Ant Group releases Ling 2.0: a series of reasoning-first MoE language models based on the principle of enhancing reasoning capabilities with each activation
How to build a language model whose capacity keeps growing but the amount of computation per token is almost constant? Ant Group’s Inclusion AI team is methodically advancing sparse large-scale models by releasing Ling 2.0. Ling 2.0 is a family of inference-based language models based on the idea that every activation should translate directly into stronger inference behavior. It is one of the latest approaches that shows how to keep activations small while migrating from 16B to 1T without having to rewrite the recipe. There are three versions of this series, Ling mini 2.0 with a total of 16B and activation of 1.4B; Ling flash 2.0 100B level with 6.1B of activation; Ling 1T with a total of 1T and activation of about 50B per token.
Designed with sparse MoE as the center
Each Ling 2.0 model uses the same sparse expert blending layer. Each layer has 256 routing experts and one shared expert. The router selects 8 routing experts for each token, and shared experts are always on, so each token uses about 9 of the 257 experts, which is about a 3.5% activation rate, matching the 1/32 activation rate. The research team reports an approximately 7x improvement in efficiency compared to equivalently dense models, as each token trains and serves only a small portion of the network while maintaining a very large parameter pool.
Ling 2.0 brings coordinated advancements at four layers of the stack, model architecture, pre-training, post-training, and underlying FP8 infrastructure:
Model architecture: The architecture was chosen using Ling Scaling Laws rather than through trial and error. To support Ling Scaling Laws, the team ran what they called the Ling Wind Tunnel, a fixed set of small MoEs trained on the same data and routing rules, then adapted to power laws to predict losses, activations, and expert balance at larger scales. This gives them a low-cost way to choose 1/32 activations, 256 routing experts, and 1 shared expert before committing to GPUs at 1T scale. Routing is lossless with sigmoid scoring, and the stack uses QK Norm, MTP loss, and partial RoPE to maintain depth stability. Due to the same rules of shape selection, Ling mini 2.0, Ling flash 2.0 and Ling 1T can all maintain consistency in size.
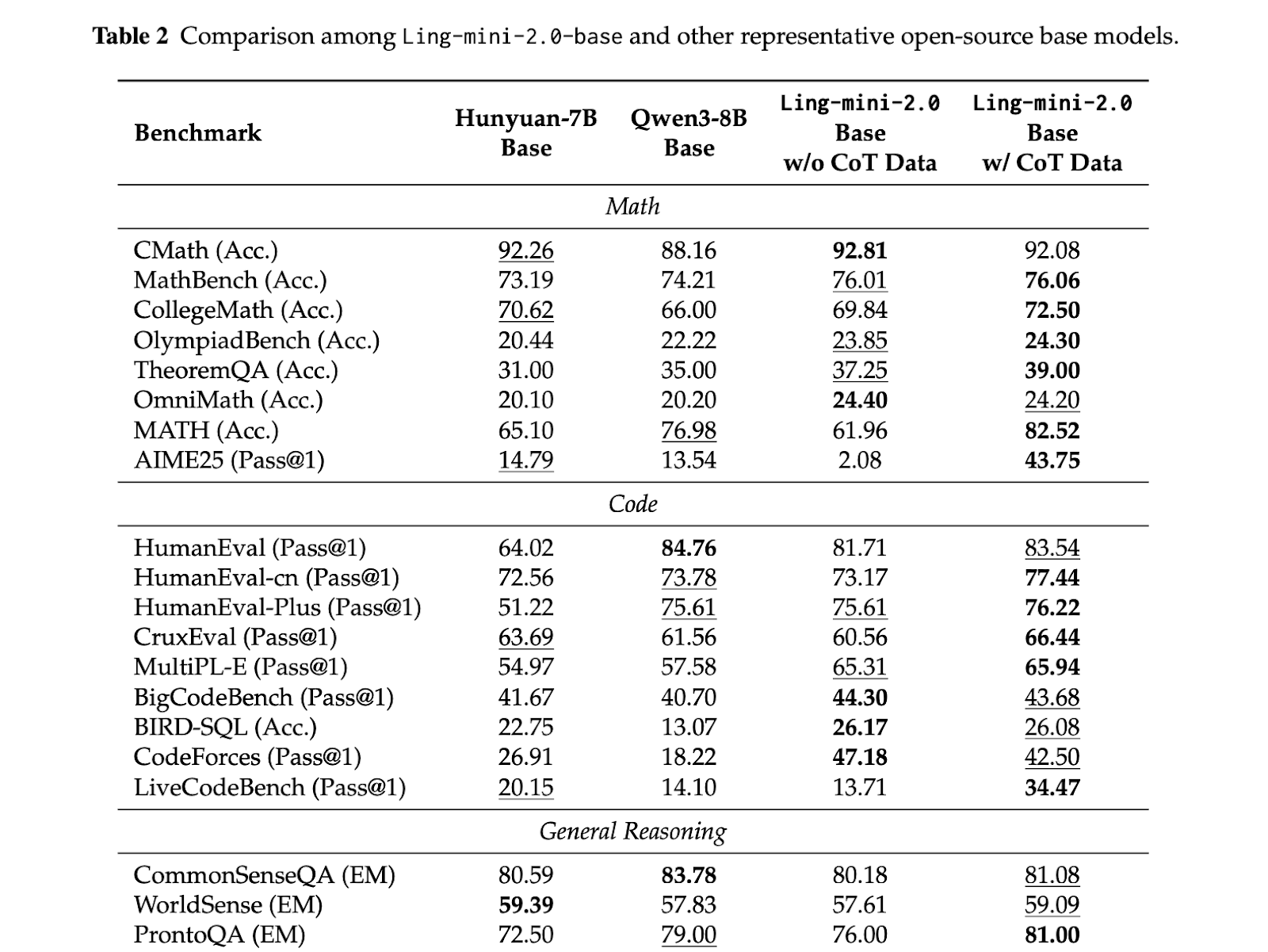
Pre-training: This series uses more than 20T tokens for training, starting with 4K context, using a mixture of reasoning-heavy resources such as mathematics and code, and gradually increasing to nearly half of the corpus. A later mid-training phase expands the context on a selected 150B token slice to approximately 32K, then injects another 600B tokens of high-quality thought chains, and finally expands to 128K using YaRN while preserving short context quality. This pipeline ensures that long context and reasoning are introduced early and not just added in the SFT step.
