Prior Labs releases TabPFN-2.5: the latest version of TabPFN that unlocks the scale and speed of tabular base models
Tabular data is still where many important models run in production. Financial, healthcare, energy, and industrial teams use tables with rows and columns instead of images or long text. previous laboratory Now expand this space TabPFN-2.5a new tabular-based model that scales to 50,000 samples and 2,000 features in contextual learning while maintaining a training-free workflow.
From TabPFN and TabPFNv2 to TabPFN-2.5
The first TabPFN shows that Transformer can learn a Bayesian-like inference process on the task of synthetic tables. It can handle up to about 1,000 samples and clean digital features. TabPFNv2 extends this to messy real-world data. It adds support for categorical features, missing values, and outliers, and works with up to 10,000 samples and 500 features.
TabPFN-2.5 is the next generation product in this series. Prior Labs describes it as best suited for datasets with up to 50,000 samples and 2,000 features, with 5x the number of rows and 4x the number of columns compared to TabPFNv2. This provides approximately 20 times the data units in the supported mechanism. This model passes tabpfn Python packages are also available via API.
| aspect | TabPFN (v1) | TabPFNv2 | TabPFN-2.5 |
|---|---|---|---|
| Maximum number of rows (recommended) | 1,000 | 10,000 | 50,000 |
| Maximum functionality (recommended) | 100 | 500 | 2,000 |
| Supported data types | Numbers only | mix | mix |
Contextual learning of tables
TabPFN-2.5 follows the same previous data-fitting network ideas as earlier versions. It is a basic transformer-based model for contextual learning to solve table prediction problems in forward pass. At training time, the model is meta-trained on a large synthetic distribution of tabular tasks. At inference time, you pass the training rows and labels along with the test rows. The model runs a single forward pass and outputs predictions, so there is no dataset-specific gradient descent or hyperparameter search.

Benchmark results for TabArena and RealCause
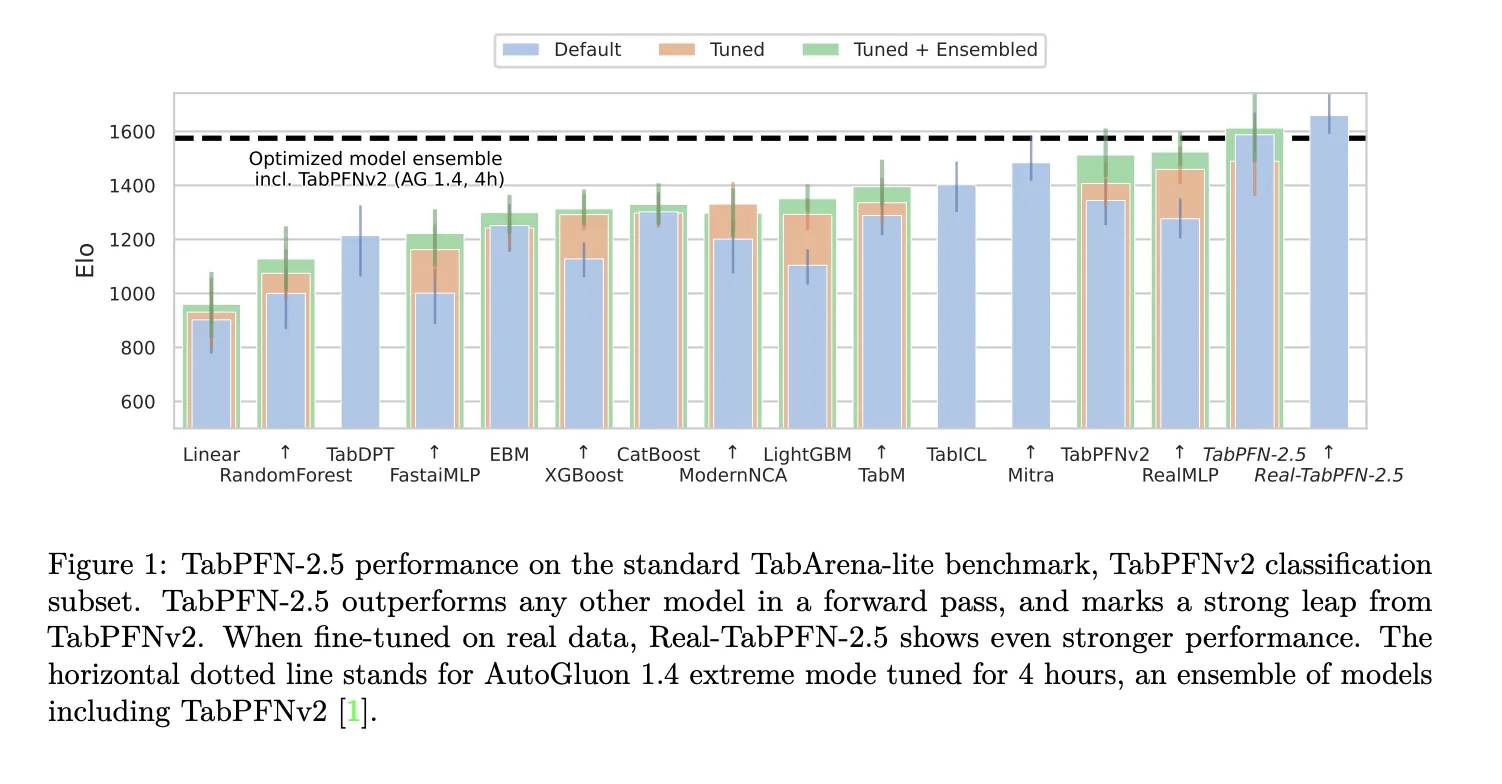
The research team used the TabArena Lite benchmark to measure medium-sized tasks with up to 10,000 samples and 500 features. TabPFN-2.5 performs better in forward propagation than any other model in the comparison. The lead further increases when the Real-TabPFN-2.5 variant is fine-tuned on real datasets. AutoGluon 1.4 in extreme mode is the baseline integration, with 4 hours of tuning, even including TabPFNv2.
