S-Shaped Scaling Curve Makes LLM’s Reinforcement Learning RL Predictable After Training
Reinforcement Learning RL post-training is now the primary lever for inference-focused LL.M., but unlike pre-training it is not yet predictive Scaling rules. The team put tens of thousands of GPU hours into the run without a principled way to estimate whether the recipe would continue to improve with more computation. A new study from Meta, the University of Texas at Austin, University College London, Berkeley, Harvard University, and Periodic Labs provides Computing Performance Framework– Validate over >400,000 GPU hours——Use a model to simulate the progress of reinforcement learning S-shaped curve and provide tested formulas, scaleRLfollow these prediction curves until 100,000 GPU hours.
Fit sigmoid, not power law
Pretraining usually follows a power law (loss vs. computation). RL fine-tuning target bounded metric (e.g. pass rate/average award). Research team presentation S-shaped fit arrive Pass rate and training calculation It’s based on experience Stronger and more stable Better than a power law fit, especially when you want extrapolating from smaller runs Bigger budget. They exclude very early, noisy regimes (~first 1.5k GPU hours) and fit the next predictable part. The sigmoidal parameter has an intuitive effect: setting Asymptotic performance (upper limit),another Efficiency/indexand another midpoint Where are the quickest gains?
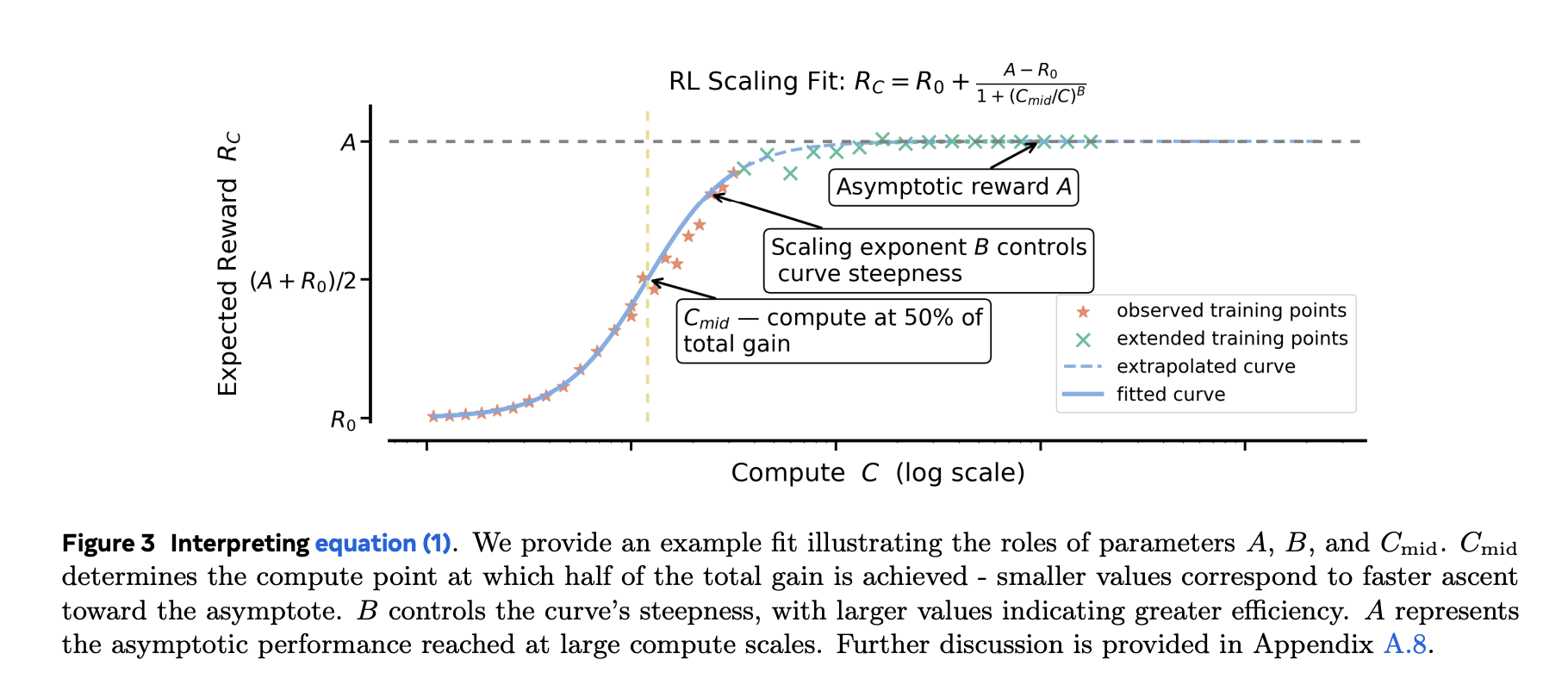
Why this is important: After about 1–2k GPU hours you can fit a curve and predict whether it’s worth pushing to 10k–100k GPU hours —forward You burned your budget. Research has also shown that power law fitting can give misleading upper bounds unless you only perform the fitting at very high calculations, which defeats the purpose of early prediction.
