DeepSeek just released the 3B OCR model: 3B VLM designed for high-performance OCR and structured document conversion
DeepSeek-AI has released 3B DeepSeek-OCR, an end-to-end OCR and document parsing visual language model (VLM) system that compresses long text into a small set of visual tokens and then uses the language model to decode these tokens. The method is simple and the images carry a compact representation of the text, which reduces the sequence length of the decoder. The research team reports decoding accuracy of up to 97% when text markers are within 10x of visual markers in the Fox benchmark, achieving useful behavior even at 20x compression. It also reports competitive results on OmniDocBench, with far fewer tokens than common benchmarks.
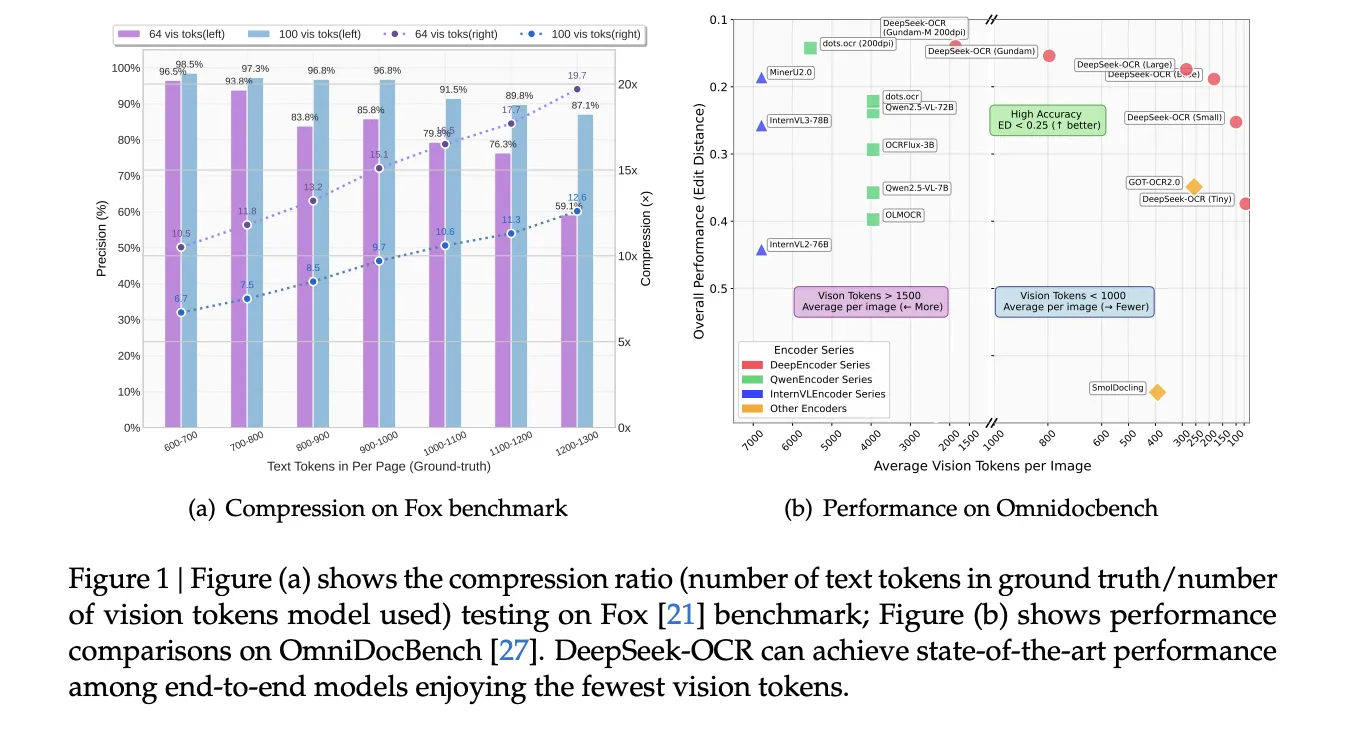
Architecture, what’s new?
DeepSeek-OCR-3B has two components, a visual encoder named DeepEncoder and an expert hybrid decoder named DeepSeek3B-MoE-A570M. This encoder is designed for high-resolution input, has low activation cost and few output tokens. It uses a SAM-based windowed attention stage for local perception, a 2-layer convolutional compressor for 16× token downsampling, and a CLIP-based dense global attention stage for visual knowledge aggregation. This design keeps active memory under high-resolution control and keeps visual token counts low. The decoder is a 3B parameter MoE model (named DeepSeek3B-MoE-A570M) with approximately 570M active parameters per token.
