Alibaba Qwen AI releases Compact Dense Qwen3-VL 4B/8B (command and think) with FP8 checkpoint
Do you really need a huge VLM when a dense Qwen3-VL 4B/8B (instruction/think) with FP8 runs in low VRAM but retains 256K→1M context and full feature surface? Alibaba Qwen Team Expands its intermodal lineup dense The Qwen3-VL model is located in 4B and 8B Scale, each transport in two task profiles –instruct and thinking-add FP8 Quantization Checkpointing for low VRAM deployments. This release is a smaller, edge-friendly addition to the previously released 30B (MoE) and 235B (MoE) layers and maintains the same functional surface: image/video understanding, OCR, spatial grounding, and GUI/agent control.
Post content?
SKUs and variations: New additions include four dense models –Qwen3-VL-4B and Qwen3-VL-8Beach in instruct and thinking version – next to FP8 4B/8B version of coaching and thinking checkpoints. The official announcement clearly defines these models as “compact, dense” models with lower VRAM usage and retaining full Qwen3-VL functionality.
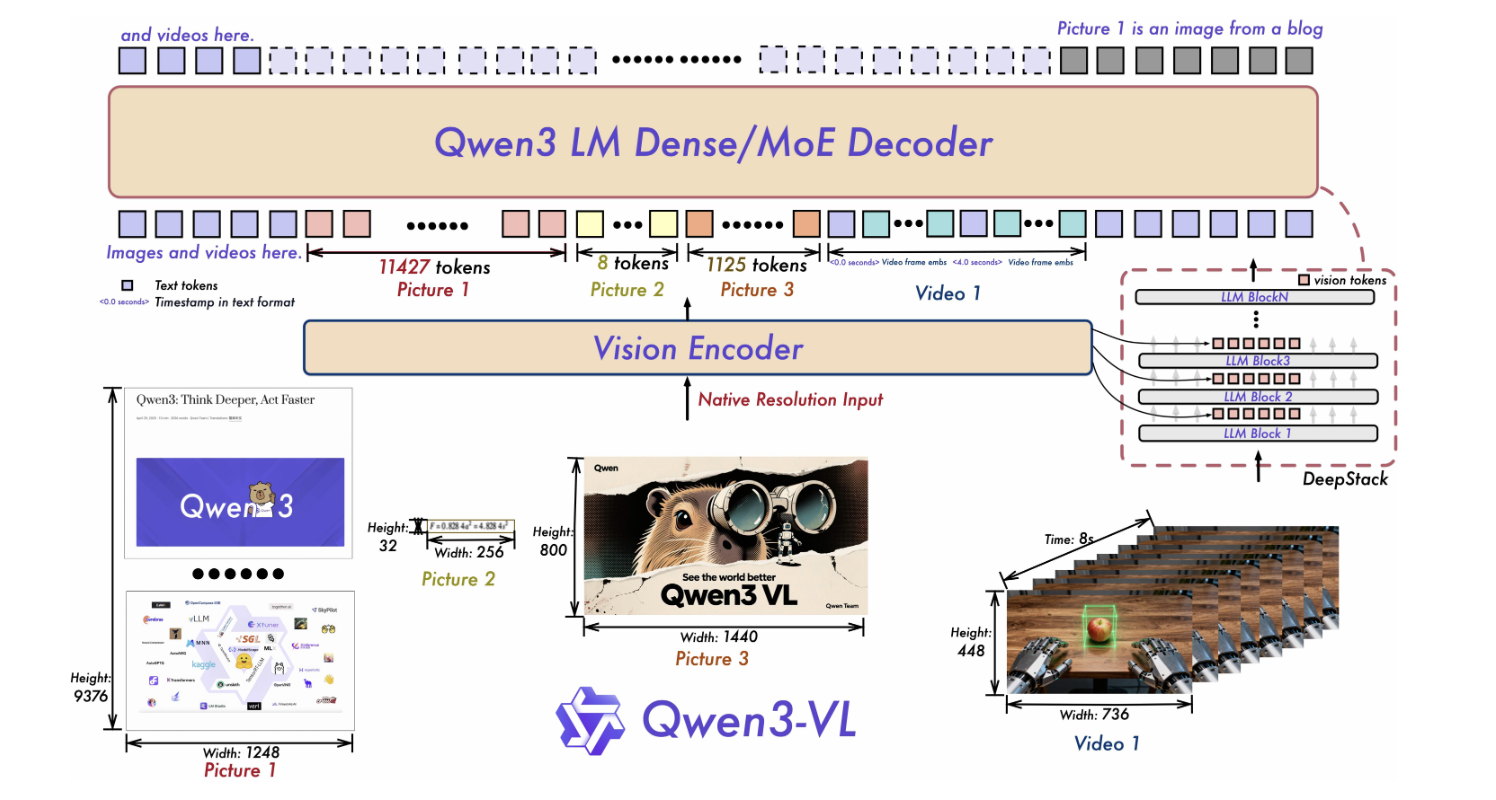
Context length and capability surfaces: Model card list Native 256K context and Can be expanded to 1Mand documents the complete feature set: long document and video understanding, 32 languages OCR2D/3D spatial fundamentals, visual coding, and agent GUI control on desktop and mobile devices. These attributes carry over to the new 4B/8B SKU.
Architecture Notes: Qwen3-VL highlights three core updates: Interleaved MRoPE Robust position encoding for time/width/height (long view video), deep stack for fusing multi-level ViT features and sharpening image text alignment, and text-timestamp alignment Video event positioning beyond T-RoPE. These design details are present in the new cards as well, marking architectural continuity across sizes.