ScaleRL: Recipes for predictable scaling
ScaleRL isn’t just a new algorithm; Selected composition The study yielded stable, inferable scaling:
- Asynchronous Pipeline Reinforcement Learning (generator-trainer split across GPUs) to achieve off-policy throughput.
- CISPO (Truncated Importance-Sampling Augmentation) as RL loss.
- FP32 logic precision to avoid numerical mismatch between generator and trainer.
- Immediate level loss average and Batch-Level Advantage Standardization.
- forced length break to limit traces of loss of control.
- zero variance filtering (Remove hint for not providing gradient signal).
- No positive resampling (High pass rate tips ≥0.9 are removed from later epochs).
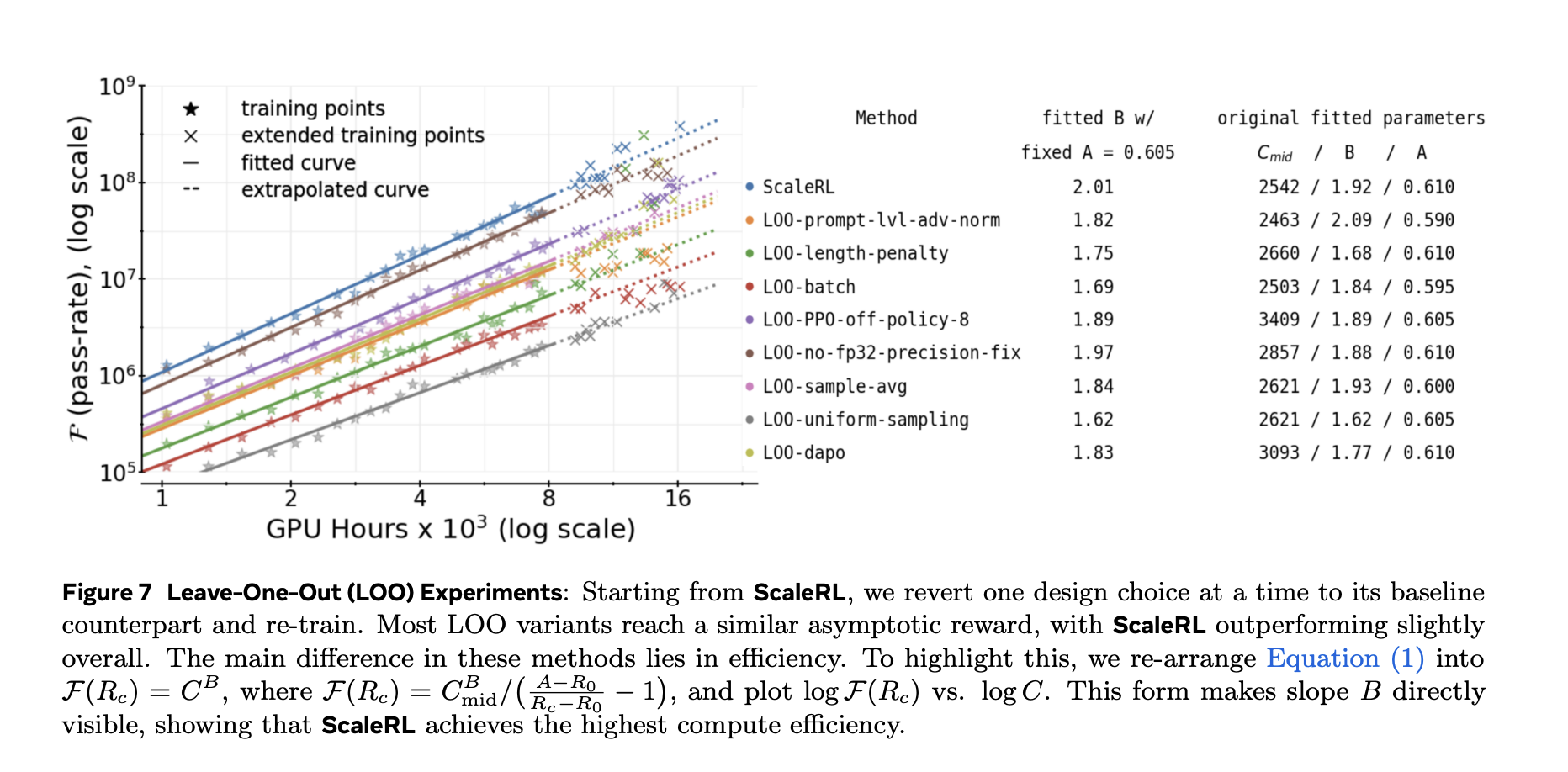
The research team verified each component Leave-one-out (LOO) ablation exist 16k GPU hours And it shows that ScaleRL’s fitting curve is reliable infer from 8k → 16kand then maintained at larger scales—including single-run extensions to 100k GPU hours.
Results and summary
Two key demonstrations:
- Predictability at scale: for a 8B secret model and a Llama-4 17B×16 MoE (“Scout”)this extended training Pay close attention sigmoid extrapolation Derived from smaller computational segments.
- Downstream transport: iid validation set pass rate improvement track Downstream assessment (e.g. AIME-24), indicating that the computational performance curve is not a data set artifact.
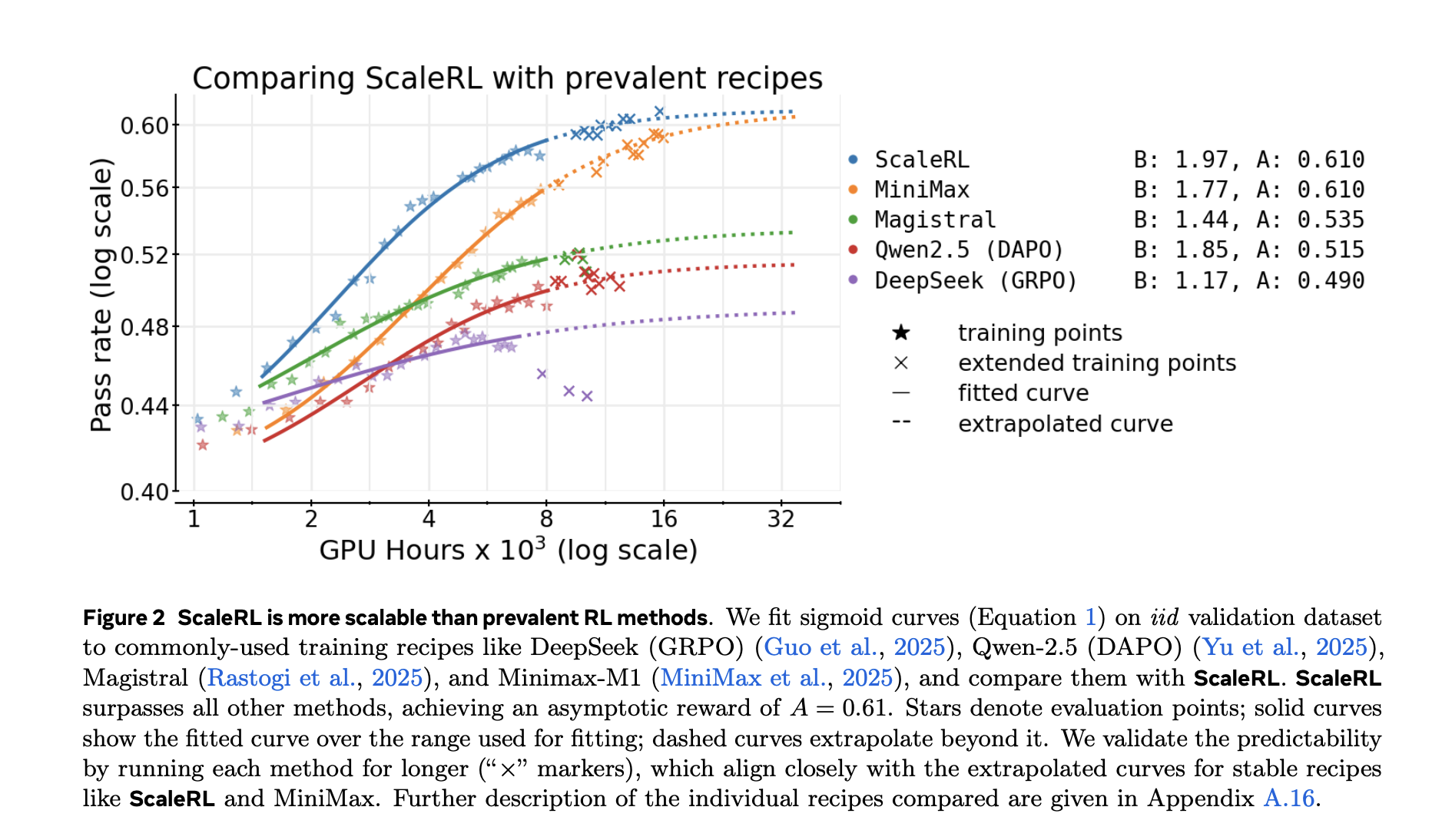