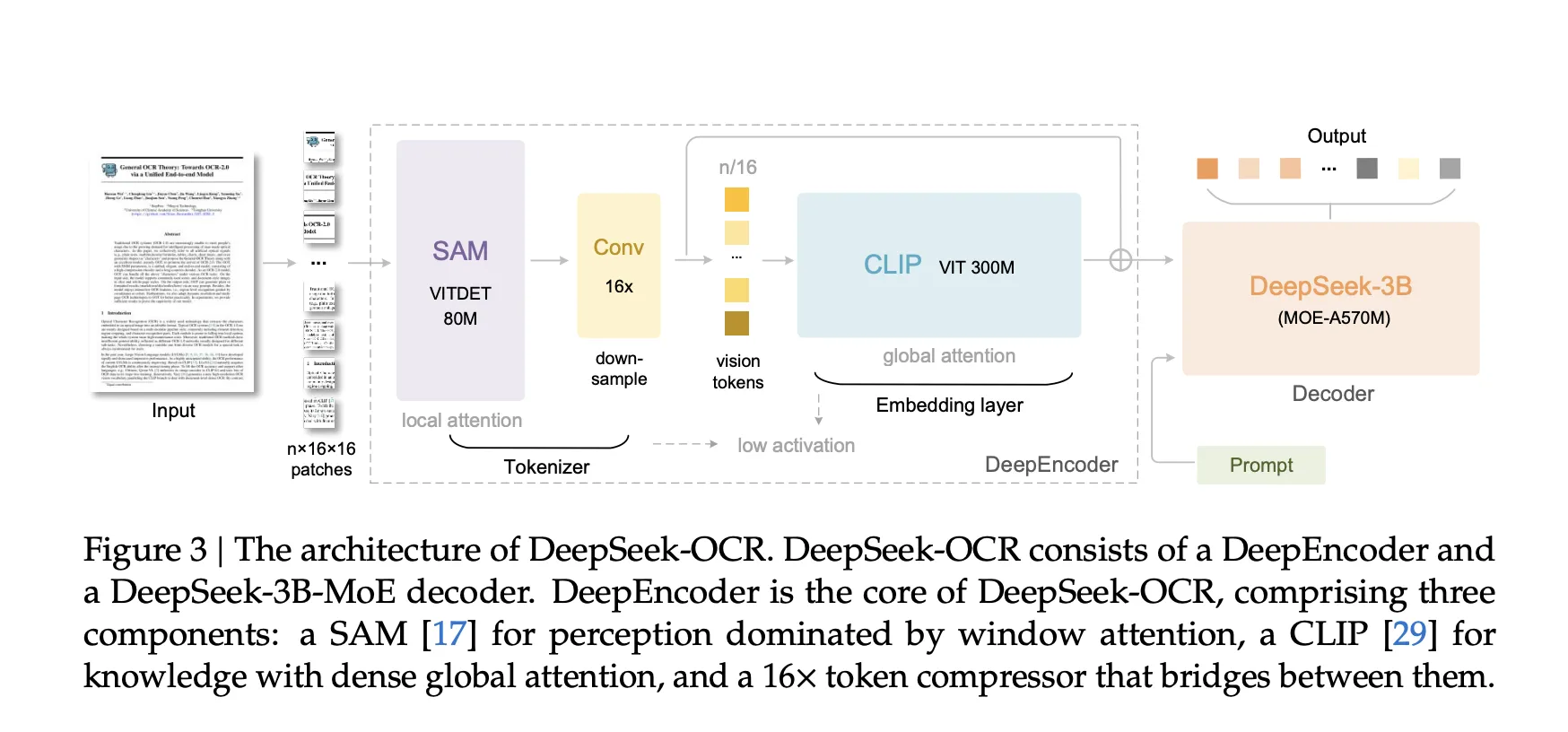
Multi-resolution mode, designed for coin budgets
DeepEncoder supports native mode and dynamic mode. Native modes include 512 x 512 pixel Tiny (with 64 markers), 640 x 640 with 100 markers (Small), 1024 x 1024 with 256 markers (Base), and 1280 x 1280 with 400 markers (Large). Dynamic modes called Gundam and Gundam-Master mix tiled local views with global views. Gundam produces n×100 plus 256 tokens, or n×256 plus 400 tokens, where n ranges from 2 to 9. For fill mode, the research team gave a formula for valid tokens, which is lower than the original number of tokens and depends on the aspect ratio. These modes allow AI developers and researchers to adjust token budgets based on page complexity.

