AutoCode: A new artificial intelligence framework that allows LL.M.s to create and validate competitive programming problems, mirroring the workflow of human problem setters
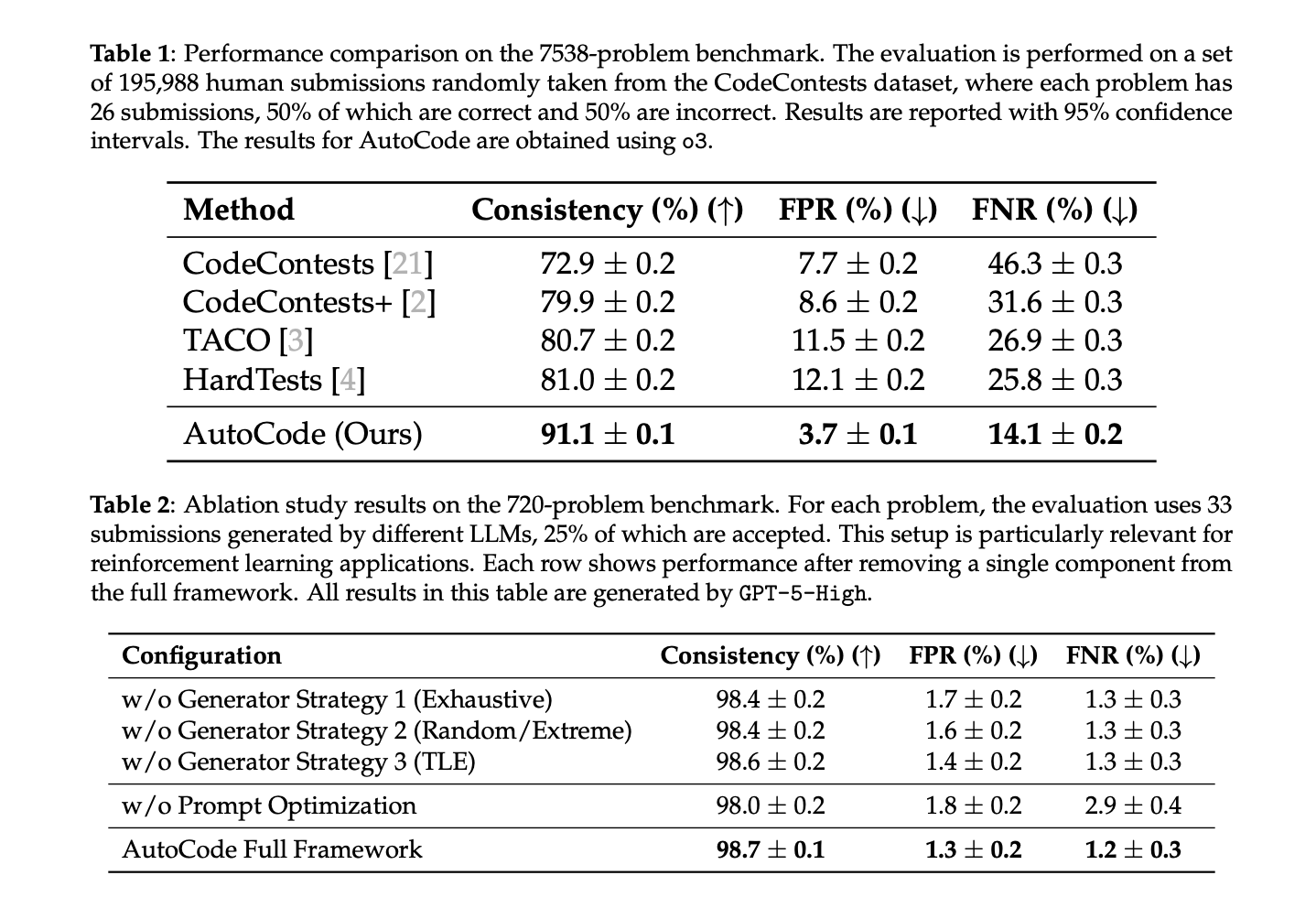
Do your LLM code benchmarks actually reject solutions of wrong complexity and interactive protocol violations, or do they pass unspecified unit tests? Introducing a team of researchers from UC San Diego, New York University, University of Washington, Princeton University, Canyon Crest Academy, OpenAI, UC Berkeley, MIT, University of Waterloo, and Sentient Labs automatic codinga new artificial intelligence framework that allows LL.M.s to create and validate competitive programming problems that mirror the workflow of human problem setters. AutoCode processes to reconstruct the evaluation of code reasoning models Question setting (not just problem solving) as target tasks. The system trains LL.M.s to produce competitive-grade products statement, test dataand decision logic The match rate with official online judges is high. On a 7,538-question benchmark built on a previous dataset, AutoCode achieved Consistency 91.1% And there is an official judgment (FPR 3.7%, FNR 14.1%). alone, more difficult 720 recent Codeforces questions (including interactive tasks), full framework report 98.7% consistency, 1.3% pre-shrinkage, 1.2% FNR.
