Weak for Strong (W4S): A novel reinforcement learning algorithm that trains weak meta-agents to design agent workflows with stronger LLM
Researchers from Stanford University, Ecole Polytechnique Fédérale de Lausanne and the University of North Carolina introduce Swapping weakness for strength, W4Sa new reinforcement learning RL framework that trains a small meta-agent to design and refine code workflows that invoke more powerful actuator models. The meta-agent does not fine-tune the strong model, it learns to orchestrate it. W4S formalizes workflow design as a multi-round Markov decision process using a process called Reinforcement learning for agent workflow optimization, RLAO. The research team reports consistent gains across 11 benchmarks using a 7B meta-agent trained in approximately 1 GPU hour.
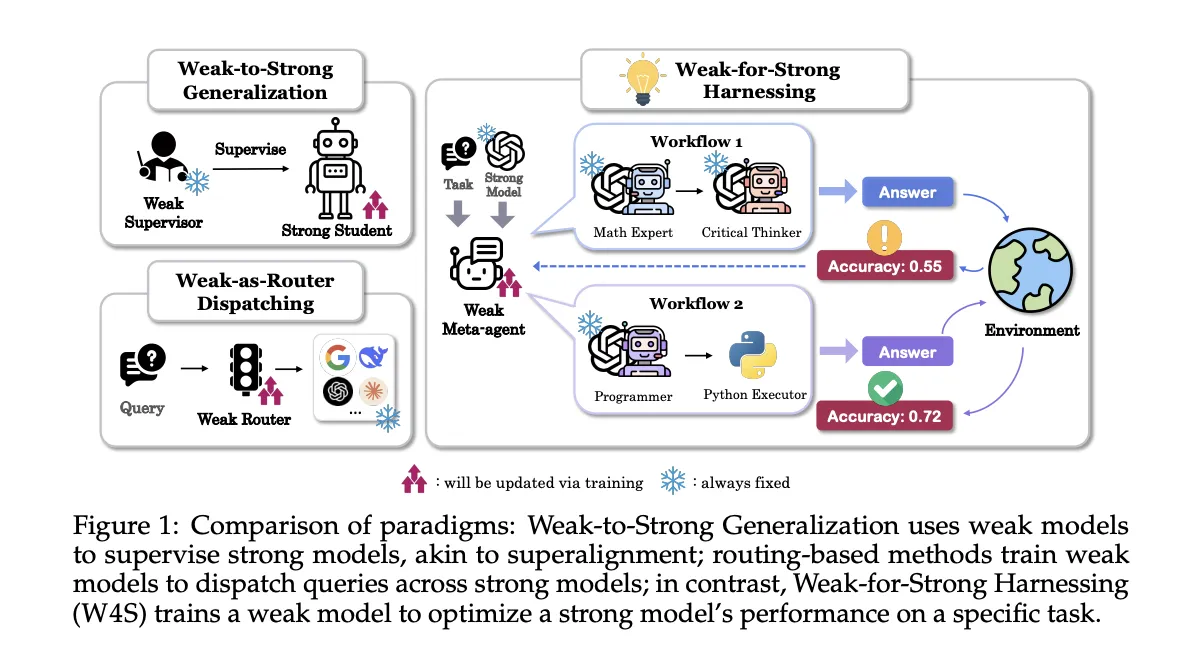
W4S runs in turns. Status contains task instructions, current workflow procedures, and feedback from previous executions. An operation has 2 components: an analysis of what to change and new Python workflow code to implement those changes. The environment executes code on the validation items, returns accuracy and failure cases, and provides new status for the next round. The meta-agent can run a quick self-test on a sample and if an error occurs it will attempt up to 3 repair attempts or skip the operation if the error persists. This loop provides the learning signal without touching the weights of the strong actuators.
