Cerebras releases MiniMax-M2-REAP-162B-A10B: a memory-efficient version of MiniMax-M2 for long context encoding agents
Cerebras has been released MiniMax-M2-REAP-162B-A10Bcompressed Sparse Mixture of Experts (SMoE) Causal Language Model from MiniMax-M2use new Router Weighted Expert Activation Pruning (REAP) method. This model retains the behavior of the original model Total 230B, 10B activities MiniMax M2, while pruning experts and reducing memory for deployment-centric workloads such as encoding agents and tool calls.
Architecture and core specifications
MiniMax-M2-REAP-162B-A10B has the following key attributes:
- base model:MiniMax-M2
- Compression method: REAP, Router Weighted Expert Activation Pruning
- Total parameters:162B
- Activity parameters for each token:10B
- Number of layers: 62 transformer blocks
- Pay attention to the number of heads on each floor:48
- expert: 180 experts, obtained by pruning 256 expert configurations
- Experts activated per token: 8
- context length: 196,608 tokens
- license: Improved MIT, derived from MiniMaxAI MiniMax M2
The SMoE design means the model stores 162B parameters, but each token is only routed through a small group of experts, so Effective computational cost per token is similar to 10B dense model. MiniMax M2 itself is positioned as a MoE model purpose-built for encoding and agent workflows, with 230B total parameters and 10B active parameters, and this checkpoint inherits this.
REAP How to compress MiniMax-M2?
MiniMax-M2-REAP-162B-A10B was created through the application Harvest Evenly distributed across all MoE blocks of MiniMax M2, 30% expert trimming rate.
this Harvest The method defines a significance score for each expert that combines:
- Router threshold: How often and how strongly the router selects this expert
- Expert activation specifications: Size of expert output when activated
Under this combination criterion, experts with the smallest contribution to the layer output will be removed. The remaining experts retain their original weights, and the router retains separate gates for each of them. This is a one-time compression, with no additional fine-tuning after pruning in the method definition.
A core theoretical result of the REAP research paper is Expert merger Have general reason functional subspace collapse. When experts are merged, the router loses independent, input-dependent control over these experts, so a single merged expert must approximate the input-dependent mixture originally expressed by multiple experts. The research team demonstrated that whenever a router policy depends on inputs and the experts are not identical, irreducible errors are introduced. In contrast, pruning removes some experts but retains independent control of survivors, so the error scales with the gate weights of the removed experts.
Spanning a set of SMoE models 20B to 1T parameter rangeREAP consistently outperforms expert merging and other pruning criteria Generate benchmark such as code generation, mathematical reasoning, and tool invocation, especially when 50% compression.
