A new MIT study shows that compared to fine-tuning of supervision
What is catastrophic forgetting in the basic model?
The base model performs well in different fields, but once deployed it is largely static. Fine-tuning of new tasks is often introduced Disastrous forgetting– Loss of previous learning ability. This limitation presents obstacles to building longevity and continual improvement of AI agents.
Why do online strengthening learning forget less fine-tuning than supervision?
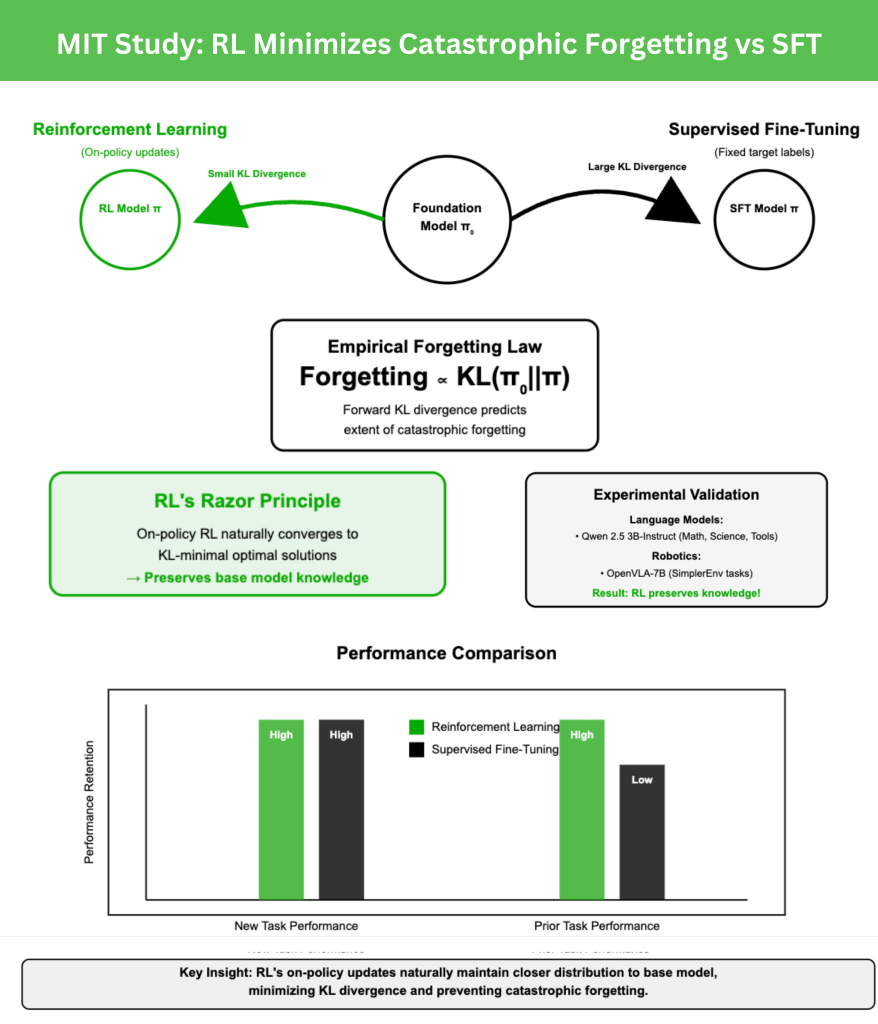
A new MIT study comparison Strengthening Learning (RL) and Supervised fine-tuning (SFT). Both can achieve high performance on new tasks, but SFT tends to cover previous capabilities. By contrast, RL retains them. The key is how each method changes the output distribution of the model relative to the fundamental strategy.
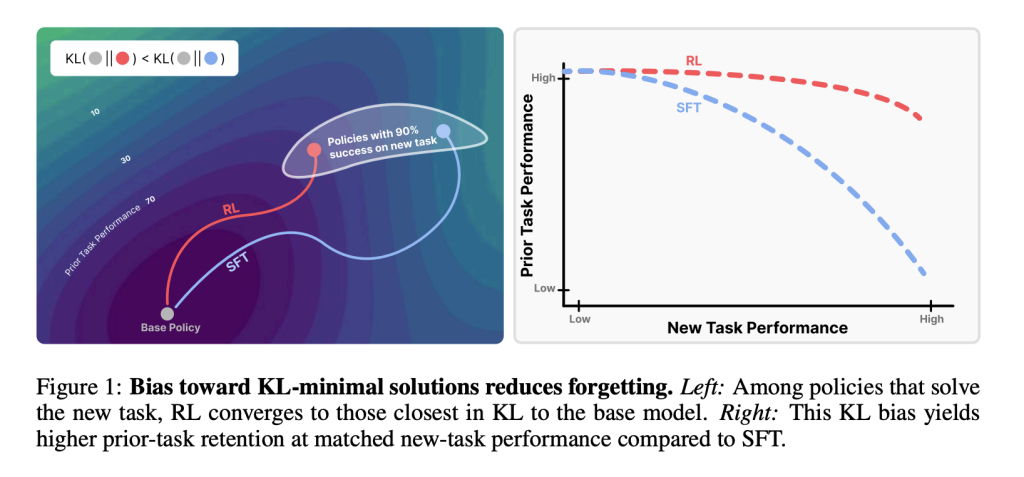
How can I measure forget?