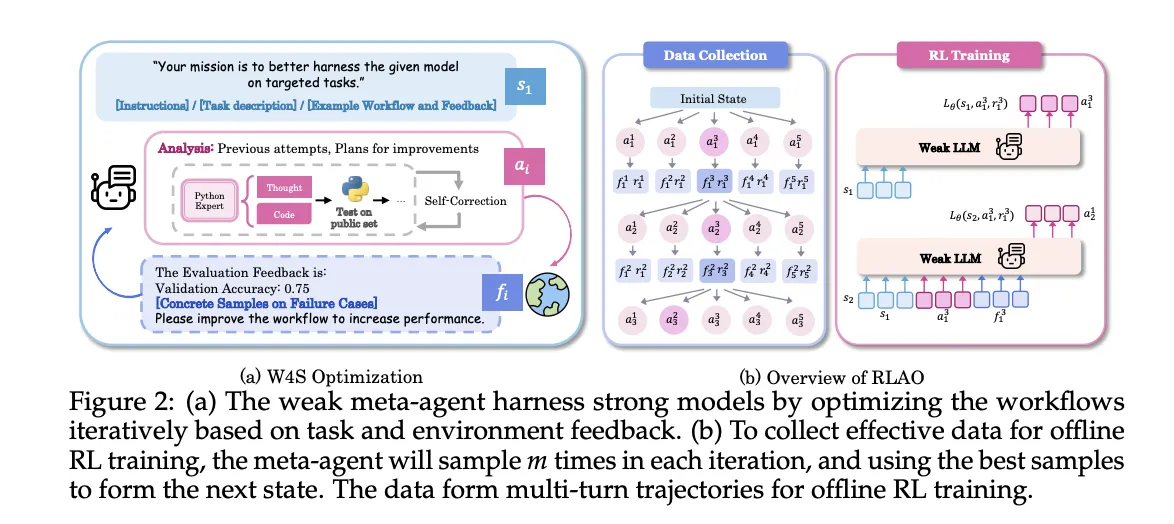
W4S runs as an iterative loop
- Workflow generation: Weak meta-agent writes a new workflow that leverages strong models, expressed as executable Python code.
- Execution and feedback: Strong model executes the workflow on validation samples and then returns accuracy and error cases as feedback.
- refine: The meta-agent uses feedback to update analytics and workflows, then repeats the cycle.
Reinforcement Learning for Agent Workflow Optimization (RLAO)
RLAO is an offline reinforcement learning process for multi-round trajectories. In each iteration, the system samples multiple candidate actions, retaining the best-performing action to advance the state, and storing other actions for training. The strategy is optimized via reward-weighted regression. Rewards are sparse and compare current validation accuracy to history, giving a higher weight when a new result beats the previous best result and a smaller weight when it beats the last iteration. This goal is conducive to steady progress while controlling exploration costs.
Understand the results
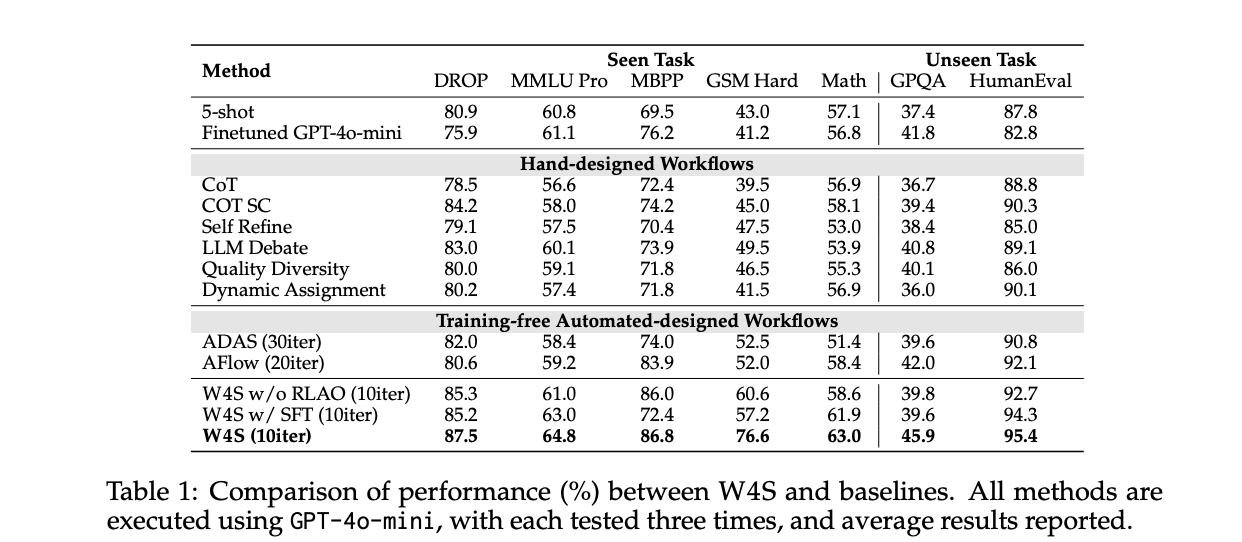
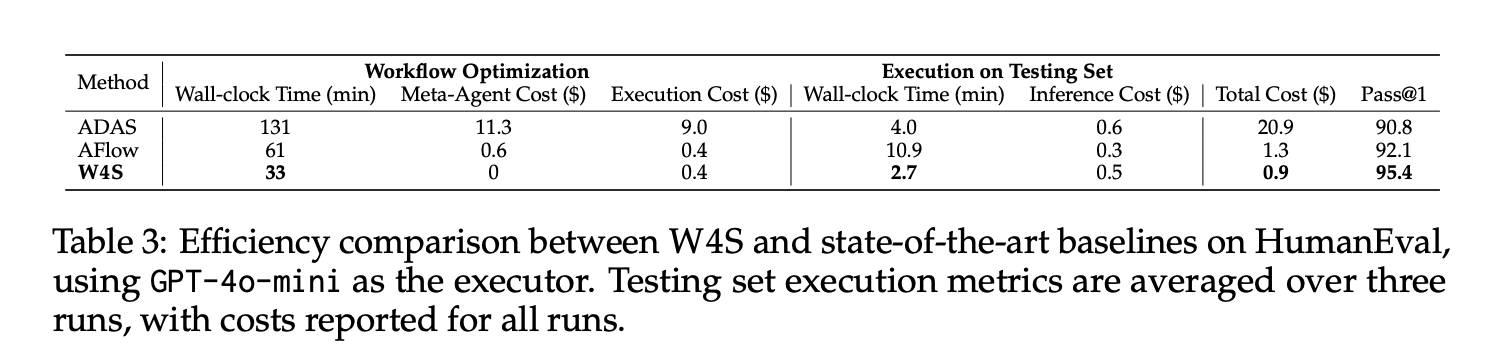
On HumanEval with GPT-4o-mini as the executor, W4S’s Pass@1 score is 95.4, the workflow optimization takes about 33 minutes, the meta-agent API cost is zero, the optimization execution cost is about $0.4, and the execution of the test set of about $0.5 takes 2.7 minutes, totaling about $0.9. AFlow and ADAS track this number under the same actuator. The average reported gains for the 11 benchmarks relative to the strongest automated benchmark ranged from 2.9% to 24.6%.
In terms of math transfer, the meta-agent is trained on GSM Plus and MGSM with GPT-3.5-Turbo as the executor, and then evaluated on GSM8K, GSM Hard and SVAMP. The paper reports scores of 86.5 on GSM8K and 61.8 on GSM Hard, both higher than the automatic baseline. This shows that the learned orchestration can be transferred to related tasks without retraining the actuators.
