AI Guardrails and Trusted LLM Assessment: Building responsible AI Systems
Introduction: The demand for AI guardrails continues to increase
As the capacity and deployment scales of large language models (LLMs) grow, the risk of unexpected behavior, hallucinations and harmful output increases. The latest surge in AI integration in the real world of healthcare, finance, education and defense sectors has expanded the need for strong security mechanisms. AI guardrails – technical and procedural controls that ensure alignment with human values and policies – have become a key area of concern.
this Stanford University 2025 AI Index Report 56.4% Jump In 2024-233 AI-related incidents, there is a strong guardrail urgency in total. at the same time, The Future of Life Institute The AGI security program has a poor rating, and no company has a higher rating than C+.
What is an AI guardrail?
AI guardrails refer to system-level security controls embedded in AI pipelines. These are not only output filters, but also building decisions, feedback mechanisms, policy restrictions and real-time monitoring. They can be classified as:
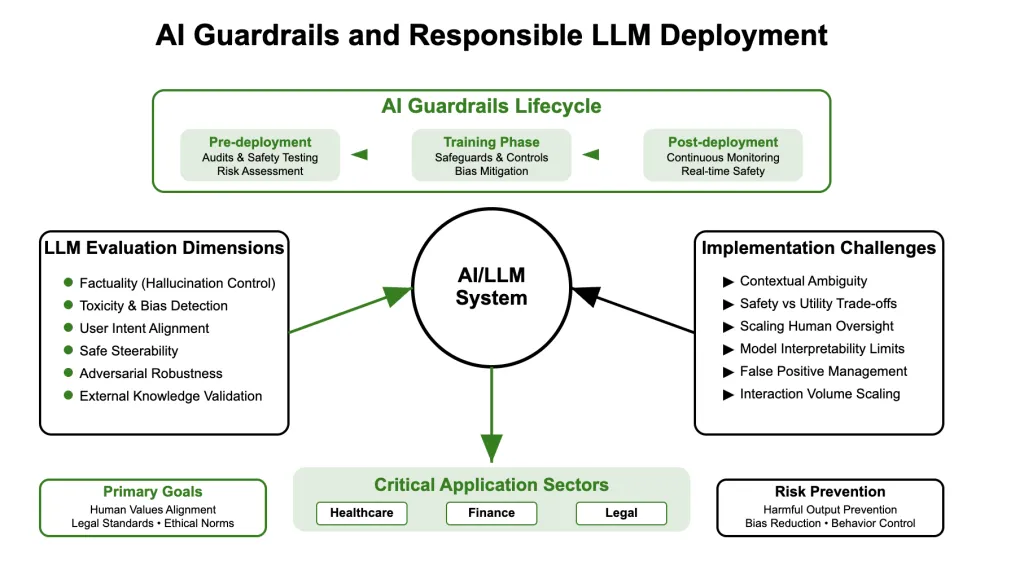
- Pre-department guardrail: Dataset audit, model red team, strategy fine-tuning. For example, AEGIS 2.0 includes interactions of 34,248 annotations in 21 security-related categories.
- Training time guardrail: Reinforcement learning through human feedback (RLHF), differential privacy, bias mitigation layers. It is worth noting that overlapping datasets can crash these guardrails and jailbreak.
- Deployment of the guardrail: Output appropriate amount, continuous evaluation, retrieval effect verification, and backup routing. In June 2025, Unit 42, the benchmark shows high false positives in moderation tools.
Trusted AI: Principles and pillars
Trusted AI is not a technology, but a combination of key principles:
- robustness: The model should behave reliably under allocation transfer or adversarial input.
- transparency: The reasoning path must be explained for users and auditors.
- responsibility: There should be a mechanism to track model actions and failures.
- fair: Output should not be permanent or amplified by social bias.
- Privacy protection: Technologies such as joint learning and differential privacy are crucial.
Legislative concerns about AI governance have risen: In 2024 alone, U.S. agencies issued 59 AI-related regulations in 75 countries. UNESCO has also developed global ethics codes.
LLM Assessment: Out of Accuracy
Evaluation of LLM goes far beyond traditional benchmarks of accuracy. Key dimensions include:
- fact: Is the model hallucination?
- Toxicity and prejudice: Is the output contained and harmless?
- Alliance: Is the model safely following the instructions?
- Availability: Can guidance be provided based on user intentions?
- robustness: How does it resist adversarial cues?
Evaluation technology
- Automatic metrics: Bleu, Rouge, confusing is still used, but alone.
- Human evaluation on the ring: Expert notes for security, tone and policy compliance.
- Confrontational test: Use red team technology to emphasize testing guardrail efficiency.
- Search authorization assessment: Fact-checking answers to the external knowledge base.
Multidimensional tools are being adopted, such as Helm (the overall evaluation of language models) and Holisticeval.
Architecture the guardrail to LLMS
The integration of AI guardrails must begin at the design stage. Structured methods include:
- Intent detection layer: Classification may not be safe for queries.
- Routing layer: Redirect to a Retrieval Enhanced Generation (RAG) system or human comment.
- Post-processing filter: Before the final output, use a classifier to detect harmful content.
- Feedback loop: Includes user feedback and continuous fine-tuning mechanisms.
Open source frameworks such as guardrail AI and Rail provide modular APIs for trying these components.
Challenges in LLM security and assessment
Despite the progress, there are major obstacles:
- Assessment ambiguity: Definitions that are harmful or fair vary in the environment.
- Adaptability and control: Too many restrictions reduce utility.
- Extended human feedback: Billions of generations of quality assurance are non-trivial.
- Inside the opaque model: Despite explanatory efforts, transformer-based LLMs remain largely black framed.
Recent studies have shown that overly restricted guardrails often result in higher false positives or unusable outputs (sources).
Conclusion: Towards responsible AI deployment
Guardrails are not the final solution, but an ever-evolving safety net. Trusted AI must serve as a system-level challenge, integrating architectural robustness, continuous assessment and ethical vision. With the autonomy and influence of LLM, proactive LLM evaluation strategies will be both a moral imperative and a technical necessity.
Organizations that build or deploy AI must view security and trustworthiness as an afterthought, but rather as a central design goal. Only in this way can AI develop into a reliable partner, rather than unpredictable risks.
FAQs on AI Guardrails and Responsible for LLM Deployment
1. What exactly is AI and why are they important?
AI guardrails are comprehensive security measures embedded throughout the AI development lifecycle, including pre-deployment pre-deployment audits, training safeguards, and post-deployment monitoring – helping to prevent harmful outputs, biases, and unexpected behavior. They are crucial to ensure that AI systems are aligned with human values, legal standards and ethics, especially as AI is increasingly used in sensitive sectors such as healthcare and finance.
2. How to evaluate large language models (LLMs)?
LLMs are evaluated on multiple dimensions such as facts (the frequency of their hallucinations), toxicity and bias of output, consistency with user intentions, impartability (which can be guided safely), and robustness against adversarial cues. The assessment combines automated metrics, human comment, adversarial testing, and fact checking of external knowledge bases to ensure safer and more reliable AI behavior.
3. What is the biggest challenge in implementing an effective AI guardrail?
Key challenges include ambiguity to define harmful or biased behaviors in different environments, balancing security controls with model utility, expanding oversight of large-scale human interactions, and limiting interpretability of deep learning models inherent in interpretability. Overly restrictive guardrails can also cause high false positives, frustrating users and limiting the practicality of AI.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex datasets into actionable insights.



