Candy clip: Scaling LLM test time calculations with natural parallel thinking to overcome tunnel vision in sequential reasoning
Why does the order LLM hit the bottleneck?
Traditionally, the test time calculation scaling rate in LLMS relies on extending a single inference path. Although this approach improves the limited range of reasoning, it performs quickly. Experiments with DeepSeek-R1-Distill-QWEN-1.5B show that an increased marking budget exceeds 32K (up to 128K) can achieve negligible improvement in accuracy. The bottleneck comes from Commitment of early tokensin which the initial error spreads throughout the entire chain of thought. This effect is called Tunnel Vision,,,,, It shows that the scaling problem is a methodology, not a basic limitation of model capacity.
How to diagnose tunnel vision?
The researchers quantify recovery capabilities by forcing the model to continue from error prefixes of different lengths (100-1600 tokens). As the prefix length increases, the monotonic accuracy decreases, indicating that once a defective trajectory is committed, the model cannot be restored, even if other computational budgets are given. This confirms that sequential scaling allocation is inefficient.
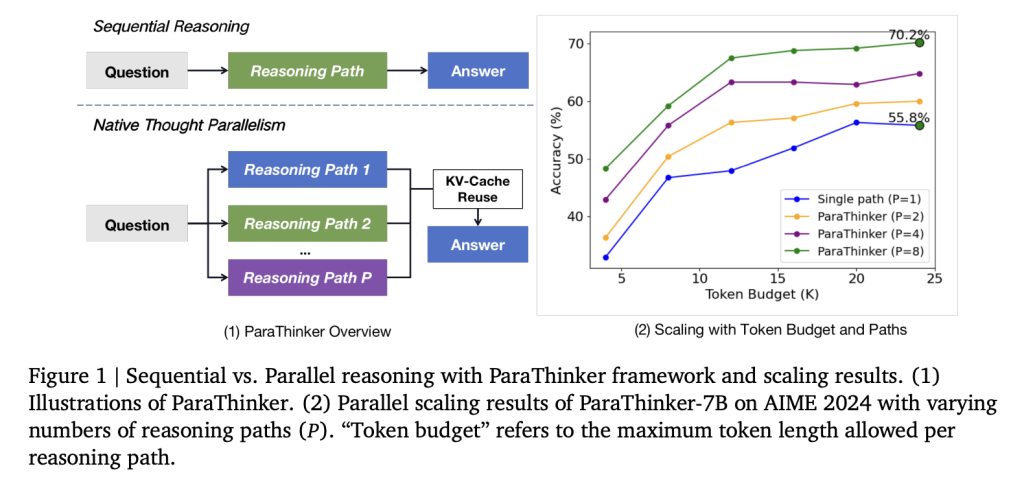
How does wrapping introduce parallel thinking?
A team of researchers at Tsinghua University introduced Atarathinker, an end-to-end framework that trains LLMs to generate multiple different inference paths in parallel and synthesizes them into higher final answers. Time Traveler Operation Local thought parallelism Generate multiple inference trajectories in parallel and merge them into the final response.
Key building components include:
- Specialized control tokens ((
- Ideas-specific position embedding Eliminate cross-border tokens and prevent crashes during the summary process.
- Pay attention to face masks in two stages Execution path independence during inference and control integration during answer generation.
Key efficiency improvements in reuse KV-CACHES Starting from the reasoning phase of the summary phase, redundant re-examination is eliminated.
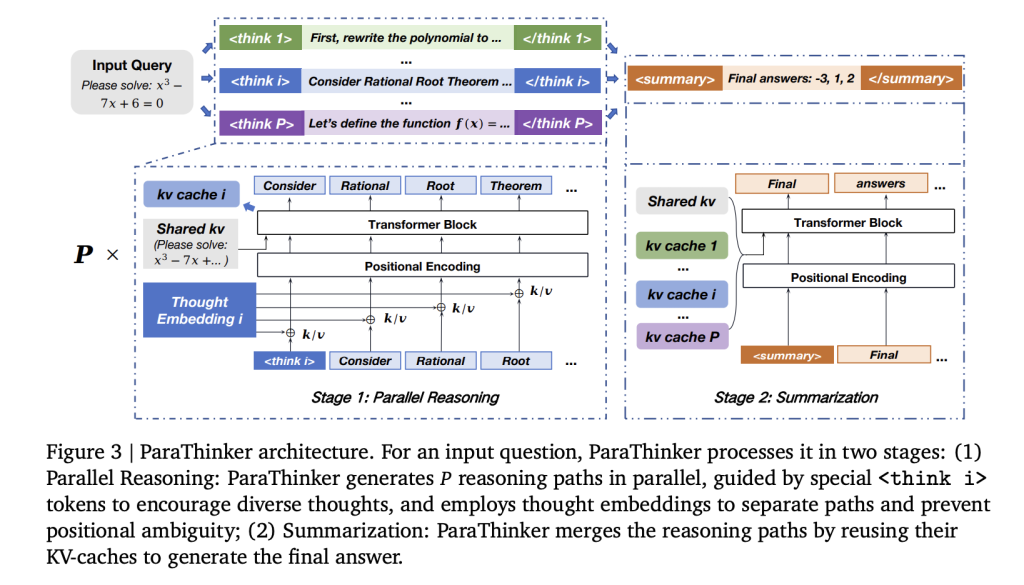
How to receive parallel reasoning training on packaging agents?