Project timeline:Qwen3-VL Release documented in the GitHub News section Qwen3-VL-4B (guidance/thinking) and Qwen3-VL-8B (guidance/thinking) exist October 15, 2025following earlier releases of the 30B MoE tier and organization-wide availability of FP8.
FP8: Deployment related details
Numbers and Parity Statement: this FP8 Repository status Fine-grained FP8 quantization with block size 128and Performance metrics are almost identical to the original BF16 Checkpoint. For teams evaluating the accuracy trade-offs of multi-modal stacks (visual encoders, cross-modal fusion, long-context attention), having vendor-produced FP8 weights can reduce the burden of re-quantification and re-validation.
Tooling status: this 4B-Instruction-FP8 card pointed out Transformers do not yet load these FP8 weights directlyand recommend Master of Laws or Sigrand For servicing; the card contains the work initiation fragment. in addition, vLLM recipes The guide recommends using FP8 checkpoints to improve H100 memory efficiency. Together these point to a direct supported path for low VRAM inference.
Main points
- Posted by Kui Wen dense Qwen3-VL 4B and 8B model, each in instruct and thinking variant, with FP8 Checkpoint.
- FP8 Use fine-grained FP8 (block size 128) and Nearly BF16 index; Transformers Loading is not supported yet – use LLM/SG Language.
- Retention ability: 256K→1M context, 32 languages OCRspatial foundations, video inference, and GUI/agent control.
