Vanilla RL, AI can not only learn through trial and error, but also through Rational self-evaluation.
- Self-improvement flywheel: Reflection loops make the model reliable to reward the game and outperform evolutionary methods (fixed parameters, intrinsic contrast learning) and traditional RL (blind strategy gradient).
- Summary and discover basic principles: AI can combine, rank and apply key optimization strategies such as memory merging, thread block configuration, operational fusion, shared memory reuse, distortion level reduction and mathematical equivalent conversion.
Table: The highest technology found in CUDA-L1
| Optimization technology | Typical acceleration | Sample Insights |
|---|---|---|
| Memory layout optimization | Consistent improvement | Cache-efficient continuous memory/storage |
| Memory access (merge, share) | Moderate to high | Avoid bank conflicts and maximize bandwidth |
| Operational Fusion | High-level OPS | Fused multi-core kernel reduces memory read/write |
| Mathematical short circuit | Extremely high (10-100×) | Detect when the calculation can be completely skipped |
| Thread block/parallel configuration | Easing | Adapt to block size/shape to hardware/tasks |
| Warp-level/branchless reduction | Easing | Reduce differences and synchronization overhead |
| Register/Shared Memory Optimization | Medium-high | Caches frequently close calculations for data |
| Asynchronous execution, minimal synchronization | Various | Overlapping I/O, enabling pipeline computing |
Conclusion: AI is now its own optimization engineer
Using CUDA-L1, AI has Become your own performance engineeraccelerate research productivity and hardware returns – does not rely on rare human expertise. The result is not only a higher benchmark, but also a blueprint for AI systems Teach yourself how to leverage the full potential of the hardware you run.
AI is now building its own flywheel: more efficient, more insightful, and better able to provide the resources we provide for science, industry and beyond.
Check Paper,,,,, Code and Project page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.



