Examples of 5 common LLM parameters
Large language models (LLMs) provide several parameters that allow you to fine-tune their behavior and control how they generate responses. If the model does not produce the desired output, the problem usually lies in how these parameters are configured. In this tutorial, we will explore some of the most commonly used − Maximum number of completion tokens, temperature, top_p, There is punishmentand frequency penalty – and understand how each factor affects the model’s output.
Install dependencies
pip install openai pandas matplotlibLoad OpenAI API key
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')Initialize model
from openai import OpenAI
model="gpt-4.1"
client = OpenAI()Maximum number of tokens
Maximum number of tokens is the maximum number of tokens that the model can generate during runtime. The model will try to stay within this limit on all rounds. If the specified number is exceeded, the run will be stopped and marked as incomplete.
Smaller values, such as 16, will limit the model to very short answers, while higher values, such as 80, allow the model to generate more detailed and complete responses. Increasing this parameter gives the model more room to formulate, interpret, or format its output more naturally.
prompt = "What is the most popular French cheese?"
for tokens in [16, 30, 80]:
print(f"n--- max_output_tokens = {tokens} ---")
response = client.chat.completions.create(
model=model,
messages=[
{"role": "developer", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
max_completion_tokens=tokens
)
print(response.choices[0].message.content)temperature
In large language models (LLMs), the temperature parameter controls the diversity and randomness of the generated output. Lower temperature values make the model more deterministic and focus on the most likely responses – ideal for tasks that require accuracy and consistency. On the other hand, higher values allow the model to explore less likely options, thereby introducing creativity and diversity. Technically speaking, temperature scales the probabilities of predicted tags in the softmax function: increasing the temperature makes the distribution flatter (the output is more diverse), while decreasing the temperature makes the distribution sharper (the output is more predictable).
In this code, we prompt LLM to give 10 different answers to the same question (n_choices = 10) — “Is there any interesting place worth visiting?? ” — across a range of temperature values. By doing this, we can observe how the diversity of answers changes with temperature. Lower temperatures may produce similar or repeating responses, while higher temperatures will show a broader, more diverse local distribution.
prompt = "What is one intriguing place worth visiting? Give a single-word answer and think globally."
temperatures = [0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.5]
n_choices = 10
results = {}
for temp in temperatures:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
temperature=temp,
n=n_choices
)
# Collect all n responses in a list
results[temp] = [response.choices[i].message.content.strip() for i in range(n_choices)]
# Display results
for temp, responses in results.items():
print(f"n--- temperature = {temp} ---")
print(responses)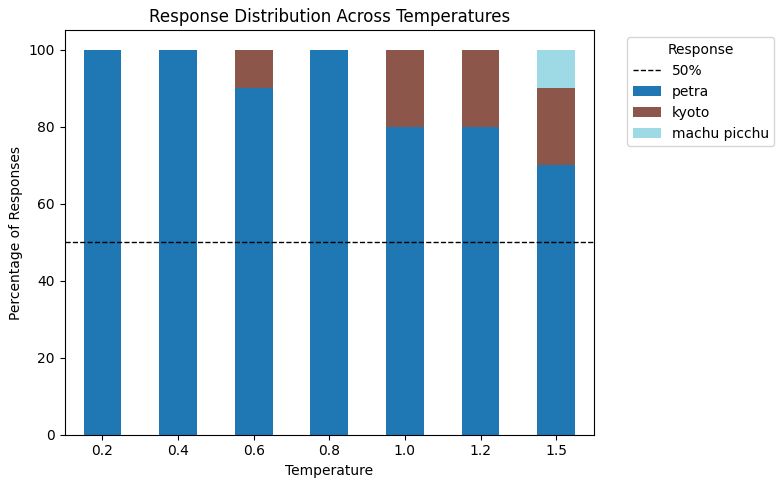
As we can see, as the temperature increases to 0.6, the responses become more diverse, beyond the repeated single answer “Petra”. At higher temperatures of 1.5 the distribution changes and we can see a similar response Kyotoand machu picchu as well as.
Top P
Top P (also known as core sampling) is a parameter that controls how many tokens the model considers based on a cumulative probability threshold. It helps the model focus on the most likely tags, often improving consistency and output quality.
