Alibaba releases Tongyi Deepresearch
Alibaba’s Tongyi Lab open source Tongyi-Deepresearch-30B-A3Ba large language model specialized in agents built for long distances, uses web tools to seek in-depth information. This model is designed using a mixture with experts (MOE) ~30.5b total parameters and ~3–3.3b each token activitywhile retaining strong inference performance, achieving high throughput. Its research workflow for multi-transformation – search, browse, extract, cross-check and synthesize evidence – in reactive tool usage and heavier test time scaling mode. This version includes weights (Apache-2.0), inference scripts, and evaluation utilities.
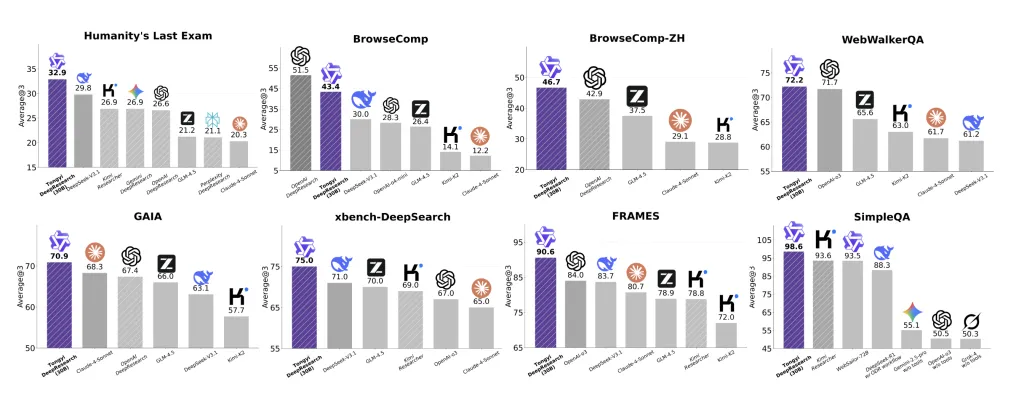
What is the benchmark displayed?
Tongyi Deepresearch Report State-of-the-art results for the Agent Search Suite Often used to test “deep research” agents:
- The Last Exam of Humanity (HLE): 32.9,,,,,
- BrowseComp: 43.4 (en) and 46.7 (ZH),
- Xbench-Deepsearch: 75,,,,,
Other powerful results have been achieved between WebWalkerQA, Gaia, Framework and SimpleQA. The team found that the system was Average to the in-depth research agent of Openai style and in these tasks “systematically surpass existing proprietary and open source agents.”
Architecture and reasoning information
- MUE Routing (QWEN3-MOE Lineage) and ≈30.5b Total/≈3.3b Activity Parameterswhile maintaining professional competence, give a small model of cost envelope.
- Context length: 128K tokensuitable for long-term tool-enhanced browsing meetings and iterative synthesis.
- Dual inference mode:
- reaction (Native) is used to directly evaluate the use of inherent reasoning and tools,
- IterResearch “heavy” mode Used to test time scaling and structured multiple rounds of synthesis/reconstruction of the context to reduce noise accumulation.
Training pipeline: Comprehensive data + policy RL
Tongyi Deepresearch end-to-end training agentnot only CHAT LLM using a fully automatic, scalable data engine:
- Agent Continuous Pre-training (CPT): Large-scale synthetic trajectories constructed from curated corpus, historical tool traces and graphical structure knowledge to teach retrieval, browsing and multi-source fusion.
- Proxy SFT cold start: Track reaction and IterResearch Format for architecture consistent planning and tool use.
- policy rl and Group Relative Policy Optimization (GRPO),,,,, Token level policy gradient,,,,, One-to-one advantage estimateand Negative sample filtering Stable learning in non-stationary network environments.
Role in Documentation and Web Research Workflow
The in-depth study task highlights four functions: (1) long-term planning, (2) iterative search and verification across sources, (3) evidence tracking with low hallucinations, and (4) synthesis in a large environment. this IterResearch Introduce each “round” context, only the basic artifact is preserved to alleviate context bloating and error propagation, while reaction Baselines indicate that these behaviors are learned rather than designed quickly. The reported scores on HLE and BrowseComp indicate that robustness is improved on multi-hop, tool-mediated queries where previous agents are often overfitted to hint patterns or saturate at low depths.
Main features of Tongyi Deepresearch-30b-A3B
- Large-scale MOE efficiency: The total parameters of ~30.5b are ~3.0–3.3b for each token activation (Qwen3-MoE lineage), giving small inference costs the capability of larger models.
- 128K context window: The launch of long-distance running and accumulated evidence of multi-step network research.
- Double reasoning example: The country’s reaction for intrinsic tool usage evaluation and IterResearch “heavy” (Test Time Scaling) for deeper multi-round synthesis.
- Automated Agent Data Engine: The fully automated synthesis pipeline is agent continuous pre-training (CPT), supervised fine-tuning (SFT) and RL.
- Do policy rl with grpo: Group relative policy optimization, with token-level policy gradients, retention advantage estimates, and selective negative sample filtering for stability.
- Reported SOTA that delves into suites: HLE 32.9, BrowseComp 43.4 (en)/46.7 (ZH), Xbench-Deepsearch 75; Excellent results on WebWalkerQA/GAIA/FRAMES/SIMPLEQA.
Summary
Tongyi DeepResearch-30B-A3B package contains A MOE (~30B, ~3B activity) architecture, 128K context, dual reaction/ITERRESEARCEREARH launch and automated proxy data + repeatable open open stacking stack in GRPO RL pipeline. For the team that builds a Changma Research Agency, it provides a practical balance of reasoning costs and capabilities and performs strongly on in-depth research benchmarks
Check Embrace the model on the face, github page and Technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