On the tasks seen with GPT-4o-mini as the executor, W4S outperforms training-free automation methods that do not learn planners. The study also ran ablation, where the meta-agent was trained with supervised fine-tuning instead of RLAO, which produced better accuracy under the same computational budget. The research team established a GRPO baseline on GSM Hard’s 7B weak model, and W4S outperformed it under limited computation.
Iteration budget is important. The research team set up W4S to run about 10 rounds of optimization on the main table, while AFlow ran about 20 rounds and ADAS ran about 30 rounds. W4S achieves greater accuracy despite fewer turns. This suggests that learned code planning combined with verification feedback makes searching for samples more efficient.
Main points
- W4S uses RLAO to train 7B weak meta-agents to write Python workflows, using stronger executors, modeled as multi-round MDP.
- On HumanEval using GPT 4o mini as the executor, W4S achieved a Pass@1 of 95.4, the optimization time was about 33 minutes, and the total cost was about $0.9, beating the automation baseline under the same executor.
- Across 11 benchmarks, W4S outperforms the strongest baseline by 2.9% to 24.6% while avoiding fine-tuning of the strong model.
- The method runs an iterative loop, generates the workflow, executes it on the validation data, and then uses feedback to refine it.
- ADAS and AFlow can also program or search code workflows, W4S differs by training planners through offline reinforcement learning.
W4S targets orchestration, not model weights, and trains 7B meta-agents to program workflows that invoke stronger executors. W4S formalizes the workflow design as a multi-round MDP and optimizes the planner through RLAO using offline trajectories and reward-weighted regression. Reported results show that HumanEval using GPT 4o mini achieves a Pass@1 score of 95.4, an average gain of 2.9% to 24.6% across 11 benchmarks, and a meta-agent training time of approximately 1 GPU hour. The framework provides a clear comparison with ADAS and AFlow, which search agent designs or coding graphs, while W4S fixes the actuators and learns the planner.
Check technical paper and GitHub repository. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex data sets into actionable insights.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.

 voice recognition model")
