AI Interview Series #1: Explaining Some LLM Text Generation Strategies Used in LLM
Each time you prompt LLM, it doesn’t generate a complete answer immediately – it builds a response one word (or token) at a time. At each step, the model predicts the probability of the next token based on everything written so far. But simply knowing the probabilities isn’t enough – the model also needs a strategy to decide which token is actually chosen next.
Different strategies can completely change the look of your final output – some make it more focused and precise, while others make it more creative or diverse. In this article we will explore Four Popular Text Generation Strategies Used in LL.M.: greedy search, beam search, Nucleus samplingand temperature sampling —Explain how each item works.
greedy search
Greedy search is the simplest decoding strategy, where at each step the model selects the token with the highest probability given the current context. While it’s fast and easy to implement, it doesn’t always produce the most coherent or meaningful sequences – akin to making the best local choice without considering the overall outcome. Since it only follows one path in the probability tree, it may miss better sequences that require short-term trade-offs. Therefore, greedy search often results in repetitive, generic, or boring text, making it unsuitable for open-ended text generation tasks.
beam search
Beam search is an improved decoding strategy over greedy search that tracks multiple possible sequences (called beams) at each generation step instead of just one. It expands the top K most likely sequences, allowing the model to explore several promising paths in the probability tree and potentially discover higher quality completions that a greedy search might miss. The parameter K (beam width) controls the trade-off between quality and computation – larger beams produce better text, but are slower.
While beam search performs well in structured tasks such as machine translation, where accuracy is more important than creativity, it tends to produce text that is repetitive, predictable, and less diverse in open-ended generation. This happens because the algorithm favors high-probability continuations, resulting in fewer changes and “neural text degradation,” where the model overuses certain words or phrases.

Greedy search:
Beam search:
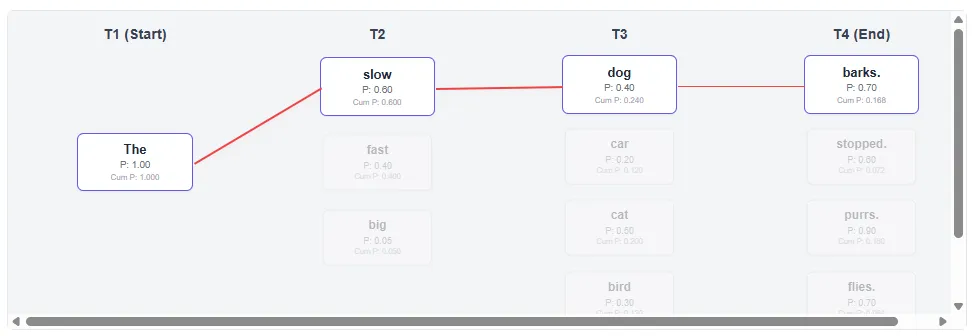
- Greedy search (K=1) Always take the highest local probability:
- T2: Select “Slow” (0.6) exceeds “fast” (0.4).
- Result path: “Slow dog barks.” (Final probability: 0.1680)
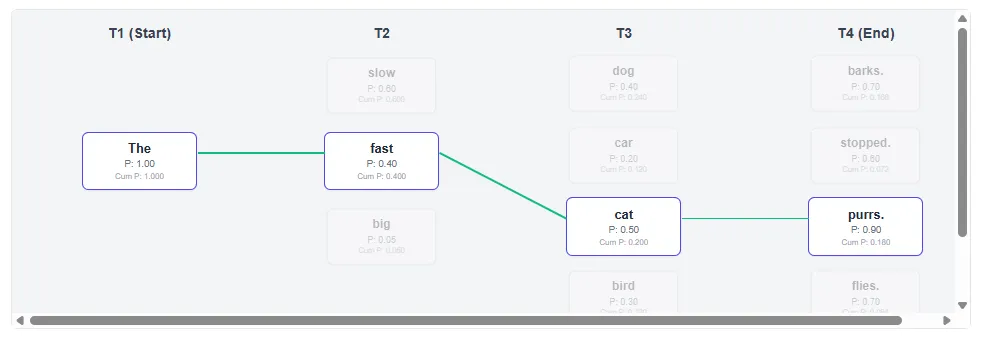
- Beam search (K=2) keep both “Slow” and “quickly” Alive path:
- In T3, it realizes that paths starting with “fast” are more likely to have a good ending.