In the visualization below, we first set a temperature value and then apply Top P = 0.5 (50%), which means only the top 50% of the probability mass is retained. Note that when temperature = 0, the output is deterministic, so Top P has no effect.
The generation process is as follows:
- Apply temperature to adjust token probability.
- Use Top P to keep only the most likely tags, which together make up 50% of the total probability mass.
- Renormalize the remaining probabilities before sampling.
We will visualize how the labeling probability distribution changes for different temperature values of the problem:
“Are there any interesting places worth visiting?“
prompt = "What is one intriguing place worth visiting? Give a single-word answer and think globally."
temperatures = [0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.5]
n_choices = 10
results_ = {}
for temp in temperatures:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
temperature=temp,
n=n_choices,
top_p=0.5
)
# Collect all n responses in a list
results_[temp] = [response.choices[i].message.content.strip() for i in range(n_choices)]
# Display results
for temp, responses in results_.items():
print(f"n--- temperature = {temp} ---")
print(responses)
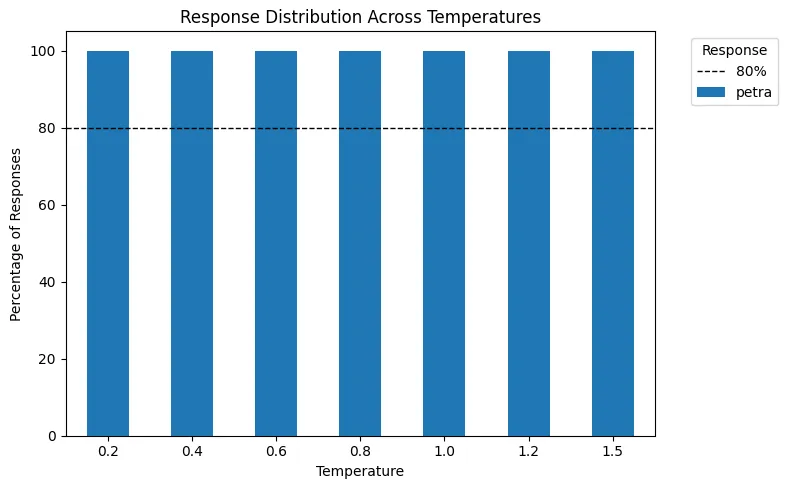
Since Petra always accounts for more than 50% of the total response probability, Top P = 0.5 is applied to filter out all other options. Therefore, the model selects only “Petra” as the final output in each case.
frequency penalty
The frequency penalty controls how much the model avoids repeating the same word or phrase in its output.
Range: -2 to 2
Default value: 0
When the frequency penalty is high, the model is penalized for using words that have been used before. This encourages it to choose new and different words, making the text more diverse and less repetitive.
Simply put, higher frequency penalty = less repetition and more creativity.
We will use the prompt to test:
“List 10 possible fantasy book titles. Give only titles, each on a new line.“
prompt = "List 10 possible titles for a fantasy book. Give the titles only and each title on a new line."
frequency_penalties = [-2.0, -1.0, 0.0, 0.5, 1.0, 1.5, 2.0]
results = {}
for fp in frequency_penalties:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
frequency_penalty=fp,
temperature=0.2
)
text = response.choices[0].message.content
items = [line.strip("- ").strip() for line in text.split("n") if line.strip()]
results[fp] = items
# Display results
for fp, items in results.items():
print(f"n--- frequency_penalty = {fp} ---")
print(items)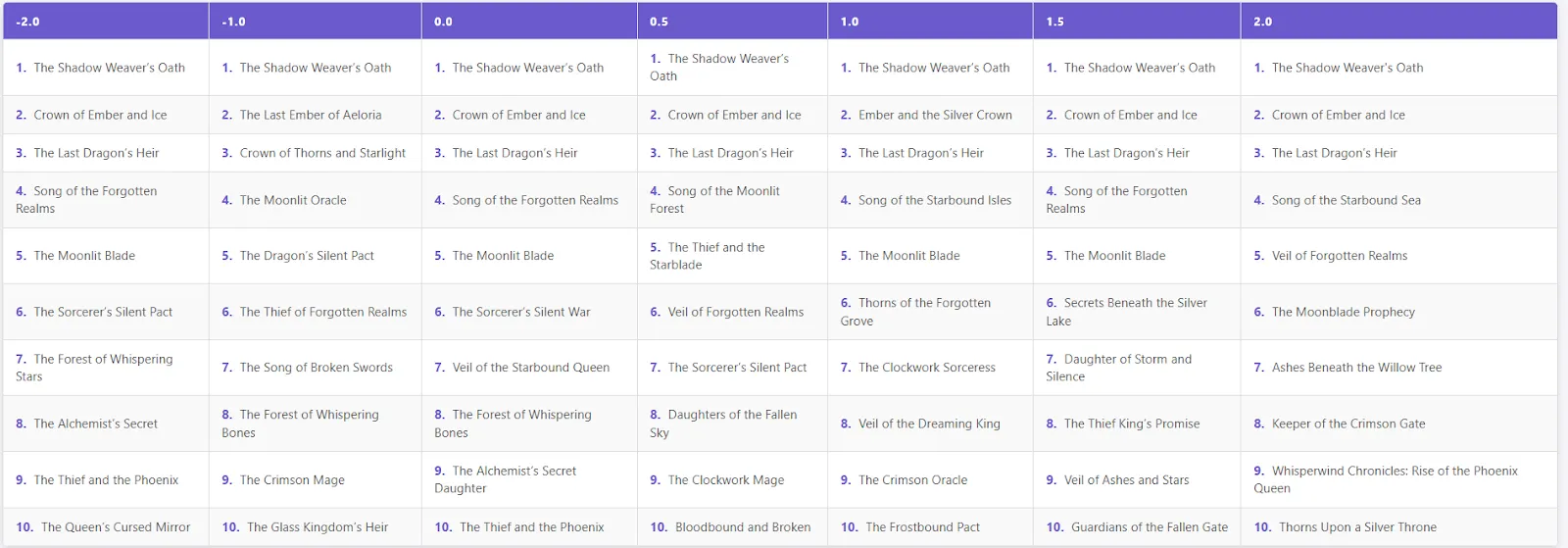