The research team proposed an empirical forgetting law:
Forgot ∝Kl (π0°π)
Where π0 is the basic model and π is the fine-tuning model. this Forward kl divergenceMeasuring on new tasks, the degree of forgetting is strongly predicted. This makes the quantifiable situation forgetful cases without the need to do data from previous tasks.
What does the experiment of the Dayu model show?
Using QWEN 2.5 3B teaching as the basic model, the following methods were fine-tuned:
- Mathematical reasoning (Season Zero Season),
- Scientific Q&A (Sciknoweval subset),
- Tool usage (Toolalpaca).
Performance was evaluated in previous benchmarks such as Hellaswag, Mmlu, Elthfulqa and Humaneval. The results show that RL improves the accuracy of new tasks while keeping the task stable, while SFT always sacrifices prior knowledge.
How does RL compare to SFT in robot tasks?
OpenVla-7b fine-tuning was performed in robot control experiment Simple Select scenarios, RL adaptation can maintain general manipulation techniques across tasks. Although SFT successfully completed the new task, it still reduced its previous manipulation capabilities – and illustrates the conservatism of RL in maintaining knowledge.
What insights does Pullmanism study bring?
In order to isolate the mechanism, the research team introduced the toy problem. Paritymnist. Here, both RL and SFT achieve the accuracy of high-tech tasks, but the fashion assist benchmark caused by SFT has dropped. Crucially, the plot of KL differential forgetting reveals a single prediction curve that validates KL as a governance factor.
Why is it important to update the policy?
From the model’s own output, the sampled policy RL sample is gradually reweighted by reward. This process limits learning to distributions that are already close to the fundamental model. In contrast, SFT can be optimized for fixed labels that may be arbitrarily distant. Theoretical analysis shows that the strategy gradient converges to The best solution for KLthe advantages of formalizing RL.
Are other explanations enough?
The research team tested alternatives: weight space variation, hidden representation drift, updated sparsity and alternative allocation metrics (reverse KL, total variation, L2 distance). No one matches the predicted intensity Forward kl divergenceenhancing the distribution intimacy is the key factor.
What is the broader meaning?
- Evaluate: KL-Conversation should be considered after training, not just task accuracy.
- Mixed method: Combining SFT efficiency with explicit KL minimization can produce the best trade-off.
- Continue to learn:RL’s Razor provides a measurable standard for designing adaptive agents that learn new skills without deleting old skills.
in conclusion
MIT research restructures catastrophic forgetting because Forward kl divergence. Forgot to strengthen learning less KL Minimum Solution. This principle –RL’s razor– Provides an explanation of RL robustness and also provides a roadmap for developing post-training methods to support lifelong learning in the underlying model.
Key Points
- Reinforcement learning (RL) ratio priority knowledge comparison Supervised fine-tuning (SFT): Even if both achieve the same accuracy on new tasks, RL retains previous functionality while SFT erases them.
- Forgeting can be predicted through KL Divergence: The degree of catastrophic forgetting is closely related to the positive KL difference between fine-tuning measured by new tasks and basic policies.
- RL’s shaving principle:On-Policy RL converges to KL Minimum Solutionensure updates remain close to the basic model and reduce forgetting.
- Cross-domain experience verification: Experiments conducted on LLMS (mathematics, scientific question and answers, tool usage) and robotic tasks confirm the robustness of RL, not forgetting, while SFT always trades old knowledge to obtain the performance of new tasks.
- Controlled experiments confirm generality: Both RL and SFT show forgetting that is consistent with KL Divergence in the Paritymnist toy environment, proving that this principle goes beyond the large model.
- Future design axis after training: Algorithms should be evaluated not only by the accuracy of new tasks, but also by their conservative transfer distribution in KL space, opening up avenues for hybrid RL-SFT methods.
Check Paper and Project page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