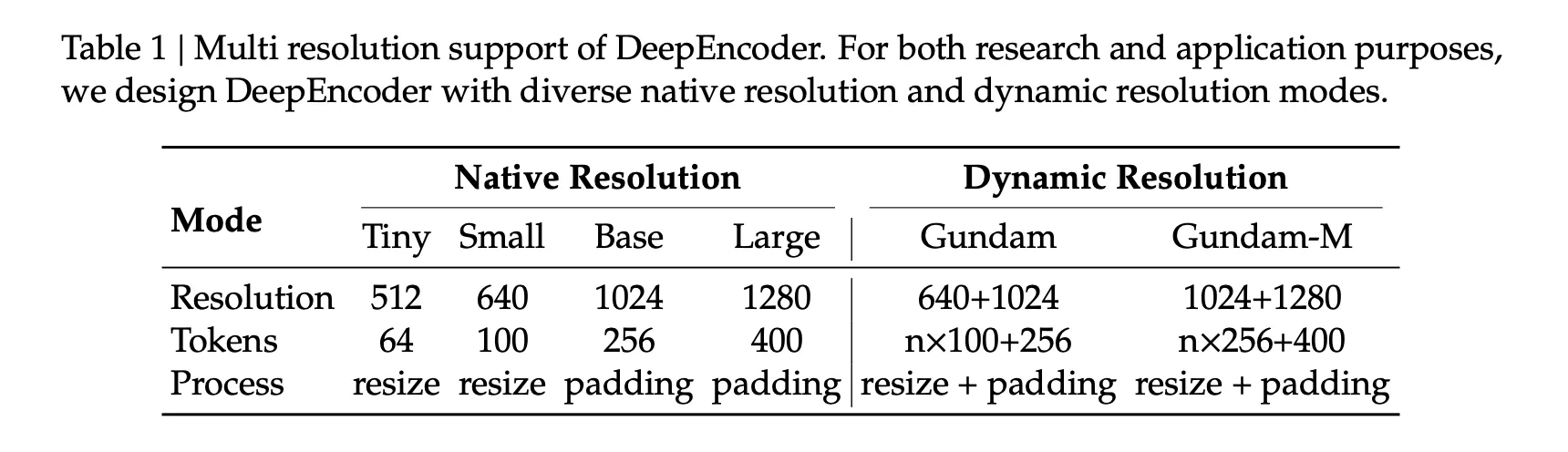
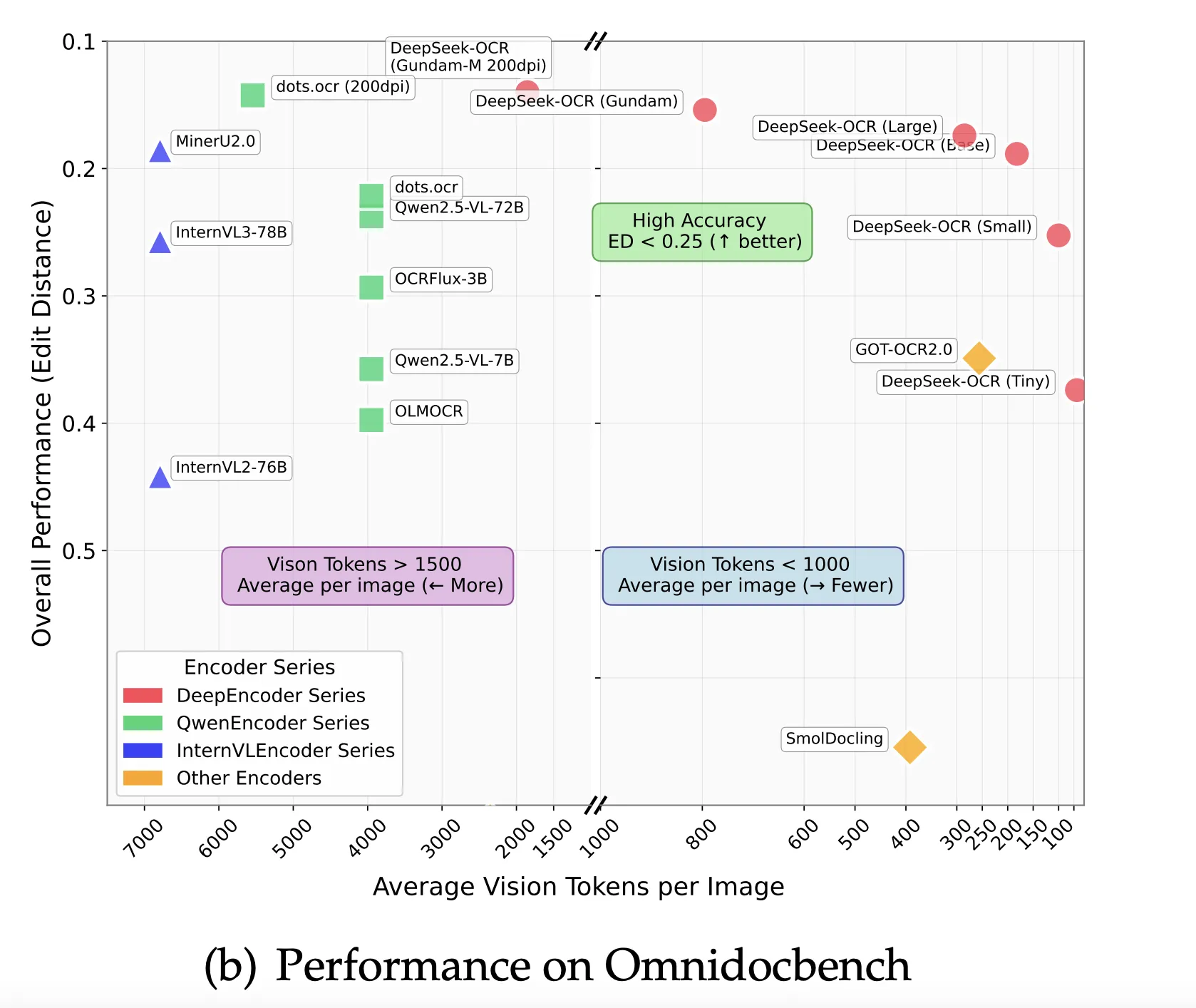
Compression results, what do the numbers say?…
The Fox benchmark study measured accuracy as an exact text match after decoding. With 100 visual markers, a page with 600 to 700 text markers achieves 98.5% accuracy at 6.7x compression. Pages with 900 to 1000 text tags achieved 96.8% accuracy at 9.7x compression. For 64 visual markers, the accuracy decreases with increasing compression, for example, for 1200 to 1300 text markers, the accuracy is 59.1% at around 19.7×. These values come directly from Table 2.
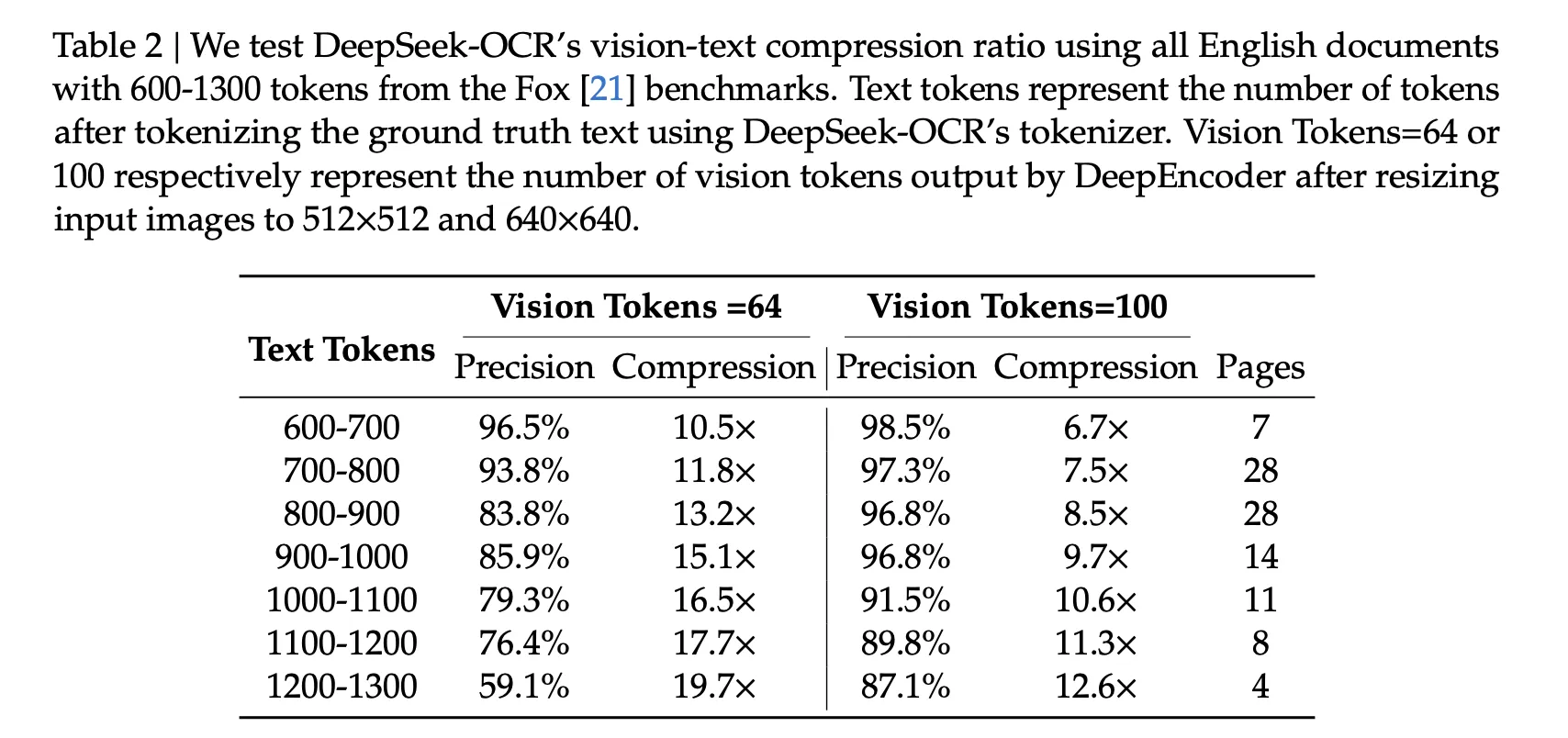
On OmniDocBench, the abstract reports that DeepSeek-OCR outperforms GOT-OCR 2.0 when using only 100 visual tokens per page, while at 800 visual tokens it outperforms MinerU 2.0, which uses over 6000 tokens per page on average. The benchmark section shows the overall performance in terms of edit distance.
Important training details…
