Meta AI’s “early access” trains language agents without rewards and outperforms imitation learning
How would your agent stack change if a policy could be trained purely on its outcome-based deployment (no rewards, no demonstrations) but beat imitation learning on eight benchmarks? Yuan Super Intelligence Laboratory proposed “early experience”, a reward-free training method that improves policy learning for language agents without the need for large sets of human demonstrations and without reinforcement learning (RL) in the main loop. The core idea is simple: let the agent branch out from the expert state, take its own actions, collect the resulting future stateand translate those consequences into oversight. The research team instantiates this through two specific strategies—Implicit World Modeling (IWM) and Self-Reflection (SR)– and reported consistent gains across eight environments and multiple base models.
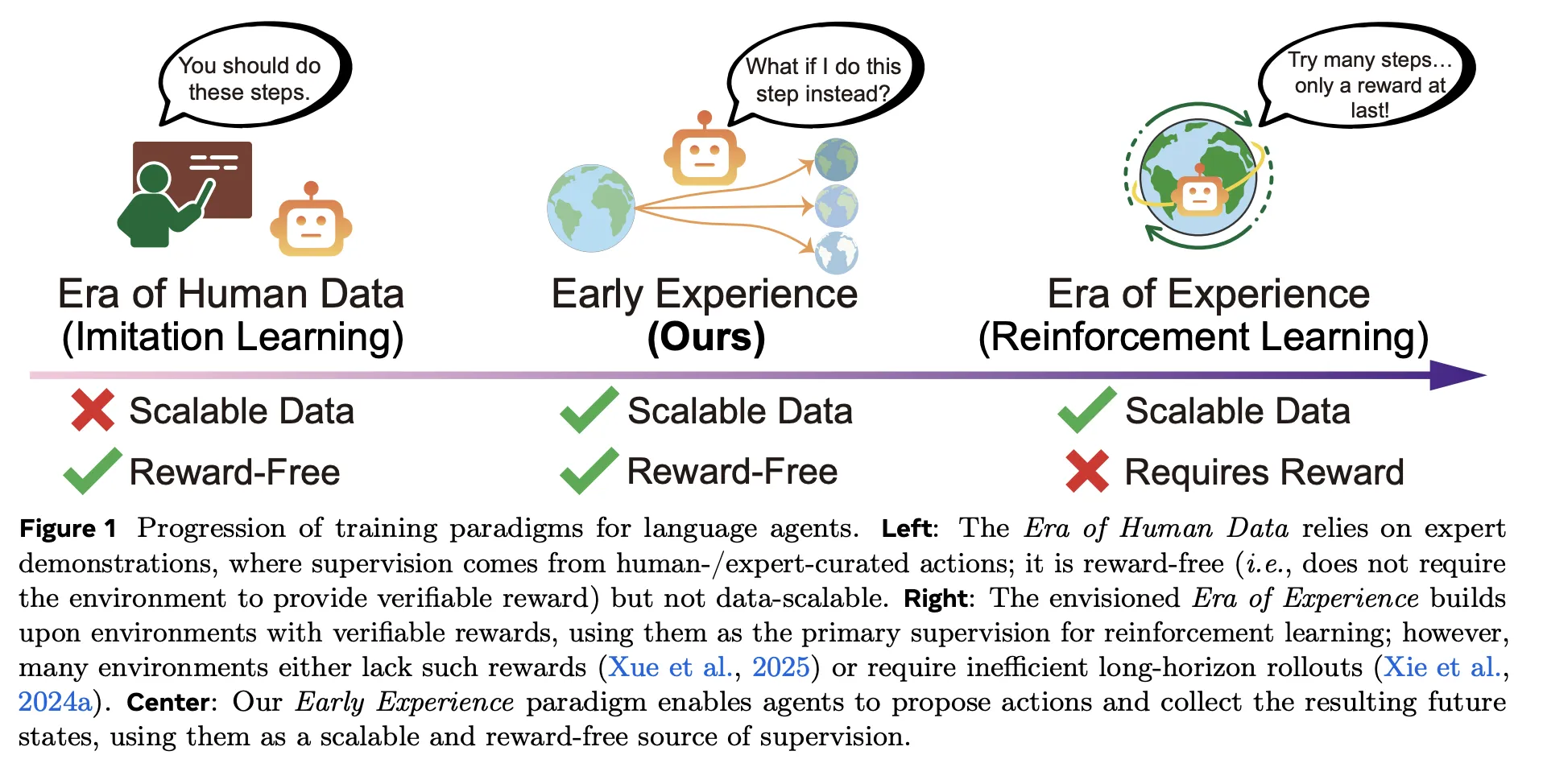
How has the early experience changed?