Job training: Alignment is divided into capability channels and preference channels. First, decoupled fine-tuning teaches the model to switch between fast response and deep reasoning through different system prompts, then the evolutionary CoT stage expands and diversifies the chain, and finally uses Group Arena Reward for sentence-level policy optimization to make the output consistent with human judgment at a fine-grained level. This staged tuning allows non-thinking fundamentals to achieve strong math, code, and instruction performance without exaggerating every answer.
Infrastructure: Ling 2.0 trains natively in FP8 with safeguards, keeping the loss curve within a small margin of BF16 while achieving ~15% utilization on the reported hardware. The larger speedup (approximately 40%) comes from heterogeneous pipeline parallelism, interleaved forward-backward execution, and MTP-block-aware partitioning, not just precision. Together with Warmup Stable Merge, which replaces LR decay by merging checkpoints, this system stack makes 1T scale feasible to run on existing clusters.
Understand the results
Evaluations are consistent across models, with small activation MoE models delivering competitive quality while keeping per-token computation low. Ling mini 2.0 has a total of 16B parameters, with 1.4B activated per token, and is reported to perform in the 7 to 8B dense band. (Reddit) Ling flash 2.0 keeps the same 1/32 activation recipe, with 100B and 6.1B activated per token. Ling 1T is the flagship non-thinking model with 1T total parameters and approximately 50B active volume per token, retaining 1/32 sparsity and scaling the same Ling scaling laws to trillions of scales.
Main points
- Ling 2.0 is built around a 1/32 active MoE architecture, selected using Ling scaling rules so that 256 routing experts plus 1 shared expert remain optimal in the 16B to 1T range.
- Ling mini 2.0 has a total of 16B parameters, 1.4B activation per token, and can reportedly match 7B to 8B dense models while generating over 300 tokens per second in simple QA on H20.
- Ling flash 2.0 maintains the same recipe, with 6.1B active parameters and sitting in the 100B range, offering higher capacity options without increasing per-token calculations.
- Ling 1T exposes the complete design, 1T total parameters, ~50B activities per token, 128K contexts, and Evo CoT plus LPO-style post-training stack to drive efficient inference.
- Across all scales, the combination of sparse activations, FP8 training, and shared training plans improves efficiency by more than 7x over dense baselines, so quality scales predictably without rescaling computation.
This release demonstrates the complete sparse MoE stack. Ling Scaling Laws identifies 1/32 activation as optimal, with this architecture locking in 256 routing experts plus 1 shared expert, and using the same shape from 16B to 1T. Training, context expansion, and preference optimizations are all aligned with this choice, so small activations don’t hinder math, code, or long context, and FP8 plus heterogeneous pipelines keep costs within realistic bounds. This is a clear signal that trillion-scale inference can be organized around fixed sparsity rather than increasing computational intensity.
Check Weighting of HF, Repurchase Agreements and Notes. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


