DeepAgent: Deep reasoning artificial intelligence agent that performs autonomous thinking, tool discovery and action execution in a single reasoning process
Most agent frameworks still run a predefined Reason, Act, Observe loop, so agents can only use tools injected in the prompt. This works fine for small tasks, but it fails when the toolset is large, the task is long, and the agent must change policy during inference. Proposed by the Renmin University of China and Xiaohongshu team Deep mugwortAs an end-to-end deep reasoning agent, keeping all of this in a coherent reasoning process.
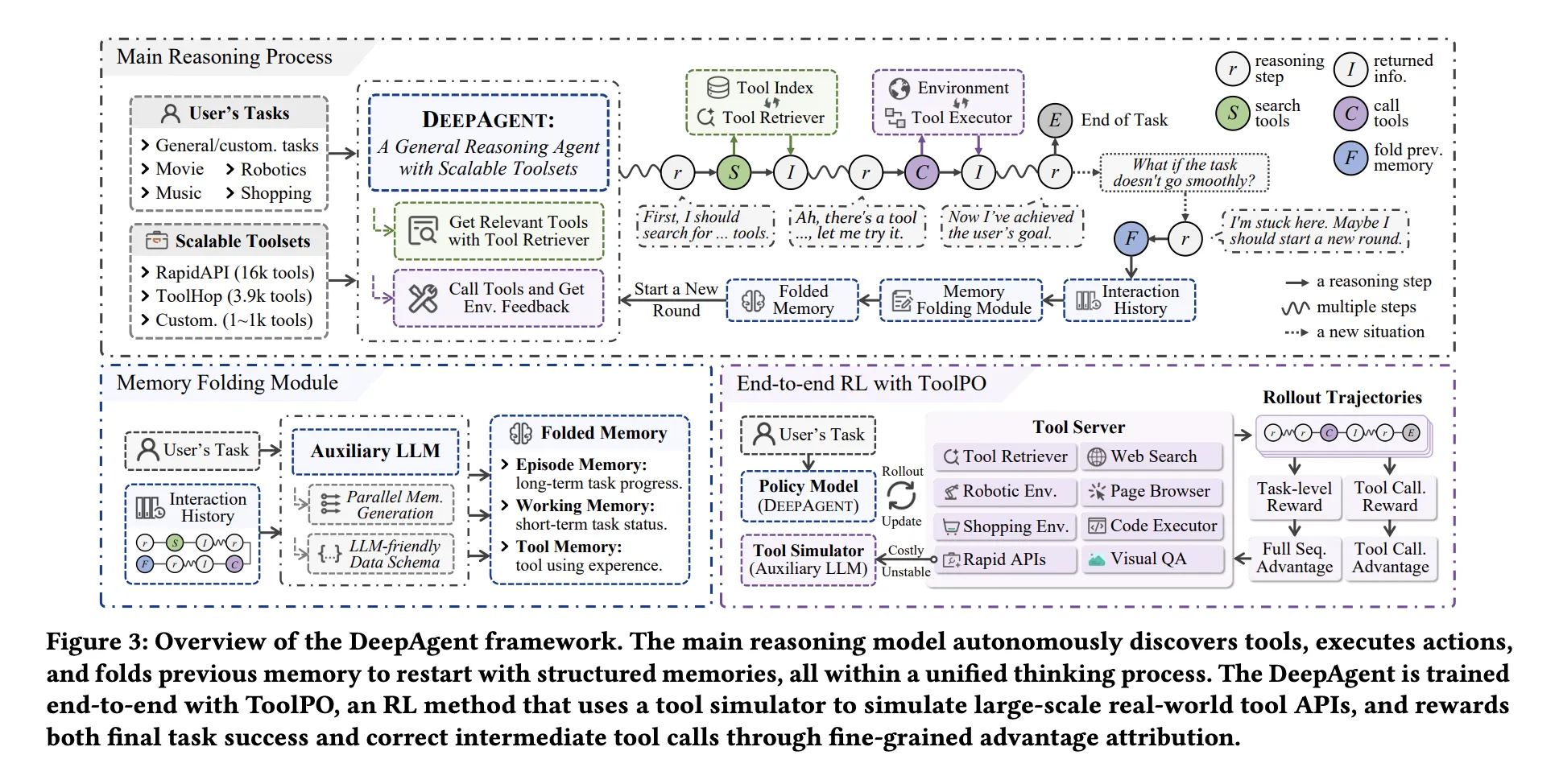
Unified reasoning with on-demand tool discovery
DeepAgent allows the model to directly output four action types: text, internal thinking, tool search, tool invocation, and memory folding. When the agent decides to search, it queries a dense index containing tool descriptions from a large registry, such as more than 16,000 RapidAPI tools and 3,912 ToolHop tools, and then it receives only the highest-ranked tool in the context. This makes tool access dynamic, the model does not depend on the list of tools loaded on the front end, and it is consistent with the real environment of tool changes.