- Result path: “A fast cat purrs.” (Final probability: 0.1800)
Beam search successfully explores a path with a slightly lower early probability, resulting in a better overall sentence score.
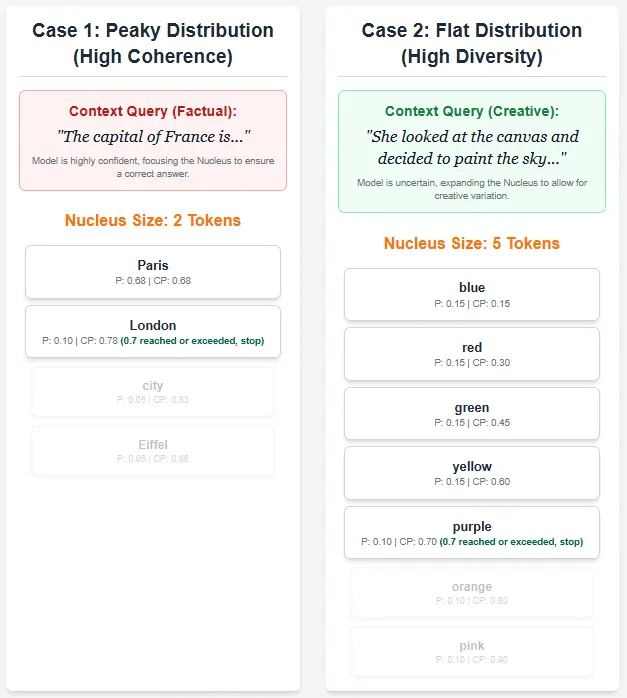
Top-p sampling (Nucleus Sampling) is a probabilistic decoding strategy that dynamically adjusts the number of tokens considered to be generated at each step. Instead of picking from a fixed number of top tokens like top-k sampling, top-p sampling selects the smallest set of tokens whose cumulative probability sums up to a chosen threshold p (e.g. 0.7). These tokens form a “kernel” from which the next token is randomly sampled after normalizing its probability.
This allows the model to balance diversity and consistency – sampling from a wider range when many markers have similar probabilities (flat distribution), and narrowing down to the most likely marker when the distribution is sharp (peaked). Therefore, top-p sampling produces more natural, diverse, and context-appropriate text than fixed-size methods such as greedy or beam search.
temperature sampling
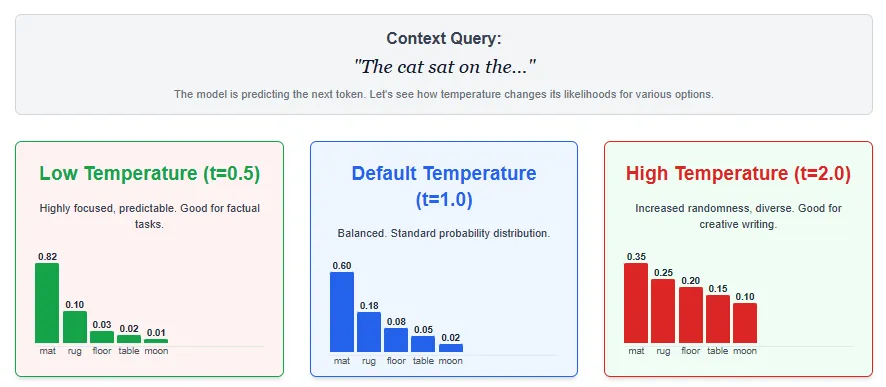
Temperature sampling controls the level of randomness in text generation by adjusting the temperature parameter
Higher temperatures (t > 1) flatten the distribution, introducing more randomness and diversity at the expense of consistency. In practice, temperature sampling can fine-tune the balance between creativity and accuracy: lower temperatures produce deterministic, predictable output, while higher temperatures produce more diverse and imaginative text.
The optimal temperature often depends on the task – for example, creative writing benefits from higher values, while technical or factual responses perform better with lower values.

I am a Civil Engineering graduate (2022) from Jamia Millia Islamia, New Delhi and I am very interested in data science, especially neural networks and their applications in various fields.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