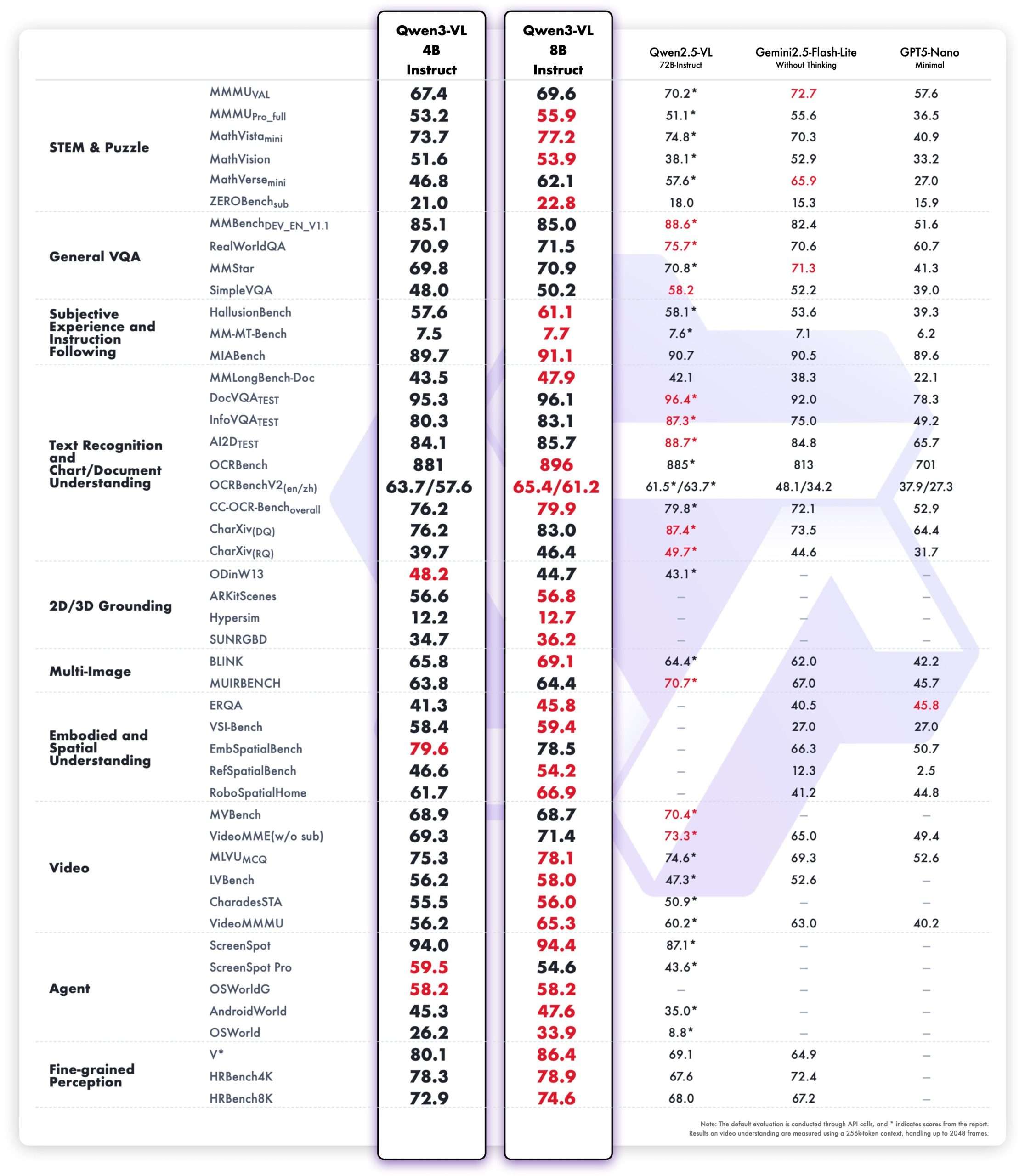
- Dimensions reported by model card: Qwen3-VL-4B ≈ 4.83B parameter; Qwen3-VL-8B-Command ≈ 8.77B parameter.
Qwen’s decision to deliver the dense Qwen3-VL 4B/8B in the form of instructions and thinking with FP8 checkpointing is the actual part of the story: lower VRAM, deployable weights (fine-grained FP8, block size 128) and clear service guidance (vLLM/SGLang) make it easy to deploy. The feature set (256K contexts scalable to 1M, OCR in 32 languages, spatial foundation, video understanding and agent control) remains unchanged at these smaller scales, which is more important than leaderboard rhetoric for teams targeting single GPU or edge budgets.
Check Model hugging face and GitHub repository. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


