IBM AI team releases Granite 4.0 Nano series: compact open source small models built for edge AI
Small models are often hampered by poorly tuned instructions, weak tool usage formats, and lack of governance. IBM artificial intelligence team release Granite 4.0 nma small family of models targeting on-premises and edge inference with enterprise control and open licensing. The range includes 8 models in two sizes: 350M and approx. 1B, with mixed SSM and transformer variants, each with base and indication. Granite 4.0 nm Series models are released under the Apache 2.0 license and provide native architecture support on popular runtimes such as vLLM, llama.cpp and MLX

What’s New in the Granite 4.0 Nano Series?
Granite 4.0 nm Consists of four model series and their base versions. Granite 4.0 H 1B uses a hybrid SSM-based architecture with approximately 1.5B parameters. Granite 4.0 H 350M uses the same mixing method at 350M. For maximum runtime portability, IBM also offers Granite 4.0 1B and Granite 4.0 350M as transformer versions.
| granite release | Published dimensions | architecture | Licensing and governance | Main points |
|---|---|---|---|---|
| Granite 13B, the first Watsonx Granite model | 13B basics, 13B guidance, 13B chat later | Decoder transformer only, 8K context | IBM Corporate Terms, Customer Protection | watsonx’s first public Granite model, selected enterprise data, English focus |
| Granite Code Model (Open) | 3B, 8B, 20B, 34B codes, bases and instructions | Decoder Transformer only, 2-stage code training for 116 languages | Apache 2.0 | The first fully open Granite series for code intelligence, paper 2405.04324, available on HF and GitHub |
| Granite 3.0 language model | 2B and 8B, Basics and Guidance | Transformer, 128K instruction context | Apache 2.0 | Business LLM for RAG, Tool Use, Summary, available on WatsonX and HF |
| Granite 3.1 Language Model (HF) | 1B A400M, 3B A800M, 2B, 8B | Transformer, 128K context | Apache 2.0 | Scale ladder of enterprise tasks, including foundation tasks and guidance tasks, the same Granite data recipe |
| Granite 3.2 Language Model (HF) | 2B instruction, 8B instruction | Transformer, 128K, better long tip | Apache 2.0 | Improved iteration quality on 3.x and maintained business consistency |
| Granite 3.3 Language Model (HF) | 2B base address, 2B instruction, 8B base address, 8B instruction, all 128K | Decoder transformer only | Apache 2.0 | The latest 3.x series of HF before 4.0, adding FIM and better instruction following |
| Granite 4.0 language model | 3B micro, 3B H micro, 7B H tiny, 32B H Small, and transformer variants | Hybrid Mamba 2 plus transformer for H, pure transformer for compatibility | Apache 2.0, ISO 42001, cryptographic signature | The beginning of hybrid generation, lower memory, agent-friendly, same governance across scale |
| Granite 4.0 Nano Language Model | 1B H, 1B H indication, 350M H, 350M H indication, 2B transformer, 2B transformer indication, 0.4B transformer, 0.4B transformer indication, 8 in total | The H model is a hybrid SSM plus transformer, and the non-H model is a pure transformer. | Apache 2.0, ISO 42001, signed, same 4.0 pipeline | Minimal Granite model, designed for edge, native and browser, runs on vLLM, llama.cpp, MLX, watsonx |
Structure and training
The H variant interleaves the SSM layer with the transformer layer. This hybrid design reduces memory growth compared to pure attention, while retaining the commonality of the transformer block. The Nano model does not use a simplified data pipeline. They train using the same Granite 4.0 method and over 15T tokens, then adjust the instructions to provide reliable tool usage and instruction following. This extends the advantages of the larger Granite 4.0 models to sub-2B scale.
Benchmarks and Competitive Environment
IBM compared Granite 4.0 Nano to other sub-2B models, including Qwen, Gemma and LiquidAI LFM. A summary of the reports shows significant gains in general knowledge, math, coding and security at similar parameter budgets. On the agent task, these models outperformed several peers on IFEval and Berkeley Function Calling Leaderboard v3.