The research team describes a two-stage training process. It first trains DeepEncoder on OCR 1.0 and OCR 2.0 data and 100M LAION samples for next token prediction, and then trains the entire system through pipeline parallelism across 4 partitions. For hardware, the run used 20 nodes, each equipped with 8 A100 40G GPUs, and used AdamW. The team reports training speeds of 90B tokens per day for plain text data and 70B tokens per day for multimodal data. In production, it reports the ability to generate over 200k pages per day on a single A100 40G node.
How to evaluate it in real stack
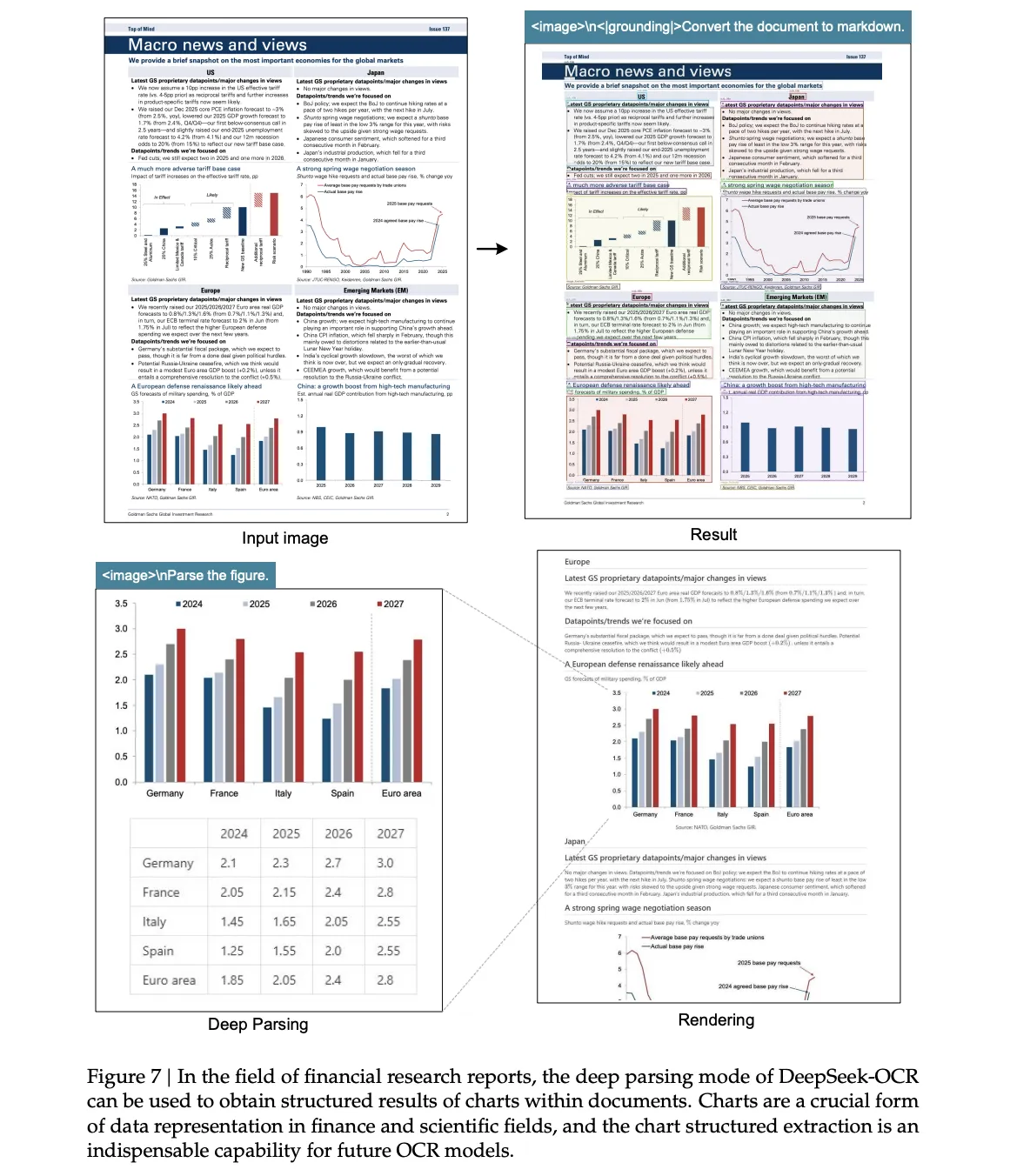
If your target document is a typical report or book, start with a small pattern of 100 marks and only adjust upwards when the edit distance is unacceptable. If your page contains dense small fonts or a very high token count, use Gundam mode as it combines global and local vision with a clear token budget. If your workload includes graphs, tables, or chemical structures, check out the “Deep Dive” qualitative section, which shows conversions of HTML tables and SMILES and structured geometry, and then design output that’s easy to verify.
