Meta AI introduces MLGYM: A new AI framework and benchmarks for advancing AI research agents

The ambition to accelerate scientific discovery through AI has long been long, with early efforts such as the AI projects applied by the Oak Ridge date back to 1979. Latest advances in basic models show that the feasibility of a fully automated research pipeline enables AI systems to be automatically performed. Literature review, propose hypotheses, design experiments, analyze results, and even generate scientific papers. Additionally, they can simplify scientific workflows by automating repetitive tasks, allowing researchers to focus on advanced conceptual work. However, despite these promising developments, the assessment of AI-driven research remains challenging due to the lack of standardized benchmarks that can fully evaluate their capabilities in different scientific fields.
Recent research addresses this gap by introducing benchmarks to evaluate various software engineering and machine learning tasks for AI agents. Despite frameworks to test AI agents’ well-defined issues such as code generation and model optimization, most current benchmarks do not fully support open-ended research challenges, where multiple solutions may arise. Furthermore, these frameworks often lack flexibility in evaluating various research findings, such as novel algorithms, model architectures, or predictions. To advance AI-driven research, evaluation systems are needed to incorporate a wider range of scientific tasks, promote experiments with different learning algorithms, and adapt to various forms of research contributions. By establishing such a comprehensive framework, the field can be closer to the realization of AI systems that can independently drive meaningful scientific advances.
Researchers at University College London, University of Wisconsin-Madison, Oxford, Meta University and other institutions have introduced a new framework and benchmark for evaluating and developing LLM agents in AI research. The system is the first gym environment for ML tasks, facilitating research on RL technology for training AI agents. The benchmark MLGYM dock includes 13 open tasks covering computer vision, NLP, RL and game theory, requiring practical research skills. The six-level framework classifies the functions of AI research agents. The focus of the MLGYM foundation is level 1: baseline improvement, LLMS optimizes the model, but lacks scientific contribution.
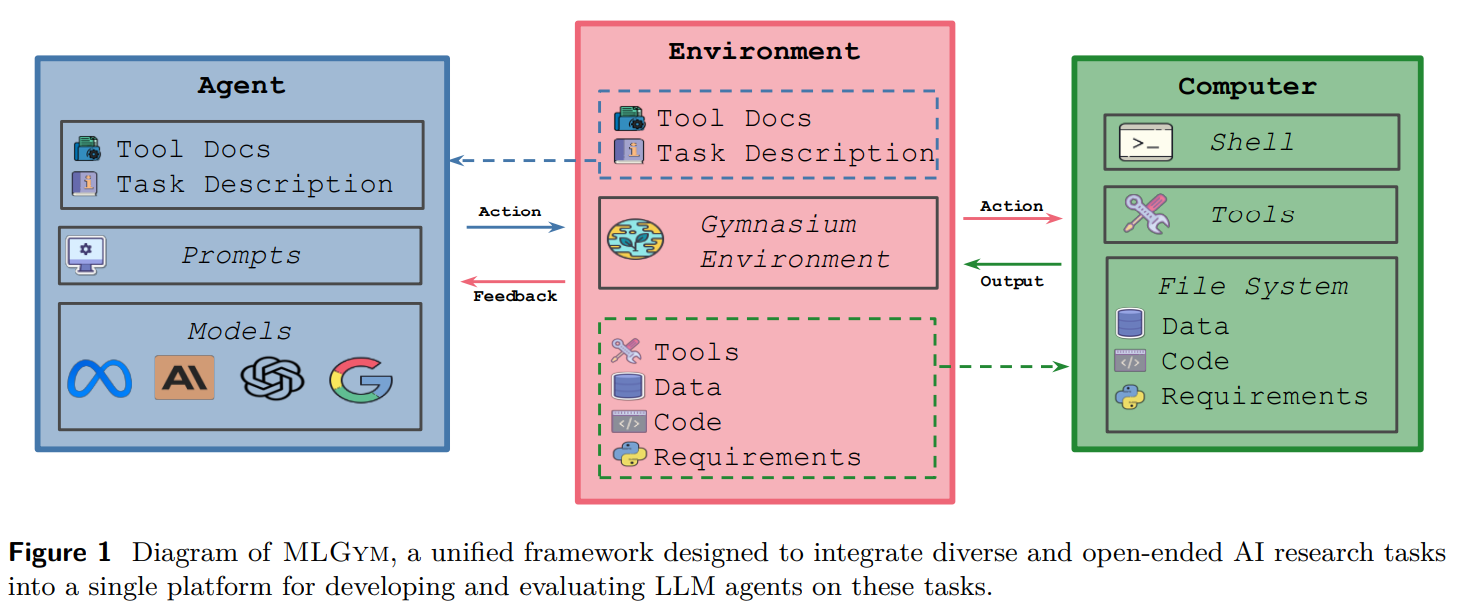
MLGYM is a framework designed to evaluate and develop LLM agents for ML research tasks through sequential commands through interaction with the Shell environment. It includes four key components: proxy, environment, dataset, and tasks. The agent executes bash commands, manages history and integrates external models. The environment provides a secure Docker-based workspace with controlled access. The dataset is defined separately from the task, allowing for reuse across experiments. Tasks include evaluation scripts and configurations for different ML challenges. In addition, MLGYM also provides tools for literature search, memory storage and iterative verification to ensure effective experimentation and adaptability in long-term AI research workflows.
This study uses a SWE-Agent model designed for the MLGYM environment, followed by a reactive decision cycle. Five state-of-the-art models – Openai O1-Preiview, Gemini 1.5 Pro, Claude-3.5-Sonnet, Llama-3-405b-Instruct and GPT-4O, were all evaluated under standardized settings. Performance is evaluated using AUP scores and performance profiles and the models are compared based on best trial and best submission metrics. Openai O1-preview achieved the highest overall performance, with the Gemini 1.5 Pro and Claude-3.5-Sonnet following behind. This study highlights performance profiles as an effective evaluation method, showing that OpenAI O1-preiview always ranks the highest-ranking model of various tasks.
In summary, the study highlights the potential and challenges of using LLMs as a scientific workflow body. MLGYM and MLGYMBENCH exhibit adaptability in various quantitative tasks, but reveal an improvement gap. Extending beyond ML, testing interdisciplinary generalizations and evaluating scientific novelty are key areas of growth. The study highlights the importance of data openness in enhancing collaboration and discovery. With the advancement of AI research, advances in reasoning, proxy architecture and evaluation methods are crucial. Strengthening interdisciplinary collaboration can ensure that AI-driven agents accelerate scientific discoveries while maintaining repeatability, verifiability and integrity.
Check Paper and github pages. All credits for this study are to the researchers on the project. Also, please feel free to follow us twitter And don’t forget to join us 80k+ ml subcolumn count.
 Recommended Reading – LG AI Research Unleashes Nexus: An Advanced System Integration Agent AI Systems and Data Compliance Standards to Address Legal Issues in AI Datasets
Recommended Reading – LG AI Research Unleashes Nexus: An Advanced System Integration Agent AI Systems and Data Compliance Standards to Address Legal Issues in AI Datasets
Meta AI Post introduced MLGYM: a new AI framework and benchmarks for advancing AI research agents, first appeared on Marktechpost.