Traditional pipelines rely on Imitation Learning (IL) Beyond expert trajectories, optimization is cheap, but difficult to scale and fragile outside of distribution; Reinforcement Learning (RL) Commits to learning from experience, but requires verifiable rewards and stable infrastructure – something often missing in web and multi-tool settings. early experience Sitting between them: it is Unpaid like Imitation Learning (IL)but the basis for supervision is the consequences of the agent’s own actionsnot just the actions of experts. In short, the agent makes recommendations, takes action, and learns from what actually happens next—no reward function required.
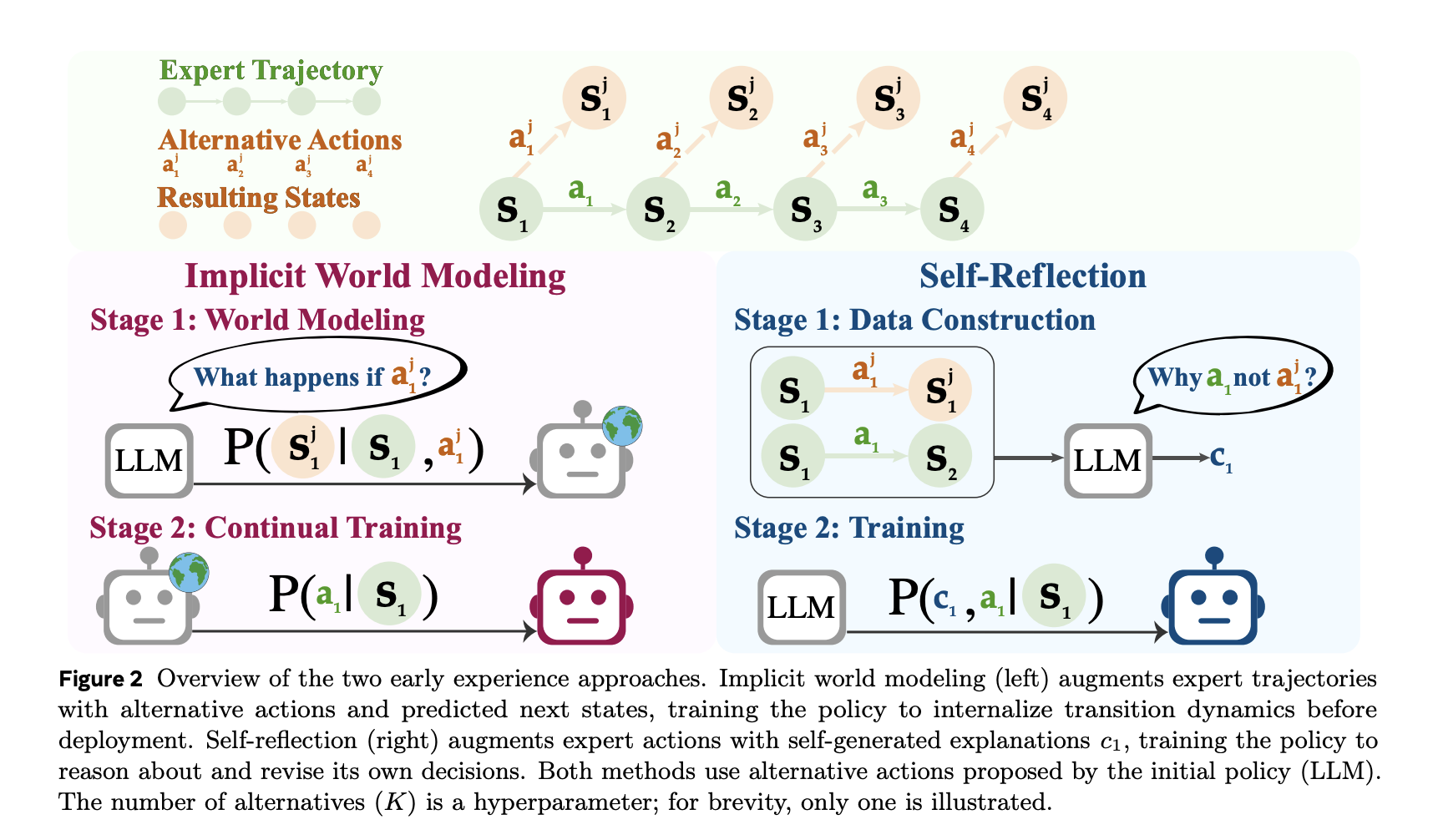
- Implicit World Modeling (IWM): Train the model to predict next observation Given a state and a chosen action, tighten the agent’s internal model of environmental dynamics and reduce off-policy drift.