Autonomous memory folding for long-term tasks
Long sequences of tool calls, web results, and code responses will overflow the context. DeepAgent solves this problem through an autonomous memory folding step. When the model emits a collapse token, the auxiliary LLM compresses the complete history into three memories: contextual memory that records task events, working memory that records current subgoals and recent issues, and tool memory that records tool names, parameters, and results. These memories are fed back in the form of structured text, so the agent continues from a compact but information-rich state.
ToolPO, reinforcement learning for tool usage
Supervised tracing does not teach robust tool usage because the correct tool calls are only a few tokens in the long generation. Research team introduction Tool strategy optimization, ToolPOsolve this problem. ToolPO runs deployments on the LLM simulation API, so training is stable and cheap, then it attributes rewards to the exact tool call token, which is tool call advantage attribution, and it trains using pruned PPO style targets. This is how the agent not only learns to call tools, but also decides when to search and when to collapse memory.
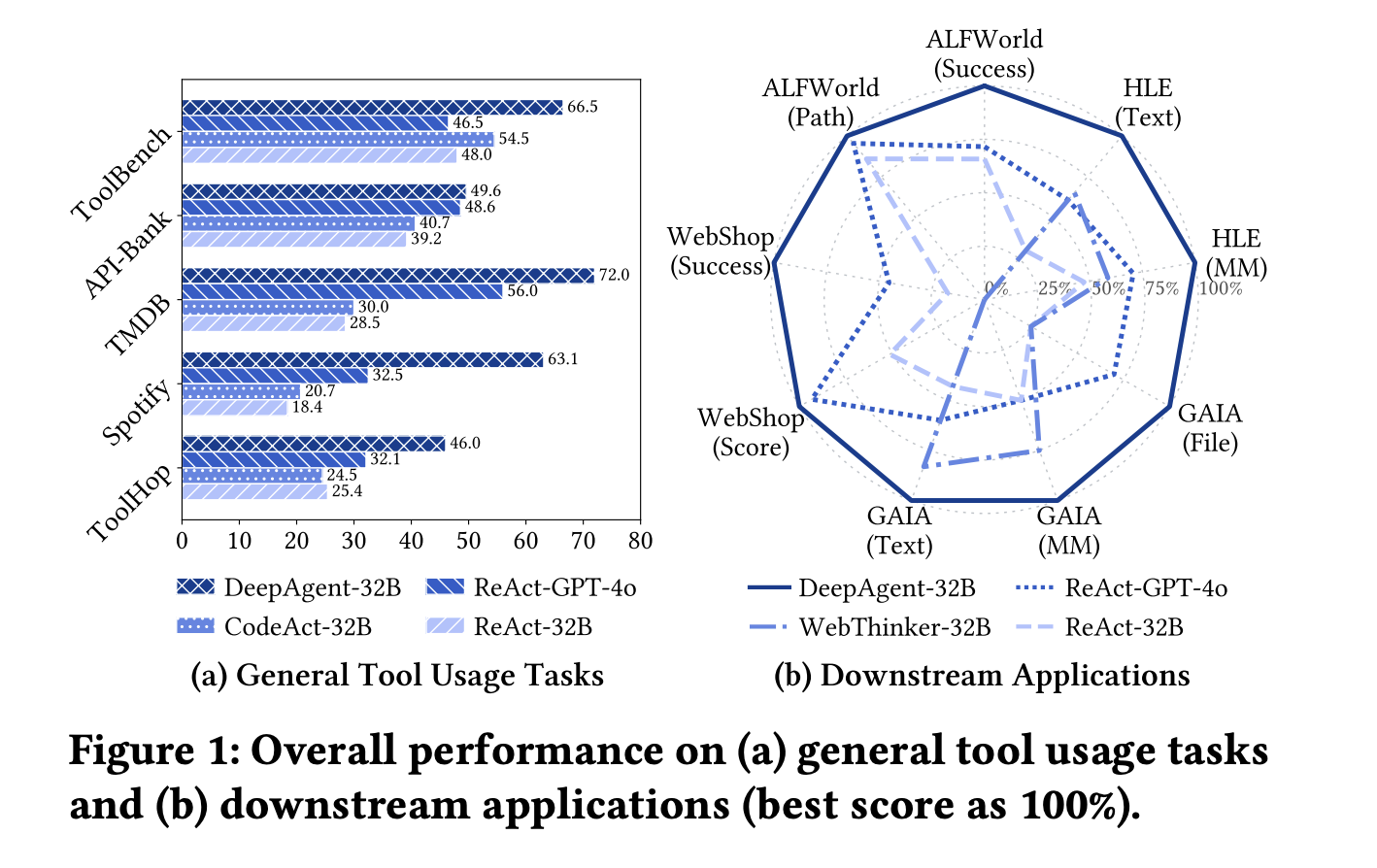
Benchmarks, Marking Tools, and Open Set Tools
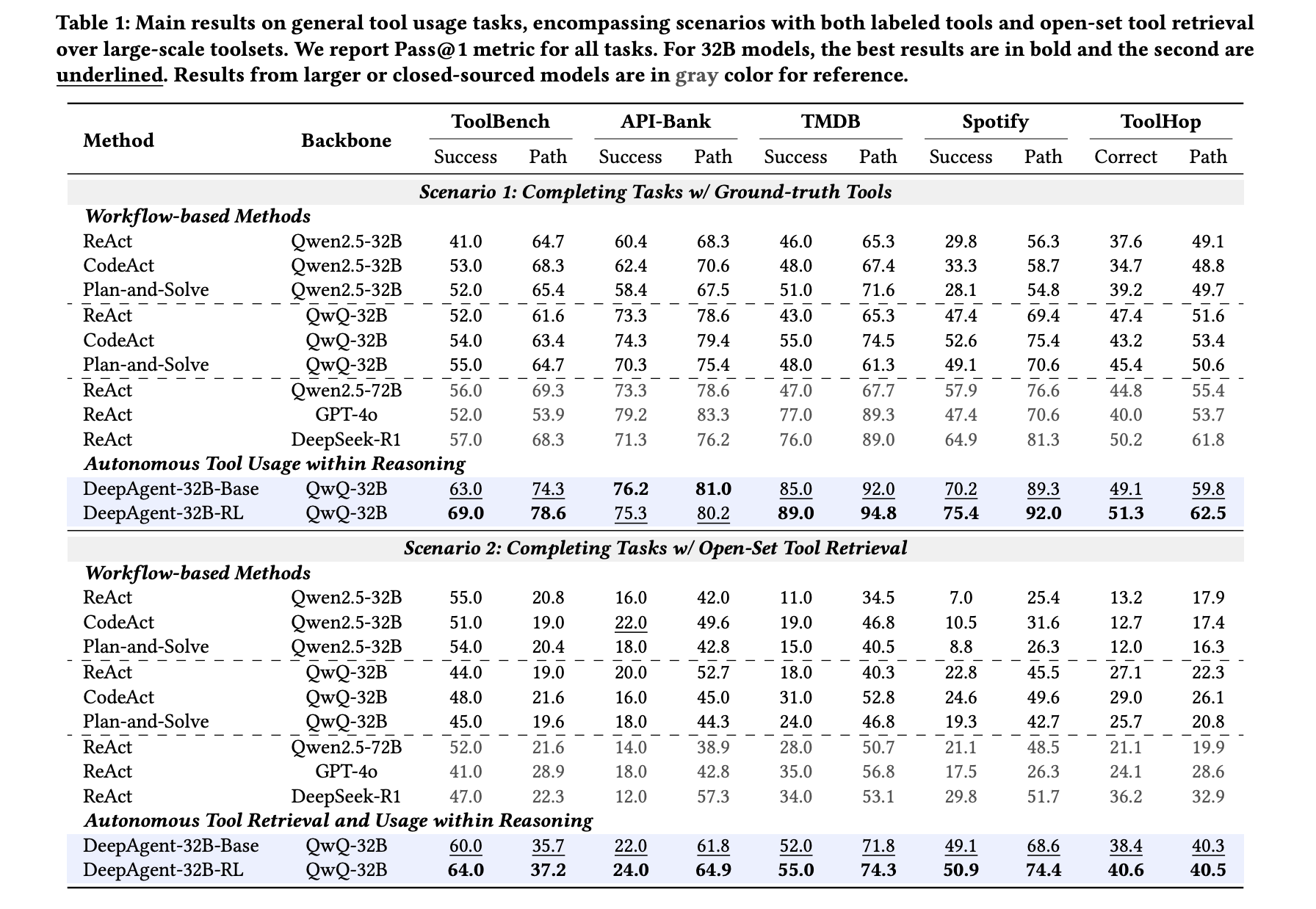
The research team evaluated 5 common tool usage benchmarks (ToolBench, API Bank, TMDB, Spotify, ToolHop) and 4 downstream tasks (ALFWorld, WebShop, GAIA, HLE). In the labeled tool settings, each method got the exact tools it needed, with DeepAgent 32B RL with QwQ 32B backbone reporting 69.0 on ToolBench, 75.3 on API Bank, 89.0 on TMDB, 75.4 on Spotify, and 51.3 on ToolHop, which was the strongest 32B level result across all 5 datasets. Workflow baselines such as ReAct and CodeAct can match a single dataset, e.g. ReAct with strong models is high on both TMDB and Spotify, but none remains high on all 5 datasets, so a fair summary is that DeepAgent is more uniform while others are always low.
In a realistic open-set retrieval setting, DeepAgent must first find tools and then invoke them. Here, DeepAgent 32B RL reaches 64.0 on ToolBench and 40.6 on ToolHop, while the strongest workflow baseline reaches 55.0 on ToolBench and 36.2 on ToolHop, so the end-to-end agent still maintains the lead. The research team also showed that autonomous tool retrieval itself improved the performance of the workflow agent, but DeepAgent gained more, confirming that the architecture and training are suitable for large toolsets.
downstream environment
On ALFWorld, WebShop, GAIA and HLE (all using 32B inference model), DeepAgent has a success rate of 91.8% on ALFWorld, a success rate of 34.4% on WebShop, and a score of 56.3. It scores 53.3 on GAIA and scores higher than the workflow agent on HLE. These tasks are longer and noisier, so the combination of memory folding and ToolPO may be the source of the gap.
Main points
- DeepAgent keeps the entire agent loop in an inference flow, where the model can think, search for tools, invoke them and continue, so it’s not limited to a fixed ReAct-style workflow.
- It performs intensive crawling of a large tool registry, more than 16,000 RapidAPI tools, and approximately 3,900 ToolHop tools, so tools are not prelisted in prompts but are discovered on demand.
- The autonomous memory folding module compresses long interaction history into episodic memory, working memory, and instrumental memory, thereby preventing context overflow and maintaining the stability of long-view reasoning.
