Andrej Karpathy releases “nanochat”: a minimal end-to-end ChatGPT style pipeline that you can train in ~4 hours for ~$100
Andrej Karpathy is open source nano chata compact, dependency-light codebase that implements the full ChatGPT-style stack (from tagger training to Web UI inference), designed for repeatable, hackable LLM training on a single multi-GPU node.
This repository provides a single script “speedrun” that performs the full cycle: tokenization, basic pre-training, mid-term training on chat/multiple choice/tool usage data, supervised fine-tuning (SFT), optional RL on GSM8K, evaluation and serving (CLI + ChatGPT-like web UI). The recommended settings are 8×H100 Node; at about $24/hour, a 4 hour run is close to $100. After running report.md Summary metrics (CORE, ARC-E/C, MMLU, GSM8K, HumanEval, ChatCORE).
Tokenizer and data path
- tokenizer: Custom Rust BPE (built with Maturin) with 65,536 token vocabulary; for training purposes FineWeb-EDU Fragmentation (repackage/shuffle for easier access). The walkthrough reports approximately 4.8 characters/token compression and compares to the GPT-2/4 token generator.
- Evaluation package:A carefully planned set nuclear (22 auto-complete data sets, such as HellaSwag, ARC, BoolQ, etc.), download to
~/.cache/nanochat/eval_bundle.
Models, scaling, and speedrunning goals
speedrun configuration training Depth 20 Transformer (~560M parameters, 1280 hidden channels, 10 attention heads, dim 128) ~11.2B tokens, consistent with Chinchilla-style scaling (parameters × ~20 tokens). The author estimates that this run ~4e19 FLOPs capability model. training purposes meson For matmul parameters and Adam W Used to embed/unembed; losses reported in Bits per byte (bpb) Is the tokenizer immutable.
Mid-training, SFT and tool usage
After pre-training, mid-training Adapt the base model to dialogue (SmolTalk) and explicitly teaches multiple choice behavior (100K MMLU assisted training problems) and Tool usage by inserting … Block; contains a small GSM8K slice for seed calculator-style use. Default mixture: SmolTalk (460K), MMLU auxiliary train(100K), GSM8K Master (8K),total 568K OK.
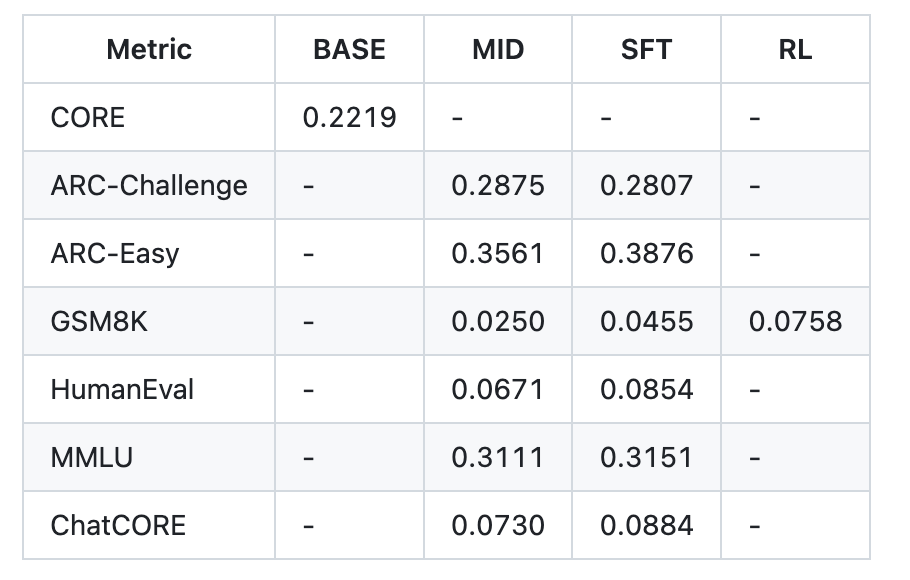
Fast Fourier Transform The dialogue is then fine-tuned for higher quality while matching the test-time format (padded non-connected rows) to reduce training/inference mismatch. Post-SFT metrics (speedrun layer) reporting example for a repository ARC-Easy 0.3876, ARC-Challenge 0.2807, MMLU 0.3151, GSM8K 0.0455, Human evaluation 0.0854, Chat Core 0.0884.
Tool usage is end-to-end: customization engine implement KV cache, Pre-fill/decode reasoning and simple Python interpreter Sandbox for tool enhancement runs – for training and evaluation processes.
Optional RL on GSM8K via simplified GRPO loop
Final (optional) stage applies reinforcement learning exist GSM8K with a Simplified GRPO conventional. This walkthrough clarifies what is omitted relative to the canonical PPO-style RLHF: no trust regions via the reference model, no KL penalty, policy updates (dropping PPO ratio/clip), token-level GAPO-style normalization and mean-shift advantage. In fact, it behaves close to strengthen while maintaining group related Advantage calculation. script scripts.chat_rl and scripts.chat_eval -i rl -a GSM8K Demonstration loop.
Cost/quality scaling and larger models
The readme outlines two larger goals for speedrunning beyond $100:
- ~$300 level: d=26 (about 12 hours), Slightly more than GPT-2 CORE; Requires more pre-training sharding and batch sizing.
- ~$1,000 level: About 41.6 hourssignificantly improves coherence and basic reasoning/encoding abilities.
The repository also notes previous experimental runs in which d=30 Model training takes about 24 hours to achieve 40 seconds on MMLU, 70s on ARC-Easy, 20 seconds on GSM8K.
Assessment Snapshot (Speedrun Level)
an example report.md The table shows this for about $100/about 4 hours of running: Core 0.2219 (base);Mid-training/after SFT, ARC-E 0.3561→0.3876, ARC-C ~0.2875→0.2807, MMLU 0.3111→0.3151, GSM8K 0.0250→0.0455, Human evaluation 0.0671 → 0.0854, Chat core 0.0730 → 0.0884; Wall clock 3h51m.
Main points
- nanochat is a minimal, end-to-end ChatGPT style stack (~8K LOC) via a single
speedrun.shOn an 8×H100 node (~4h ≈ $100). - The pipeline covers tokenizer (Rust BPE), basic pre-training, mid-term training, SFT, optional RL (simplified GRPO) on GSM8K, evaluation and serving (CLI + Web UI).
- Speed running metrics (example
report.md): Core 0.2219 base; after SFT — ARC-Easy 0.3876, ARC-Challenge 0.2807, MMLU 0.3151, GSM8K 0.0455, HumanEval 0.0854. - Extended Tier Overview: ~$300 (d=26, ~12h) for “slightly better than GPT-2 CORE”; ~$1,000 (~41.6 hours) for substantially better coherence/inference.
Kapati’s nano chat Falling in a useful middle ground: a single, clean, dependency-light repository that stitches tokenizer training (Rust BPE), pre-training on FineWeb-EDU, mid-training (SmolTalk/MMLU aux/GSM8K with tool usage tags), SFT, optional simplified GRPO on GSM8K, and thin engines (KV cache, pre-population/decoding, Python interpreter) into a reproducible Speed pass On 8×H100 nodes, traceable report.md Features CORE/ARC/MMLU/GSM8K/HumanEval and minimal Web UI.
Check technical details and code. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