- Self-Reflection (SR): Present expert actions and alternative actions in the same state; let the model explain Why expert action is better Use the observed results and then fine-tune policy based on this contrasting signal.
Both strategies use the same budget and decoding settings as IL; only the data source differs (agent-generated branches instead of more expert trajectories).
Understand the benchmarks
Research team assessment eight The language agent environment covers network navigation, long-term planning, scientific/specific tasks and multi-domain API workflows, e.g. online store (transactional browsing), travel planner (constraint-rich planning), science world, alf world, Tau benchand others. early experience Yield Average absolute return +9.6 success and +9.4 OOD IL across the entire task and model matrix. These gains persist when using the same checkpoint Initialize RL (GRPO), the upper limit after increasing RL Up to +6.4 compared to Reinforcement Learning (RL) Started with Imitation Learning (IL).
Efficiency: Less expert data, same optimization budget
A key practical victory is Presentation efficiency. Under a fixed optimization budget, early experience Match or beat IL using Fraction expert data. exist online store, 1/8 of demonstrations early experience has exceeded IL is trained full Demo set; in alf worldparity is hit 1/2 Demo. The advantage increases with the number of demonstrations, suggesting that agent-generated future states provide oversight signals that demonstrations alone cannot capture.
How the data is structured?
The pipeline obtains representative states from seeds pushed by a limited set of experts. In the selected state, the agent recommends alternative actionexecute them, and record Next observations.
- for IWMthe training data is the triple ⟨state, action, next state , and the goal is next state prediction.
- for SRthe prompts include expert actions and several alternatives with their observed consequences; the model produces a well-founded reasons Explain why expert action is preferable, and then use this oversight to improve policy.
The scope of application of reinforcement learning (RL)?
early experience yes no “Reinforcement learning without rewards.” It is a supervisory Recipes used Agent Experience Results as a label. In an environment with verifiable rewards, research teams simply Then add RL Early experience. Because initialization is better than IL, Same RL schedule Climb higher and faster, Up to +6.4 Finally, it successfully surpassed IL-initialized RL in the test domain. This positions early experience as bridge: pre-train from consequences without reward, then (if possible) follow the standard Reinforcement Learning (RL).
Main points
- Reward-free training via agent generation future state (not a reward) use Implicit world modeling and self-reflection Superior to imitation learning in eight environments.
- Reported absolute returns relative to IL: +18.4 (online store), +15.0 (Travel Planner), +13.3 (Science World) With matching budget and settings.
- Demonstration efficiency: More than IL on WebShop 1/8 Demonstrations; ALFWorld equivalent 1/2——With a fixed optimization cost.
- As an initializer, early experience Raise the subsequent RL (GRPO) endpoint via Up to +6.4 Compared to RL starting from IL.
- Validated on multiple backbone series (3B–8B) with consistent in- and out-of-domain improvements; positioned as a bridge between Imitation Learning (IL) and Reinforcement Learning (RL).
early experience is a pragmatic contribution: it replaces fragile reason-based reinforcement with outcome-based supervision, which agents can generate at scale without reward functions. These two variants—implicit world modeling (anchoring next-observation predictions of environment dynamics) and self-reflection (contrast against expert actions, rationale for result validation)—directly attack off-policy drift and long-term error accumulation, explaining consistent gains relative to imitation learning across eight environments and stronger RL upper bounds when used as GRPO initializers. In a network and tool usage environment where verifiable rewards are scarce, this reward-free supervision is the missing middle between IL and RL and enables immediate action on the production agent stack.
Check Paper is here. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