- Tool Policy Optimization ToolPO trains tool usage end-to-end by simulating APIs and token-level advantage attribution, so agents learn to make the correct tool calls, not just arrive at the final answer.
- Across 5 tool benchmarks and 4 downstream tasks, DeepAgent at 32B scale is more consistent than the workflow baseline in the labeling tool and open set settings, especially on ToolBench and ToolHop where tool discovery is most important.
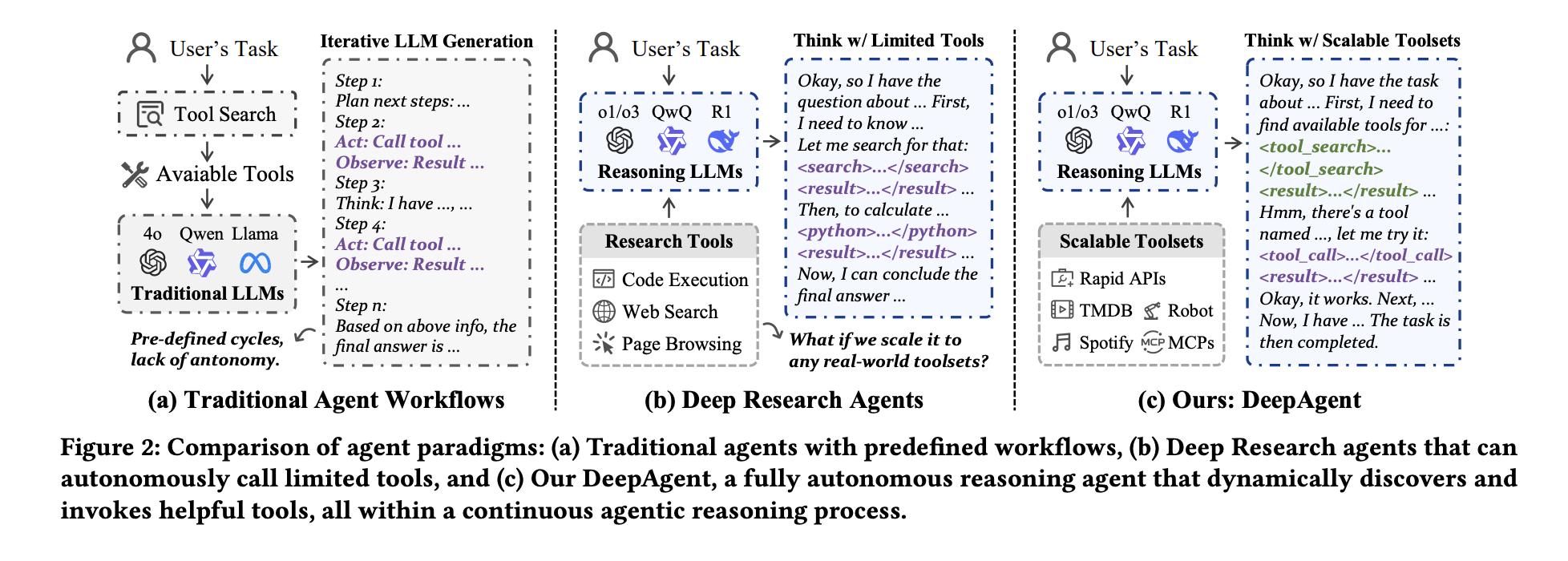
DeepAgent is a practical step towards an agent architecture that does not rely on fixed tooltips, as it unifies autonomous thinking, intensive tool retrieval of over 16,000 RapidAPI and 3,900+ ToolHop tools, structured tool invocation and memory folding in a single loop. Using the LLM simulation API in ToolPO was an engineering choice, but it solved the latency and instability issues that marred previous tool agents. Evaluation results show consistent gain at the 32B level in the marker tool and open set settings, rather than an isolated peak. This release makes a large tool space actually available to LLM agents. Overall, DeepAgent confirms that end-to-end tooling agents with memory and reinforcement learning capabilities are becoming the default mode.
Check Paper and GitHub repository. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