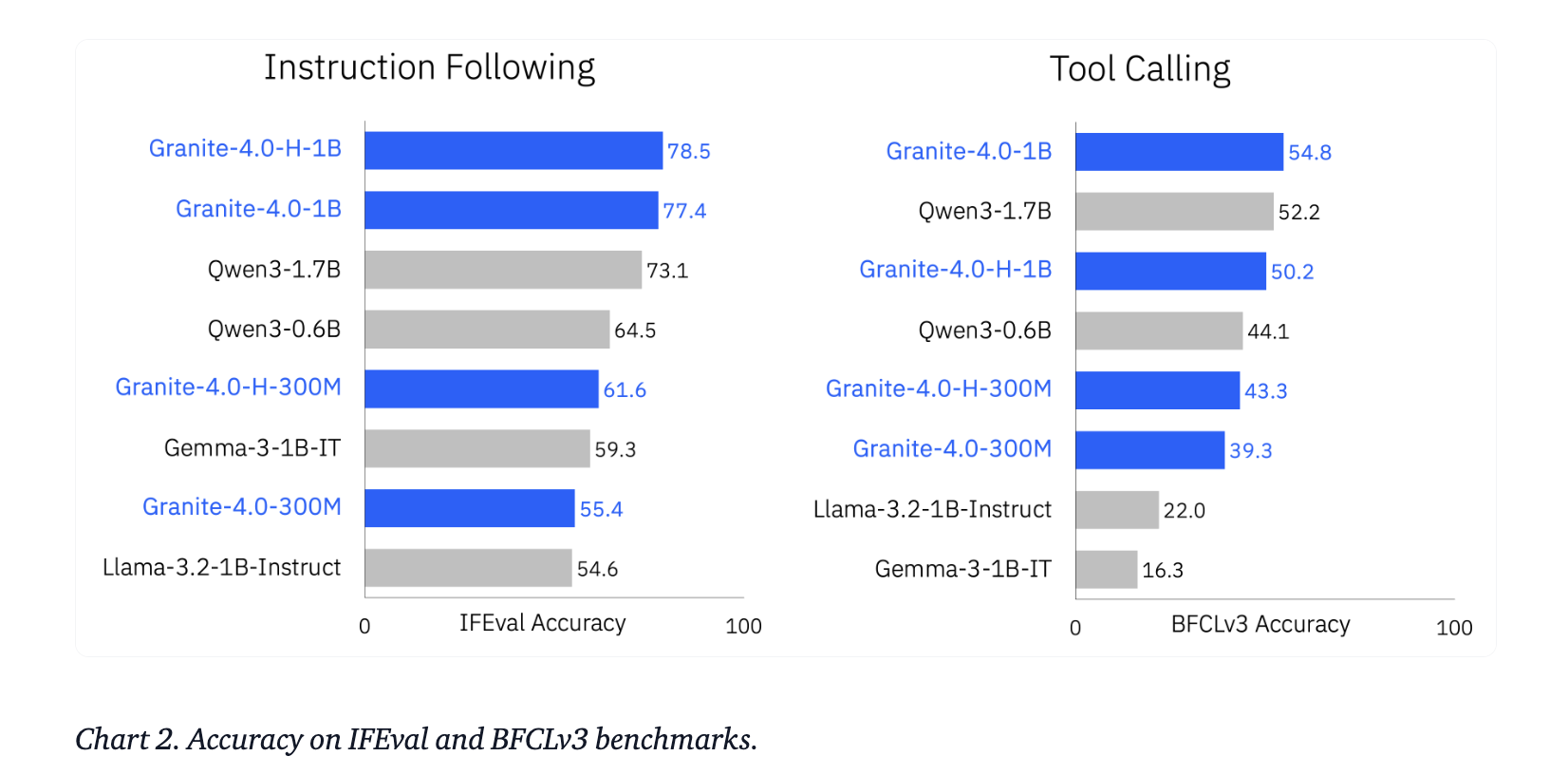
Main points
- IBM released 8 Granite 4.0 Nano models, each model is 350M, about 1B, using mixed SSM and Transformer variants, base and instructions, all under Apache 2.0.
- The hybrid H model (Granite 4.0 H 1B with ~1.5B parameters and Granite 4.0 H 350M with ~350M parameters) reuses the Granite 4.0 training recipe on over 15T tokens, so features are inherited from the larger series rather than reduced data branches.
- The IBM team reports that Granite 4.0 Nano is competitive with other sub-2B models such as Qwen, Gemma, and LiquidAI LFM in terms of generality, math, code, and security, and outperforms IFEval and BFCLv3, which are important for tools that use proxies.
- All Granite 4.0 models, including Nano, are cryptographically signed, ISO 42001 certified, and released for enterprise use, which provides provenance and governance not provided by typical small community models.
- These models are available on Hugging Face and IBM watsonx.ai, with runtime support for vLLM, llama.cpp, and MLX, making local, edge, and browser-level deployment realistic for early-stage AI engineers and software teams.
IBM did the right thing here, it took the same Granite 4.0 training pipeline, the same 15T token scale, the same hybrid Mamba 2 plus transformer architecture, and brought it down to 350M and about 1B so that workloads at the edge and on the device can use the precise governance and provenance stories that the larger Granite model already has. The models are Apache 2.0 compliant, ISO 42001 compliant, cryptographically signed, and ready to run on vLLM, llama.cpp, and MLX. Overall, this is a clean and auditable way to run a small LLM.
Check High frequency model weight and technical details. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