- Low frequency penalty (-2 to 0): Titles tend to be repetitive, with familiar patterns like “Shadowweaver’s Oath,” “Crown of Ash and Ice” and “Heir to the Last Dragon” appearing frequently.
- Medium Penalty (0.5 to 1.5): Some repetitions remain, but the model begins to generate more diverse and creative titles.
- Heavy fines (2.0): The first three titles remained the same, but since then the model has produced titles that are diverse, unique, and imaginative (e.g., Chronicles of the Wind: The Rise of the Phoenix Queen, Ashes Under the Willows).
attendance penalty
Existence penalties control the extent to which the model avoids repeating words or phrases that already appear in the text.
- Range: -2 to 2
- Default value: 0
A higher presence penalty encourages the model to use a wider variety of words, making the output more diverse and creative.
Unlike the frequency penalty, which accumulates with each repetition, the presence penalty is applied once to any word that has already occurred, thereby reducing the chance of it being repeated in the output. This helps the model generate more diverse and original text.
prompt = "List 10 possible titles for a fantasy book. Give the titles only and each title on a new line."
presence_penalties = [-2.0, -1.0, 0.0, 0.5, 1.0, 1.5, 2.0]
results = {}
for fp in frequency_penalties:
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
presence_penalty=fp,
temperature=0.2
)
text = response.choices[0].message.content
items = [line.strip("- ").strip() for line in text.split("n") if line.strip()]
results[fp] = items
# Display results
for fp, items in results.items():
print(f"n--- presence_penalties = {fp} ---")
print(items)
- Low to medium penalty (-2.0 to 0.5): The title is somewhat different, with some riffs on common fantasy patterns such as “Oath of the Shadow Weaver”, “Heir of the Last Dragon”, and “Crown of Ashes and Ice”.
- Medium penalty (1.0 to 1.5): The first few hits are still around, while later games show more creativity and unique combinations. For example: “Ashes of the Fallen Kingdom”, “Secrets of the Astral Forest”, “Daughter of Storm and Stone”.
- Maximum Penalty (2.0): The top three games have remained the same, but the rest have become highly diverse and imaginative. For example: “Moonfire and Thorns”, “Starlight Veil of Ashes”, “Midnight Blade”.
Check The complete code is here. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

I am a Civil Engineering graduate (2022) from Jamia Millia Islamia, New Delhi and I am very interested in data science, especially neural networks and their applications in various fields.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