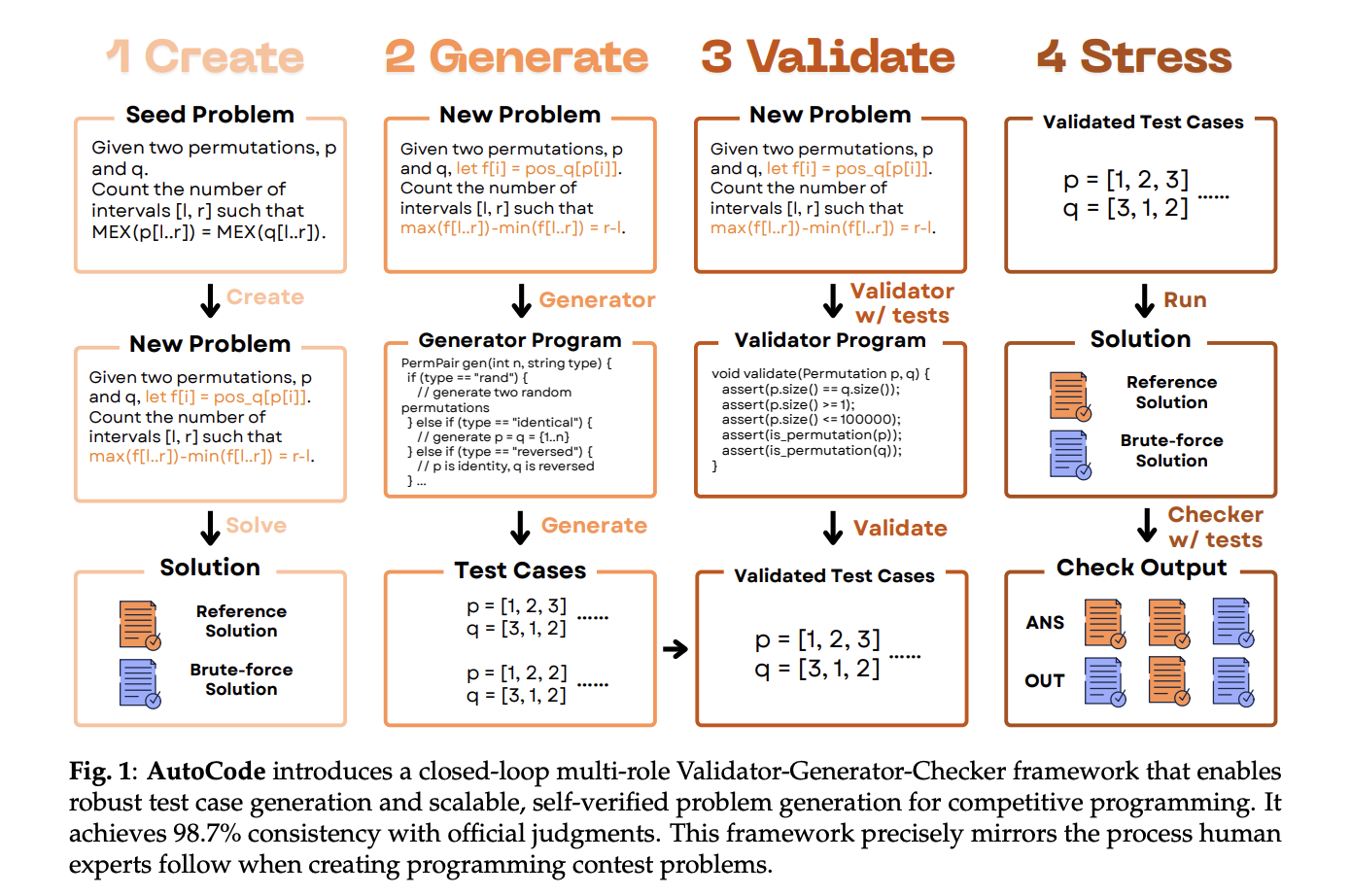
Why is problem setting important for assessment?
Public code benchmarks often rely on unspecified tests, allowing false complexity or shortcut solutions to pass. This inflates scores and taints reinforcement signals (rewarding flimsy tactics). automatically encoded Verifiers take priority methods and adversarial test generation designed to reduce False positive (FPR)— error procedures passed — and False Negative (FNR)– The correct program was rejected due to incorrect input format.
Core loop: validator → generator → checker
AutoCode runs a closed loop that mirrors the human competition workflow, but each step starts with Candidates generated by LLM Use targeted in-frame testing.
