Apple researchers introduce FASTVLM: Implementing state-of-the-art solutions in visual language models – a trade-off for legal accuracy
The Visual Language Model (VLM) allows text input and visual comprehension. However, image resolution is critical to the VLM performance of processing text and chart-rich data. Increasing image resolution can pose significant challenges. First, pre-aesthetic vision encoders often encounter difficulties with high-resolution images due to inefficiency in pre-processing requirements. Inferred inferences on high-resolution images increase computational cost and latency during visual token generation, whether through a single high-resolution processing or multiple down-resolution tile strategies. Second, high-resolution images produce more tokens, which leads to the time of LLM pre-filling time and time (TTFT), which is the sum of the visual encoder latency and LLM pre-filling time.
Large multimodels (such as freezing and Florence) combine images and text in the intermediate LLM layer using cross-notes. Automatic regression architectures such as LLAVA, MPLUG-OWL, MINIGPT-4 and CAMBRIAN-1 are effective. For efficient image encoding, clip prophecy visual transformers are still widely adopted, with variants such as siglip, eva-clip, intentvit and dfnclip. Llava-Prumerge and Matryoshka-based token sampling methods such as dynamic token pruning, while hierarchical skeletons such as Convnext and FastVit reduce token counts through progressive down sampling. Recently, Convlava was introduced, which encodes images of VLM using a pure lateral vision encoder.
Apple researchers proposed FASTVLM, a model that implements an optimized trade-off between resolution, latency and accuracy by analyzing how image quality, processing time, token number and LLM size affect each other. It takes advantage of FastVithD, a hybrid vision encoder designed to output fewer tokens and reduce encoding time for high-resolution images. FASTVLM achieves the best balance between visual token counting and image resolution by scaling the input image only. It shows 3.2x the TTFT in the LLAVA1.5 setting and achieves superior performance on key benchmarks using the same 0.5B LLM compared to using Llava-onevision at maximum resolution. When using a smaller vision encoder, it can provide 85 times the TTFT.
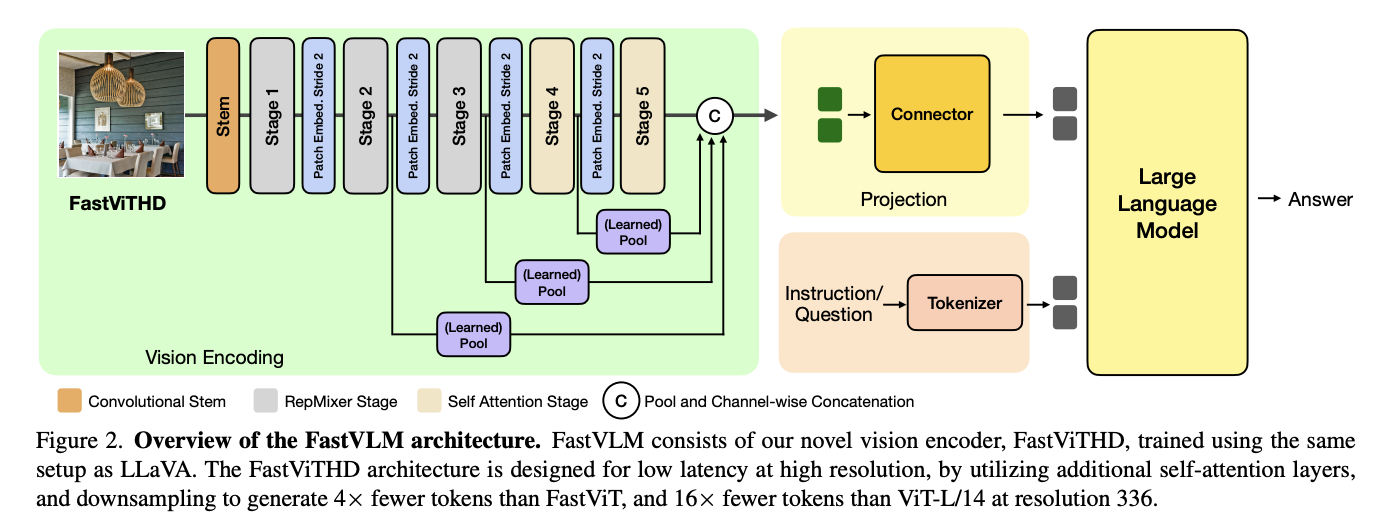
All FASTVLM models were trained on a single node with 8 NVIDIA H100-80GB GPUs, with the VLM’s Phase 1 training fast and taking about 30 minutes to train with the QWEN2-7B decoder. Additionally, FastVithD enhances the basic FastVit architecture by introducing an additional stage with a downsampling layer. This ensures the effect of self-occurrence, downsampling 32x instead of 16 in tensors, reducing the encoding delayed image while generating 4x tokens for the LLM decoder. The FastVithD architecture consists of five stages: the first three stages utilize turner blocks for effective processing, while the last two stages employ multi-head self-attention blocks, creating the best balance between computational efficiency and high-resolution image understanding.
FastVLM has 8.4% performance improvement on TextVQA compared to Convlava, and 12.5% performance improvement on textVQA when running at 22% faster. Performance advantages increase at higher resolutions, where FASTVLM’s processing speed is maintained at 2× faster than in Convlava for various benchmarks. FASTVLM uses intermediate pretreatment with 15m samples for resolution scaling, matching or exceeding MM1 performance in different benchmarks, while generating 5 times fewer visual tokens. In addition, FastVLM not only outperforms Cambrian-1, but also 7.9 times faster. With the scaling instruction tweak, it can provide better results while using 2.3x visual tokens.

In short, the researchers introduced FASTVLM, an advancement in VLM by leveraging the FastVithD visual backbone for efficient high-resolution image encoding. Compared to existing methods, a hybrid architecture estimated on enhanced image text data can reduce visual token output while maintaining minimal accuracy sacrifice. FASTVLM achieves competitive performance in VLM benchmarks, while improving efficiency in both TTFT and visual backbone parameter counting. Strict benchmarks on the M1 MacBook Pro hardware show that FastVLM provides the most advanced solution for latency-accuracy tradeoffs, while outperforming the current approach.
Check Paper. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
You may also like NVIDIA’s open source cosmic diffuser [Check it now]

Sajjad Ansari is a final year undergraduate student from IIT Kharagpur. As a technology enthusiast, he delves into the practical application of AI, focusing on understanding AI technology and its real-world impact. He aims to express complex AI concepts in a clear and easy way.



 brings 32B LLM training to a single H100 while improving exploration")