Main points
- DeepSeek OCR uses optical context compression to achieve token efficiency, enabling near-lossless decoding at approximately 10x compression and approximately 60% accuracy at approximately 20x compression.
- The HF version exposes a clear token budget, with Tiny using 64 tokens at 512 x 512, Small at 640 x 640 using 100 tokens, Base at 1024 x 1024 using 256 tokens, Large at 1280 x 1280 using 400 tokens, and Gundam at 640 x 640. views, plus a global view 1024 times 1024.
- As described in the technical report by the research team, the system architecture is a DeepEncoder that compresses pages into visual tokens and a DeepSeek3B MoE decoder with approximately 570M active parameters.
- The Hugging Face model card documents a tested setup ready for use, Python 3.12.9, CUDA 11.8, PyTorch 2.6.0, Transformers 4.46.3, Tokenizers 0.20.3, and Flash Attention 2.7.3.
DeepSeek OCR is a practical step forward in document AI that treats pages as compact optical carriers, reducing decoder sequence length without discarding most of the information. Model cards and technical reports describe decoding accuracy of 97% on the Fox benchmark at approximately 10x compression, a key statement when tested in real workloads. The model released this time is a 3B MoE decoder with a DeepEncoder front-end, which is packaged for Transformers and has a test version for PyTorch 2.6.0, CUDA 11.8 and Flash Attention 2.7.3, reducing the setup cost of engineers. The repository shows a 6.67 GB safetensors shard, suitable for common GPUs. Overall, DeepSeek OCR uses a 3B MoE decoder for optical context compression, reports approximately 97% decoding accuracy at 10x compression on Fox, provides an explicit token budget model, and includes a tested Transformers setup to verify throughput claims in your own pipeline.
Check Technical Paper, HF Model and GitHub repository. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