On industry-standard benchmarks with up to 50,000 data points and 2,000 features, TabPFN-2.5 significantly outperforms tuning tree-based models such as XGBoost and CatBoost. On the same benchmark, it matched the accuracy of AutoGluon 1.4, which ran a complex four-hour tuning ensemble that included the previous approach.
Model architecture and training settings
The model architecture follows TabPFNv2, with alternating attention and 18 to 24 layers. Alternating attention means that the network pays attention along the sample axis and the feature axis in different stages, which enforces permutation invariance on rows and columns. This design is important for tabular data where row order and column order carry no information.
The training setup retains the previous data-based learning ideas. TabPFN-2.5 uses synthetic tabulation tasks with different priors on functions and data distributions as its meta-training source. Real-TabPFN-2.5 is continuously pretrained on a set of real-world tabular datasets from repositories such as OpenML and Kaggle, while the team is careful to avoid overlap with evaluation benchmarks.
Main points
- TabPFN 2.5 scales the tabular converter of previous data fits to approximately 50,000 samples and 2,000 features while maintaining a single forward pass without requiring workflow adjustments.
- The model is trained on the synthetic tabulation task and evaluated on TabArena, internal industry benchmarks, and RealCause, and performs significantly better than the tuning tree-based baseline and matches AutoGluon 1.4 on benchmarks in this size range.
- TabPFN 2.5 retains the TabPFNv2-style row and feature alternating attention transformer, which enables permutation invariance on tables and contextual learning without the need for task-specific training.
- The distillation engine turns TabPFN 2.5 into a compact MLP or tree ensemble student, retaining most of the accuracy while delivering lower latency and plugging into deployments within existing table stacks.
TabPFN 2.5 is an important release for tabular machine learning because it turns model selection and hyperparameter tuning into a single forward pass workflow for datasets of up to 50,000 samples and 2,000 features. It combines synthetic meta-training, Real-TabPFN-2.5 fine-tuning and distillation engines into MLP and TreeEns students, with clear non-commercial licensing and enterprise paths. Overall, this release makes previous data-fitting networks practical for real tabular problems.
Check Paper, Model weights, repo and technical details. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


: Bringing Modularity and Scalability to LLM Tips")