Expert pruning accuracy is less than 30%
The MiniMax-M2-REAP-162B-A10B model is compared at three checkpoints on standard encoding, inference and agent benchmarks:
- MiniMax-M2 (230B, basic model)
- MiniMax-M2-REAP-172B-A10B, 25% trim
- MiniMax-M2-REAP-162B-A10B, 30% trim
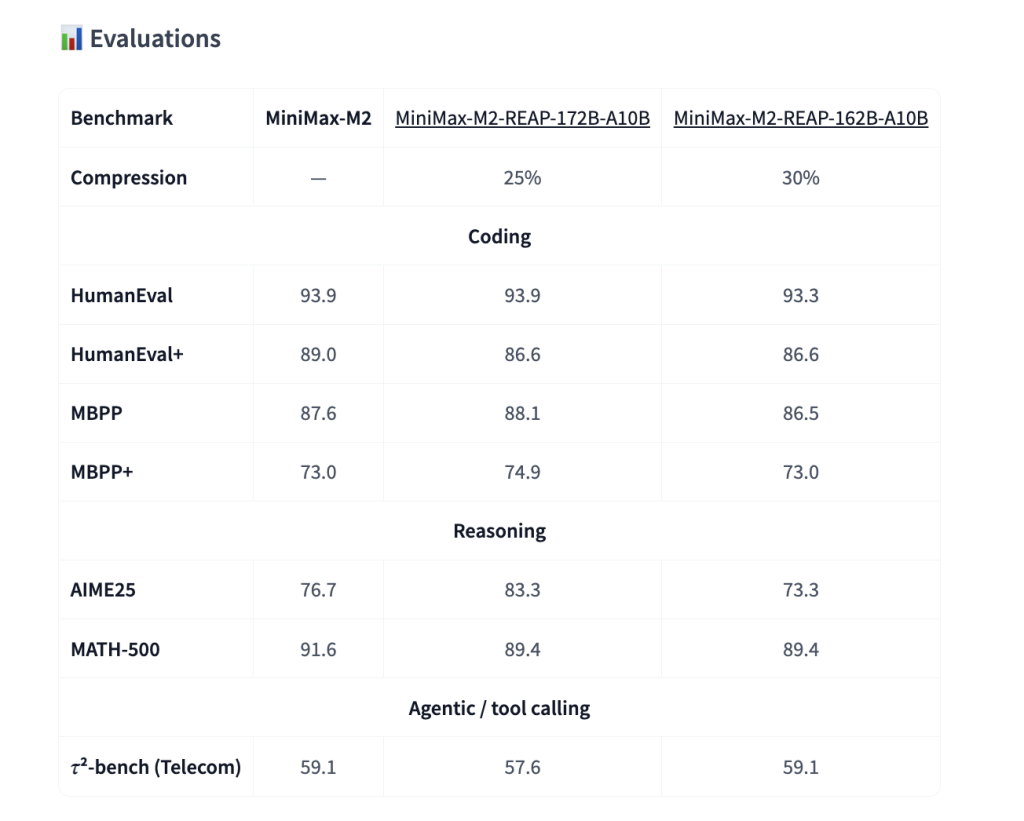
exist Coding benchmarks Such as HumanEval, HumanEval Plus, MBPP and MBPP Plus, the 162B REAP model is very close to the basic model. HumanEval sits around 90% rangeMBPP remains in 80% range, the 172B and 162B models basically track the original MiniMax-M2 within a few points.
exist Inference benchmark For example, AIME 25 and MATH 500, there are minor changes between the three models, but there is no crash under 30% pruning, and the 162B checkpoint is still competitive with the base model.
Regarding tool invocation and agent evaluation, denoted by τ2 In benchmark tests in a telecom environment, the 162B REAP model again matched the base model with only minor differences. The model card clearly states that this checkpoint maintains almost the same performance while reducing the number of parameters by about 30%.
These results are consistent with the broader REAP study, which reported Near lossless compression Used for code generation and tool invocation of multiple large SMoE schemas when using the REAP Standard Pruning Expert.
Deployment, memory usage, and observed throughput
Cerebras offers direct Master of Laws Provide examples and position MiniMax-M2-REAP-162B-A10B as decline in the model Works with existing MiniMax M2 integration.
vllm serve cerebras/MiniMax-M2-REAP-162B-A10B
--tensor-parallel-size 8
--tool-call-parser minimax_m2
--reasoning-parser minimax_m2_append_think
--trust-remote-code
--enable_expert_parallel
--enable-auto-tool-choiceIf running up to memory limits, the card is recommended to reduce --max-num-seqs,For example 64to control the batch size on a given GPU.
Main points
- SMoE architecture with efficient computing capabilities: MiniMax-M2-REAP-162B-A10B is a sparse expert mixture model with 162B total parameters and 10B active parameters per token, so the computational cost per token is close to that of a 10B dense model while maintaining cutting-edge scale capacity.
- REAP expert trim maintains MiniMax-M2 behavior: This model is generated by applying REAP router weighted expert activation pruning to MiniMax-M2 with an expert pruning rate of approximately 30%, pruning experts based on router gate values and expert activation specifications while keeping surviving expert and router structures intact.
- Near lossless accuracy at 30% compression: On encoding benchmarks such as HumanEval and MBPP, and inference benchmarks such as AIME25 and MATH 500, the 162B REAP variant tracked the 230B MiniMax-M2 and 172B REAP variants within several points, showing that the code, inference, and tools use near-lossless compression.