1) Validator (minimizes FNR by forcing input legality)
The system first requires LLM synthesis 40 evaluation inputs—10 valid and 30 Nearly Effectively Illegal (e.g., a boundary violation that differs by one). Then it will prompt LLM Three candidate verification programs and select the case that best categorizes these cases. This prevents the “correct” solution from crashing due to malformed data.

2) Generator (reducing FPR through adversarial coverage)
Three complementary strategies generate test cases:
• small data exhausted For boundary coverage,
• random + extreme conditions (overflow, precision, hash collision),
• TLE induced Breaking down the structure of error complexity solutions.
Invalid cases are filtered by the selected validator; the cases are then deduplicated and bucket balanced before sampling.

3) Checker (decision logic)
The inspector compares the contestant’s output with reference solution under complex rules. AutoCode is generated again 40 inspection scenarios and Three candidate checking proceduresonly scenarios with validator-approved inputs are kept, and the best checker is selected based on the accuracy of the 40 labeled scenarios.

4) Interactor (for interaction problems)
For tasks that require a conversation with a judge, AutoCode introduces mutation-based interactors: It makes small logical edits (“mutants”) of the reference solution, select the interactor embrace real solutions but reject mutantsmaximize discrimination. This addresses the gap in earlier public datasets to avoid interactions.

Two-step verification can solve new problems (not just test existing ones)
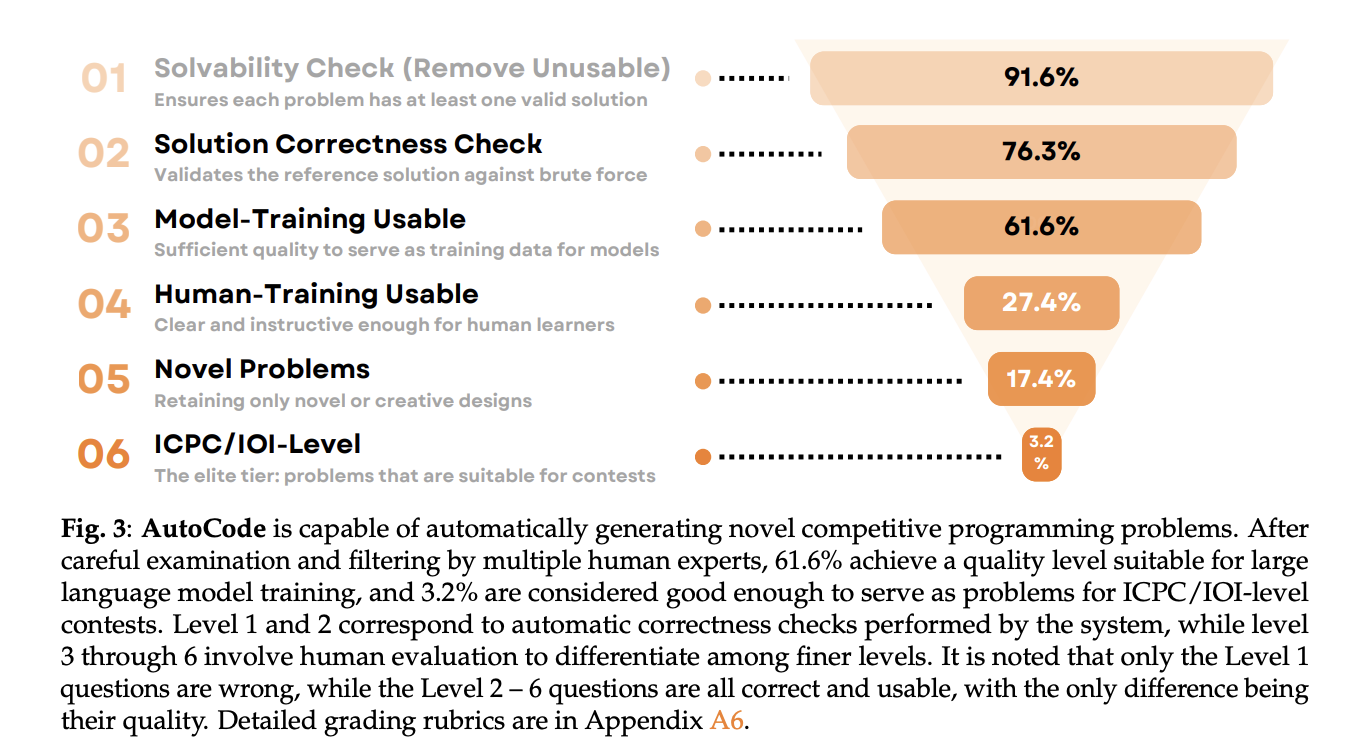
Automatic encoding can generate Novel problem variations Start with a random “seed” Codeforces problem (two solutions: an efficient refer to and a simpler Brute force cracking baseline. Only if the reference output Contest Brute force the generated test suite (brute force may fail in large cases, but will serve as ground truth in small/exhaustive cases). this Two-step verification protocol filter ~27% Error-prone projects, improving the correctness of reference solutions 86% → 94% before manual review.