Supervised fine-tuning (SFT) was performed using a multi-channel inference dataset. The training data are constructed by sampling multiple solution paths of the teacher model (DeepSeek-R1, GPT-OSS-20B). Each example includes several
Fine-tuning uses QWEN-2.5 models (1.5b and 7b parameters) with a maximum context length of 28K tokens. Data sources include Open-R1, DeepMath, S1K and Limo, and other solutions sampled at temperature 0.8 were supplemented. Training on multiple A800 GPUs.
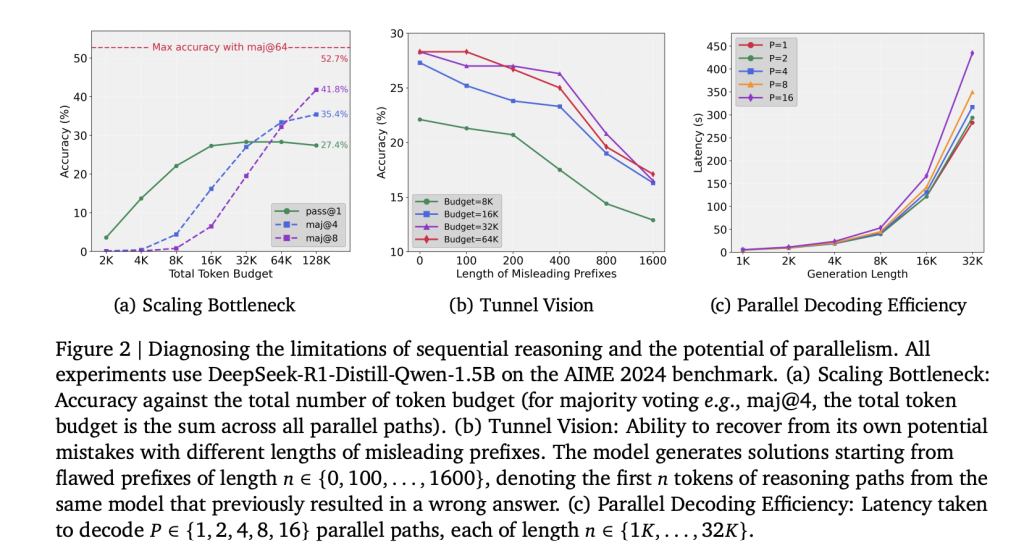
What are the experimental results?
Evaluations of AIME 2024, AIME 2025, AMC 2023 and MATH-500 result in the following:
- accuracy:
- The 1.5B wrapper has reached + Accuracy is 12.3% beyond the order baseline and +4.3% Most votes.
- 7b’s glycan knife has been realized +7.5% accuracy More than order and +2.0% Most votes.
- With 8 inference paths, Baoya Sugar 1.5b arrives 63.2% by @1with the same budget exceeding the continuous 7b model.
- efficiency:
- The delay overhead of parallel reasoning is 7.1% average.
- Generate 16 paths less than 2× latency of a single path is generated due to improved GPU memory utilization.
- Termination Policy: this first Methods, when the first path terminates, the inference ends, outperforms the last strategy and the semi-fine strategy in terms of accuracy and latency.
What does ablation studies show?
- Dataset fine-tuning only (No packaging modification) cannot improve performance, confirming the benefits gained from building innovation rather than training data alone.
- Remove thought embedding The accuracy is reduced, while naive flat encoding results in severe degradation due to long-term position attenuation.
- Re-examine the baseline The downgrade with the increase in the number of paths, validating the computational benefits of KV-CACHE reuse.
How does wrapping compare to other methods?
Traditional parallel strategies such as majority voting, self-contradictory and thought trees require external validators or post-fact selection, thus limiting scalability. Due to sequential dependency, diffusion-based token parallel approaches have poor performance on inference tasks. Construction methods such as Parscale requirements structural changes and pretreatment. In contrast, the wrapper retains the transformer backbone and introduces parallelism at the inference stage, integrating multiple KV-Caches into a unified summary step.
Summary
Candy clips show that the test time scaling bottleneck is an artifact of sequential reasoning strategies. Calculate by allocation width (parallel trajectory) instead depth (Length chain), smaller models can outperform larger baselines, with minimal delays. This is established Local thought parallelism As a key dimension for future LLM expansion.
Check The paper is here. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


