AI Interview Series #3: Federated Learning Explained
question:
“You’re a machine learning engineer at a fitness company like Fitbit or Apple Health.
Millions of users generate sensitive sensor data every day—heart rate, sleep cycles, step counts, exercise patterns, and more.
You want to build a model to predict health risks or recommend personalized exercises.
But due to privacy laws (GDPR, HIPAA), none of this raw data can leave the user’s device.
How would you train such a model?“
Training a model in this situation might seem impossible at first—after all, you can’t collect or centralize any user’s sensor data. But here’s the trick: instead of bringing the data into the model, you bring the model into the data.
Using techniques like federated learning, the model is sent to each user’s device, trained locally on their private data, and only model updates (not the original data) are sent back. These updates are then securely aggregated to improve the global model while keeping each user’s data completely private.
This approach allows you to leverage large real-world data sets without violating privacy laws.
What is federated learning
Federated learning is a technique for training machine learning models without the centralized collection of user data. Rather than uploading private data (such as heart rate, sleep cycles, or exercise logs), the model is sent to each device, trained locally, and only model updates are returned. These updates are securely aggregated to improve global models—ensuring privacy and compliance with laws like GDPR and HIPAA.
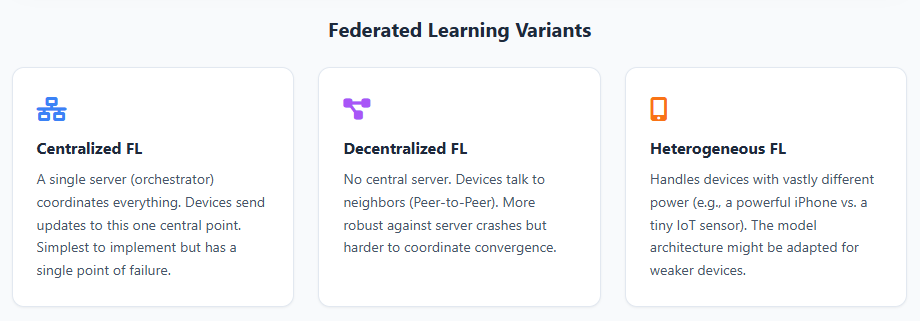
There are many variations:
- Centralized FL: A central server coordinates training and aggregates updates.
- Decentralized FL: Devices share updates directly with each other, no single point of failure.
- Heterogeneous FL: Designed for devices with different computing capabilities (mobile phones, watches, IoT sensors).
The workflow is simple:
- The global model is sent to the user device.
- Each device is trained on its private data (e.g., the user’s fitness and health metrics).
- Only model updates (not data) are encrypted and sent back.
- The server aggregates all updates into a new global model.

Federated Learning Challenges
Device restrictions: User devices (phones, smartwatches, fitness trackers) have limited CPU/GPU power, small RAM, and are battery dependent. Training must be lightweight, energy-efficient and intelligently scheduled so that it does not interfere with the normal use of the equipment.
Model aggregation: Even after training locally on thousands or millions of devices, we still need to merge all these model updates into a global model. Technologies such as federated averaging (FedAvg) can help, but updates may be delayed, incomplete, or inconsistent depending on device participation.
Skewed local data (non-IID data):
Each user’s fitness data reflects personal habits and lifestyle:
- Some users run every day; Others never run.
- Some people have a higher resting heart rate; Others are low.
- Sleep cycles vary greatly depending on age, culture, and work patterns.
- Workout types vary – yoga, strength training, cycling, HIIT, and more.
This results in uneven, biased local data sets, making it more difficult for the global model to learn generalized patterns.
Intermittent client availability: Many devices may be offline, locked, have low battery, or not connected to Wi-Fi. Training must only take place under safe conditions (charging, idle, Wi-Fi), thus reducing the number of active participants at any one time.
Communication efficiency: Sending model updates frequently drains bandwidth and battery. Updates must be compressed, sparse, or limited to a smaller subset of parameters.
Security and Privacy Guaranteed: Even if the original data never leaves the device, updates must be encrypted. Additional protections, such as differential privacy or secure aggregation, may be needed to prevent sensitive patterns from being reconstructed from gradients.

I am a Civil Engineering graduate (2022) from Jamia Millia Islamia, New Delhi and I am very interested in data science, especially neural networks and their applications in various fields.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


