Agent0: A fully autonomous artificial intelligence framework that can evolve high-performance agents without external data through multi-step collaborative evolution.
Large language models require large datasets of humans, so what happens if the model has to create all its own classes and teach itself to use the tools? A team of researchers from the University of North Carolina at Chapel Hill, Salesforce Research, and Stanford University launches “Agent0,” a fully autonomous framework that evolves high-performance agents without the need for external data through multi-step co-evolution and seamless tool integration
Agent0 targets mathematics and general reasoning. It shows that careful task generation and tool integration deployment can push a base model beyond its original capabilities on ten benchmarks.
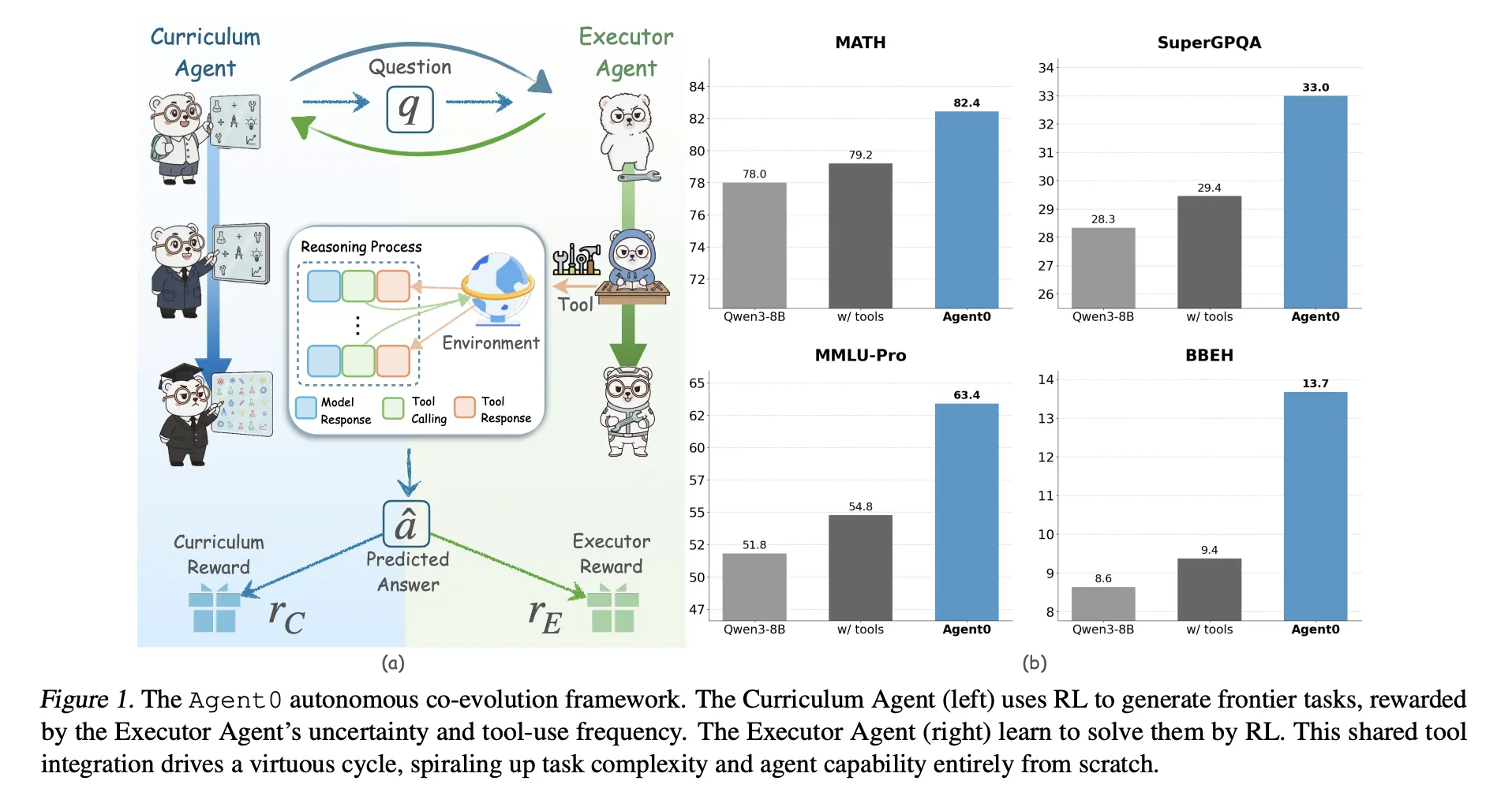
Two agents for a basic model
For example, Agent0 starts from the base policy π_base Qwen3 4B base or Qwen3 8B base. It clones this strategy as:
- one course agent Generate πθ of the task,
- one executive agent πphi uses Python tools to solve these tasks.
Training is performed in an iterative manner, with each iteration having two phases:
- Curriculum evolution: The course agent generates a batch of tasks. For each task, the executor samples multiple responses. The combined reward measures the performer’s uncertainty, the frequency with which the tool is used, and the diversity of batches. πθ is updated to Group Related Policy Optimization (GRPO) Use this reward.
- Actuator evolution: The trained course agent is frozen. It generates a lot of tasks. Agent0 filters this pool to only keep tasks near the boundary of the executor’s capabilities, and then trains the executor to handle these tasks using an ambiguity-aware RL objective named Fuzzy Dynamic Policy Optimization (ADPO).
This loop creates a feedback loop. As performers become more powerful through the use of code interpreters, courses must generate more complex, tool-dependent problems to keep returns high.

How course agents grade tasks?
