Amazon has developed an AI architecture that reduces inference time by only 30% by activating relevant neurons
Amazon researchers have developed a new AI architecture that selects only task-related neurons, reducing inference time by 30%, similar to how the brain uses professional areas to complete specific tasks. This breakthrough approach solves one of the biggest challenges facing large AI models: the computational expenses and delays associated with each neuron per request, regardless of their correlation.
Traditional deployment of large language models (LLM) and underlying AI systems rely on activation of a complete network per input. While this guarantees versatility, it can lead to significant inefficiency, the activity of the network is redundant for any given hint. Inspired by the efficiency of the human brain – the brain flexibly recruits the circuits required for a given cognitive task – Amasen’s architecture mimics this behavior by activating neurons most relevant to the current input context.
Dynamic, context-aware pruning

The core of this innovation is Dynamic, context-aware pruning. Amazon’s solution does not statically prune the model during training and locking these changes, but instead trim the network “instantly” in the process of inferring itself. This allows the model to remain large and universal, yet efficiently and quickly perform any specific task.
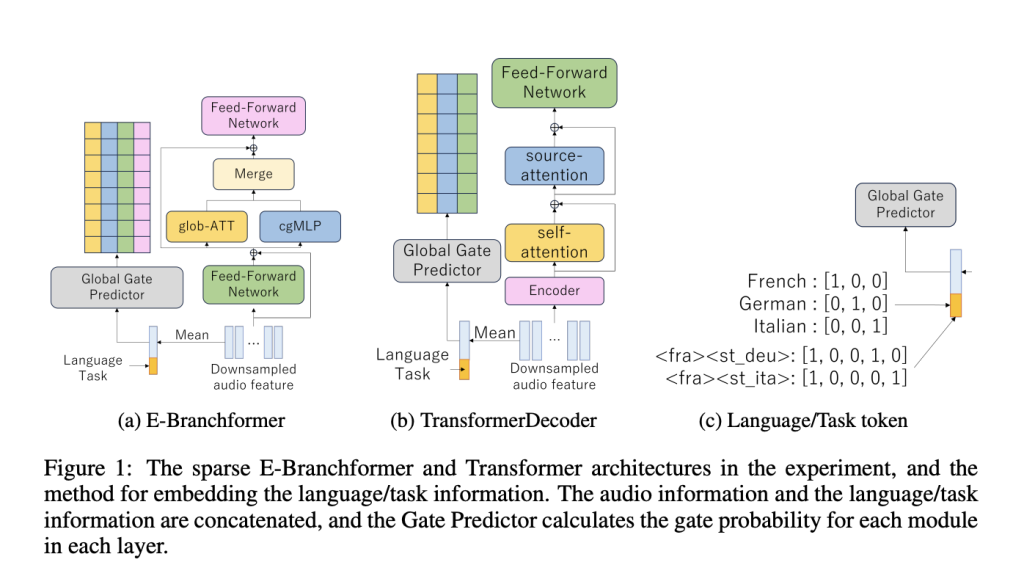
- Before processing input, the model evaluates which neurons or modules are most useful based on signals such as task type (e.g., legal writing, translation, or coding help), language, and other contextual functions.
- It uses a Door Predictora lightweight neural component that is trained to generate a “mask” that determines which neurons that particular sequence opens.
- Gated decisions are binary, so neurons are fully active or skipped completely, ensuring real computational savings.
How the system works
The architecture introduces Context-aware gating mechanism. This mechanism analyzes input functions (and for voice models, auxiliary information such as language and task tokens) to determine which modules (such as self-sending blocks, feed forward networks, or dedicated convolutions) are critical to the current step. For example, in a speech recognition task, it may activate the local context module for detailed sound analysis while skipping unnecessary components that are only beneficial to other tasks.
This pruning strategy is structured and modular: instead of eliminating a single weight (which may lead to hardware inefficiency), it skips the entire module or layer. This preserves the structural integrity of the model and ensures compatibility with GPUs and modern hardware accelerators.
The gate prediction model is trained in sparsity loss to achieve target sparsity: the proportion of modules skipped. Training uses techniques such as Gumbel-Softmax estimator to ensure that gating behaviors during optimization can still be differentiated, but ultimately produce clear, binary selection of neurons when reasoning.
Show results: Speed without sacrificing quality
Experiments show that dynamically skipping irrelevant modules can:
- Reduce inference time by up to 34% For multilingual speech-to-text or automatic speech recognition (ASR) tasks (latency of 9.28 for typical baseline models), the delay of the pruning model is up to 5.22s, depending on the task and the required sparsity.
- Reduce Flops (floating point operation) by more than 60% Under high sparsity, the cloud and hardware costs are greatly reduced.
- Maintain output quality: In particular, trim the decoder, which preserves the word error rate (WER) to moderate sparseness of BLEU scores (for translation tasks) and ASR, which means that users do not see a degradation in model performance before applying very aggressive pruning.
- Provides explanatory: Analysis of pruned module patterns reveals which parts of the model are for each context-local context modules dominate in ASR, while feedforward networks prioritize speech translation.
Task and language adaptation
The core insight is that the best pruning strategies (i.e., modules that are retained or skipped) can change dramatically based on tasks and language. For example:
- In ASR, the importance of local context modules (CGMLPs) is crucial, while the decoder can be sparse in large quantities with very little precision loss.
- For speech translation (ST), both the encoder and the decoder require more balanced attention, as the feed layer of the decoder is essential.
- In a multilingual or multitasking scheme, the module selects a pattern that adapts but displays consistent in each type, highlighting the specialization of learning in the architecture.
A broader meaning
This dynamic modular trim is:
- More energy-efficient, scalable AI – especially as LLM and multi-model development is crucial.
- AI models that can personalize their computing pathways – not only through tasks, but through user profiles, regions or devices.
- Wherever the underlying model is used, it can be transferred to other areas such as natural language processing and computer vision.
Amazon’s architecture, inspired by biological neural efficiency, selectively activates task-related modules only in real time, pointing to a powerful and practical AI path to global, real-world use.
Check Paper and Technical details. All credits for this study are to the researchers on the project. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Sajjad Ansari is a final year undergraduate student from IIT Kharagpur. As a technology enthusiast, he delves into the practical application of AI, focusing on understanding AI technology and its real-world impact. He aims to express complex AI concepts in a clear and easy way.

, implementing long, accurate and thoughtful reasoning")
: A new machine learning framework that optimizes multi-agent systems")