Human experts then rated the survivors Solvability, solution correctness, quality, novelty, difficulty. After filtering, 61.6% Available for Model training, 76.3% for manpower trainingand 3.2% yes ICPC/IOI level question. Difficulty typically increases relative to the seed, and the difficulty gain correlates with perceived quality.
Understand the results
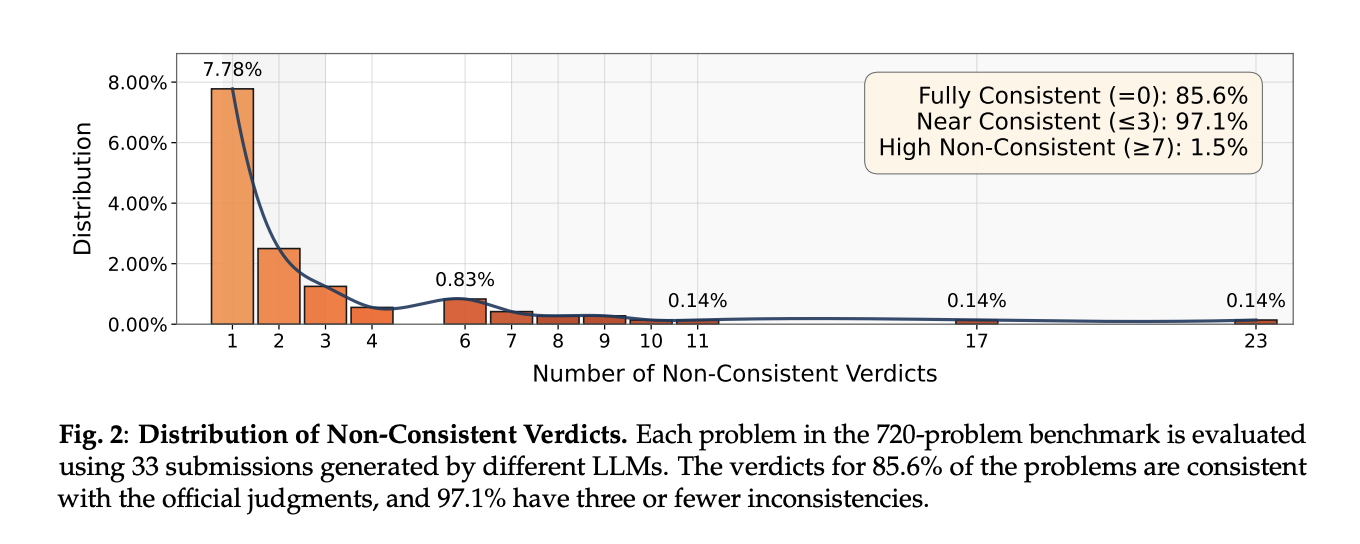
Current questions (7,538 total; 195,988 submissions). Automatic encoding: Consistency 91.1%, 3.7% pre-shrinkage, 14.1% FNRthe consistency with previous generators (CodeContests, CodeContests+, TACO, HardTests) is 72.9–81.0%.
Recent Codeforces issues (720, unfiltered; includes interactions). Automatic encoding: 98.7% consistency, 1.3% pre-shrinkage, 1.2% FNR. Ablation shows all three generator strategies and Timely optimization Contribution: Removing hint optimization reduces consistency 98.0% and more than twice FNR arrive 2.9%.
Main points
- AutoCode combines validator-generator-checker (+interactor) loop with Two-factor authentication (reference vs. brute force) Build competition-grade test suites and new problems.
- For open questions, AutoCode’s test suite reaches ~99% consistent Compared with the official review, surpassing previous generators such as HardTests (
- for the latest code power Tasks (including interactions), full framework reports ~98.7% consistency and ~1.3% FPR and ~1.2% FNR.
- this mutation-based interactors Improve the evaluation of interactive problems by reliably accepting true solutions while rejecting mutated variants.
- Human experts rated a large proportion of AutoCode-generated projects as training available and an extraordinary share Competition qualityconsistent with the goals of the LiveCodeBench Pro program.
AutoCode is a practical fix for current code bases. it concentrates Question setting and use closed loop validator-generator-checker (+interactor) Pipeline vs. Two-step verification (reference to violence). This structure reduces False positive/false negative and produce results consistent with the judge’s consistency (For unresolved issues, about 99%; 98.7% About recent Codeforces, including interactions). This method standardizes constraint legality, adversarial coverage, and protocol-aware judgments, which makes downstream RL reward signals clearer. its placed in LiveCodeBench Professional Edition Suitable for antihallucination assessment procedures that emphasize the rigor of expert examination.
Check Paper and project. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