- Pruning to generate SMoE is better than expert merging: REAP research shows that pruning experts using saliency criteria avoids the functional subspace collapse that occurs when experts are merged in generation tasks, and performs better in large SMoE models ranging from 22B to ~1T parameters.
comparison table
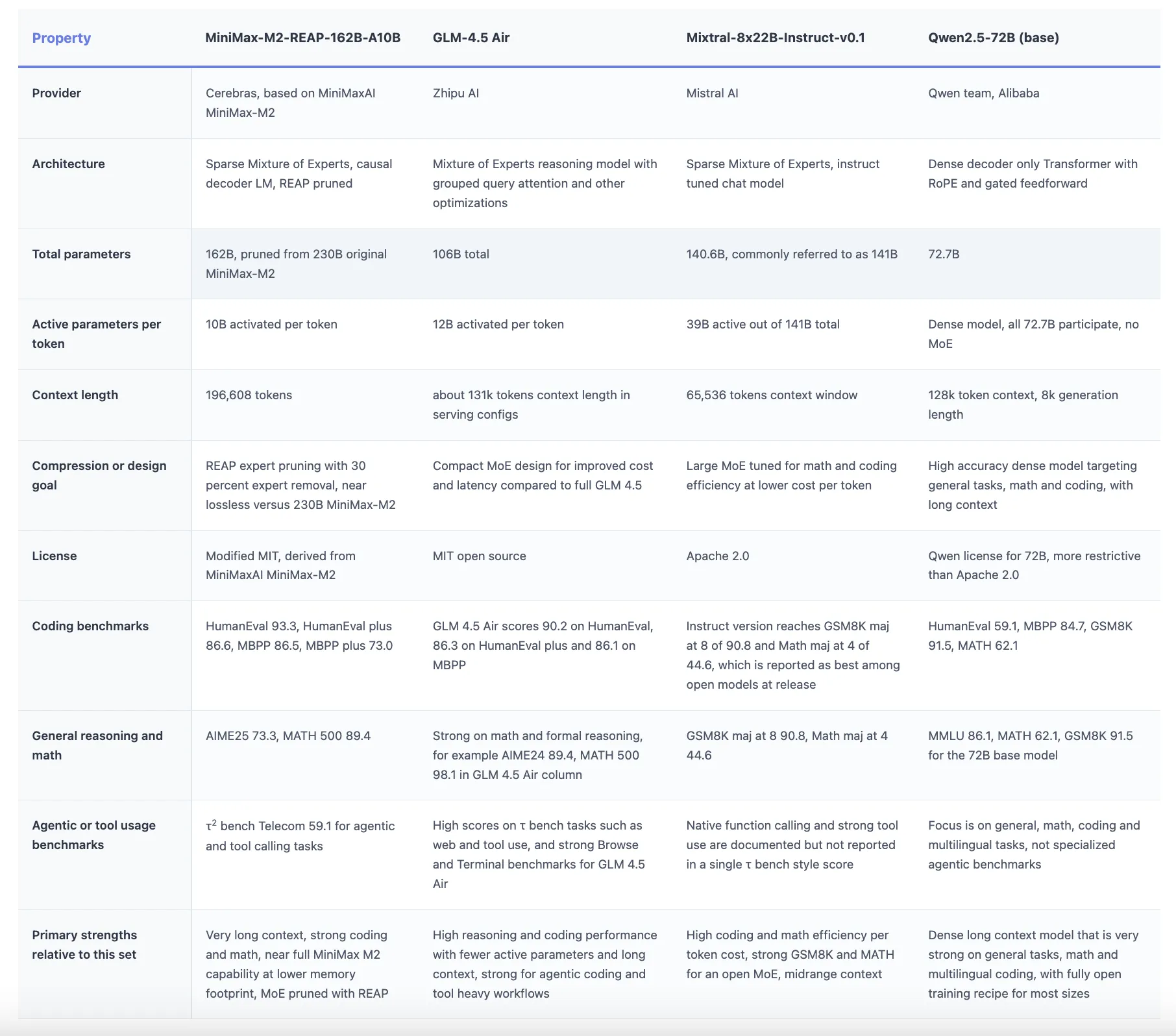
Release of Cerebras MiniMax-M2-REAP-162B-A10B is a strong signal Router Weighted Expert Activation Pruning Be prepared for real workloads, not just research curiosity. Checkpoint shows, 30% expert trimming Schedule can be kept Mini Max-M2 230B-A10B The behavior is nearly intact while slashing memory and preserving long-context encoding, inference, and tool invocation performance, which is what SMoE researchers need for real-world deployments. Overall, Cerebras is quietly transitioning expert pruning into production infrastructure for cutting-edge SMoE models.
Check Model weight. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.
: An Effective Enhancement Learning Algorithm Powering the QWEN3 Model")