Course rewards combine three signals:
uncertainty reward: For each generated task x, the executor samples k responses and selects a pseudo answer by majority vote. Self-consistency p̂(x) is the proportion of answers that agree with the majority. When p̂ is close to 0.5, the reward is maximum; when the task is too easy or too difficult, the reward is lower. This encourages tasks that are challenging but still solvable for the current performer.
Tool usage rewards: Executors can trigger the sandbox code interpreter using python Mark and receive results marked as output. Agent0 counts the number of tool calls in the trajectory and gives proportionally adjusted, upper-limit rewards. In the experiment, the upper limit C is set to 4. This is beneficial for tasks that require actual tool invocation rather than purely mental arithmetic.
Repeat punishment: In each course batch, Agent0 uses BLEU-based distance to measure pairwise similarity between tasks. Tasks are clustered, and the penalty term increases with cluster size. This prevents the course from producing a lot of near-duplicate content.
The compound reward multiplies the format check by the weighted sum of the uncertainty and tool rewards minus the duplication penalty. This resultant value is fed into GRPO to update πθ.
How performers learn from noisy self-labels?
The executor is also trained on GRPO, but using multiple rounds, tool ensemble trajectories and pseudo labels instead of real answers.
Cutting edge data set construction: After one iteration of course training, the frozen course will generate a huge candidate pool. For each task, Agent0 computes the self-consistency p̂(x) with the current executor and retains only tasks where p̂ lies within the information band, for example between 0.3 and 0.8. This defines a challenging, cutting-edge data set that avoids trivial or impossible problems.
Multi-turning tool integration launched: For each frontier task, the executor generates a trajectory that can be interleaved:
- natural language reasoning markup,
pythoncode snippet,outputTool feedback.
When a tool call occurs, the build is paused and code is executed in the built sandbox interpreter Willy Toolsand then resume based on the results. The trajectory terminates when the model internally produces the final answer {boxed ...} Label.
A majority vote of sampled trajectories defines the pseudo-label and final reward for each trajectory.
ADPO, ambiguity-aware reinforcement learning: Standard GRPO treats all samples equally, which is unstable when labels come from majority voting on ambiguous tasks. ADPO uses p̂ as a blur signal to modify GRPO in two ways.
- It measures normalized advantage by a factor that increases with self-consistency, so that trajectories from low-confidence tasks contribute less.
- It sets a dynamic upper bound on the importance ratio, which depends on self-consistency. Empirical analysis shows that fixed-cap clipping mainly affects low-probability tags. ADPO adaptively relaxes this bound, thereby improving exploration of uncertain tasks such as Increase marking probability Statistics.

Results of mathematics and general reasoning
Agent0 is implemented on top of Vail and evaluated Qwen3 4B base and Qwen3 8B base. It uses a sandboxed Python interpreter as a single external tool.
The research team evaluated against ten benchmarks:
- mathematical reasoning: AMC, Minerva, MATH, GSM8K, Olympic bench, AIME24, AIME25.
- general reasoning: SuperGPQA, MMLU Pro, BBEH.
They report pass@1 for most datasets and mean@32 for the AMC and AIME tasks.
for Qwen3 8B baseAgent0 arrives:
- The mathematical mean is 58.2 and the base model is 49.2,
- The overall average is 42.1, compared with 34.5 for the base model.
Agent0 also improves robust data-free baselines, e.g. Zero, Absolute zero, spiral and Socrates Zerowith or without tools. On the Qwen3 8B, its overall average outperformed R Zero by 6.4 percentage points and Absolute Zero by 10.6 percentage points. It also defeated Socratic Zero, which relied on an external OpenAI API.
In 3 coevolution iterations, the average mathematical performance of Qwen3 8B improved from 55.1 to 58.2, and the general reasoning ability also improved with each iteration. This confirms stable self-improvement rather than collapse.
Qualitative examples show that course tasks evolve from basic geometry problems to complex constraint satisfaction problems, while executor trajectories mix reasoning text with Python calls to arrive at the correct answer.
Main points
- Completely data-free co-evolution:Agent0 eliminates external datasets and human annotation. Both agents (course agent and execution agent) are initialized from the same LLM base and co-evolve only through reinforcement learning and Python tools.
- Cutting edge courses on self-uncertainty: Course agents leverage performers’ self-consistency and tool usage to score tasks. It learns to generate cutting-edge tasks that are neither easy nor impossible and explicitly require tool-integrated reasoning.
- ADPO uses pseudo-labels to stabilize RL: The executor is trained with fuzzy dynamic policy optimization. ADPO downweights highly ambiguous tasks and adjusts the clipping range based on self-consistency, which allows GRPO-style updates to remain stable when rewards come from majority-voted pseudo-labels.
- Continued progress in mathematics and general reasoning: On Qwen3 8B Base, Agent0 improved the math benchmark average from 49.2 to 58.2 and general reasoning from 34.5 to 42.1, equivalent to relative gains of approximately 18% and 24%.
- Better than previous zero data frames: Across ten benchmarks, Agent0 outperforms previous self-evolving methods such as R Zero, Absolute Zero, SPIRAL, and Socratic Zero, including those that have used tools or external APIs. This suggests that coevolution plus tool-integrated design is a meaningful step beyond early single-round self-play approaches.
Editor’s Note
Agent0 is an important step toward practical, data-free reinforcement learning for tool-enabled inference. It shows that the base LLM can act as a course agent and an execution agent, and GRPO with ADPO and VeRL tools can drive stable improvements in majority voting pseudo-labeling. The approach also shows that tool ensemble co-evolution can outperform previous zero-data frameworks such as R Zero and Absolute Zero on the powerful Qwen3 baseline. Agent0 provides strong evidence that self-evolving, tool-integrated LLM agents are becoming a realistic training paradigm.
Check Papers and repurchase agreements. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