The study also compared fitted curves for popular recipes (e.g. DeepSeek (GRPO), Qwen-2.5 (DAPO), Magistral, MiniMax-M1) and reports Higher asymptotic performance and better computational efficiency Use ScaleRL in their setup.
Which knobs improve efficiency?
This framework allows you to categorize design choices:
- Ceiling mover (asymptote): Zoom Model size (e.g. Ministry of Education) and longer generation length (most 32,768 tokens)improve gradual performance, but may slow down early progress. Larger global batch size It also improves the final asymptote and stabilizes training.
- Efficiency Shaper: loss aggregation, Advantages of standardization, data course,as well as Out-of-policy channels mainly changes how fast You’re approaching the ceiling, not the ceiling itself.
Operationally, the research team recommends Fit curves early and identify priority interventions to improve ceilingthen adjust efficiency Knob to reach it faster at fixed calculations.
Main points
- Research team models progress after reinforcement learning training S-shaped computing performance curve (pass rate versus log calculation), enabling reliable extrapolation—unlike power law fitting on bounded metrics.
- best practice recipes, scaleRLcombine Pipe RL-k (asynchronous generator-trainer), CISPO loss, FP32 logical numberprompt-level aggregation, dominance normalization, break-based length control, zero-variance filtering, and non-positive resampling.
- Using these fits, the research team predict and match Extended operating time up to 100k GPU hours (8B dense) and~50k GPU hours (17B×16 MoE “Scout”) on the verification curve.
- ablate Show some selection moves Asymptotic upper limit (A) (e.g., model size, longer generation length, larger global batches), while other major improvements Computational efficiency(B) (e.g. aggregation/standardization, curriculum, off-policy channels).
- The framework provides early forecast Decisions on whether to extend the run and improvements to validation within distributions Track downstream metrics (e.g., AIME-24), supporting external validity.
This work transforms RL training from trial and error to predictable engineering. It fits an S-shaped compute performance curve (pass rate vs. logarithmic calculation) to predict returns and decide when to stop or expand. It also provides a concrete solution, ScaleRL, which uses PipelineRL-style asynchronous generation/training, CISPO loss, and FP32 logits to ensure stability. The study reports over 400,000 GPU hours of experiments, with single runs extending to 100,000 GPU hours. The results support a clear split: some choices raise the asymptote; some choices cause the asymptote to fall. Others mainly improve computational efficiency. This separation helps teams prioritize changes in ceiling movement before adjusting the throughput knob.
Check Paper. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


