NVIDIA researchers propose reinforcement learning pre-training (RLP): using reinforcement as the pre-training goal and building inference during pre-training
Why this is technically important: Unlike the “enhanced pre-training” variant previously relied on sparse, binary Correctness signal or proxy filter, RLP dense, verifier-free Bonus accessories location credit Wherever thinking improves predictions, updates can be achieved per token position Generally, web-scale corpora do not have external validators or curated answer keys.
Understand the results
Qwen3-1.7B-base: RLP pre-training improves overall average in Math + Science Approximately 19% compared to the base model and About 17% compared to Computational Matching Continuous Pre-Training (CPT). back After the same training (SFT + RLVR) Across all variants, the RLP initialization model retains ~7–8% relative Advantages, with greatest gains in inference-intensive benchmarks (AIME25, MMLU-Professional Edition).
Nemotron-Nano-12B v2: Apply RLP to 12B Hybrid Mamba Transformer Checkpoint generated The overall average growth rate increased from 42.81% to 61.32% and a Scientific reasoning increases absolutely by 23%even if RLP is run using Reduction of approximately 200B tokens (Trained as 19.8T and 20 tons Token; RLP has been applied for 250M tokens). This highlights data efficiency and Nothing to do with architecture Behavior.
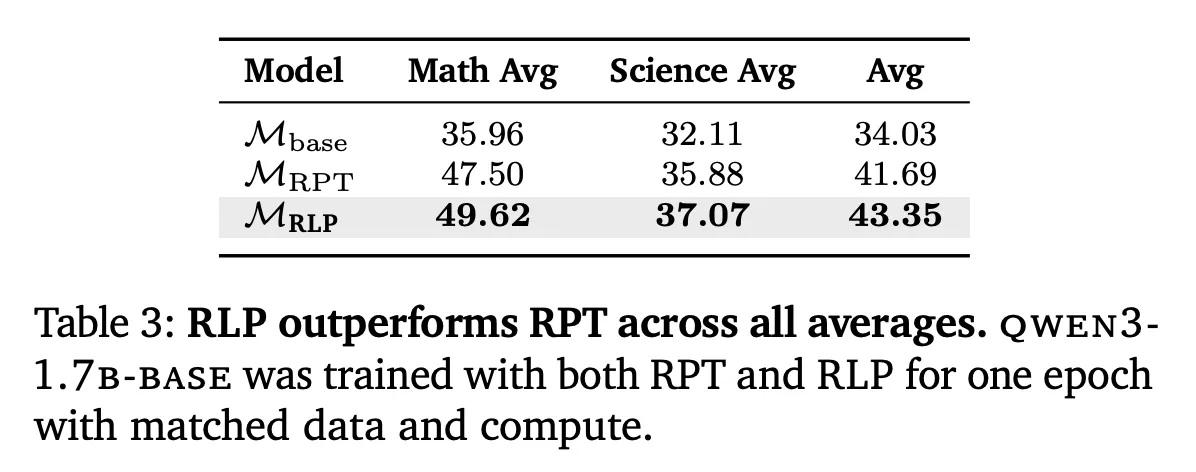
RPT comparison: RLP when matching data and using Omni-MATH style settings for calculations Better than RPT Mathematics, science and overall average scores – attributed to RLP Continuous information acquisition Rewards compared to RPT sparse binary Flags for signal and entropy filtering.
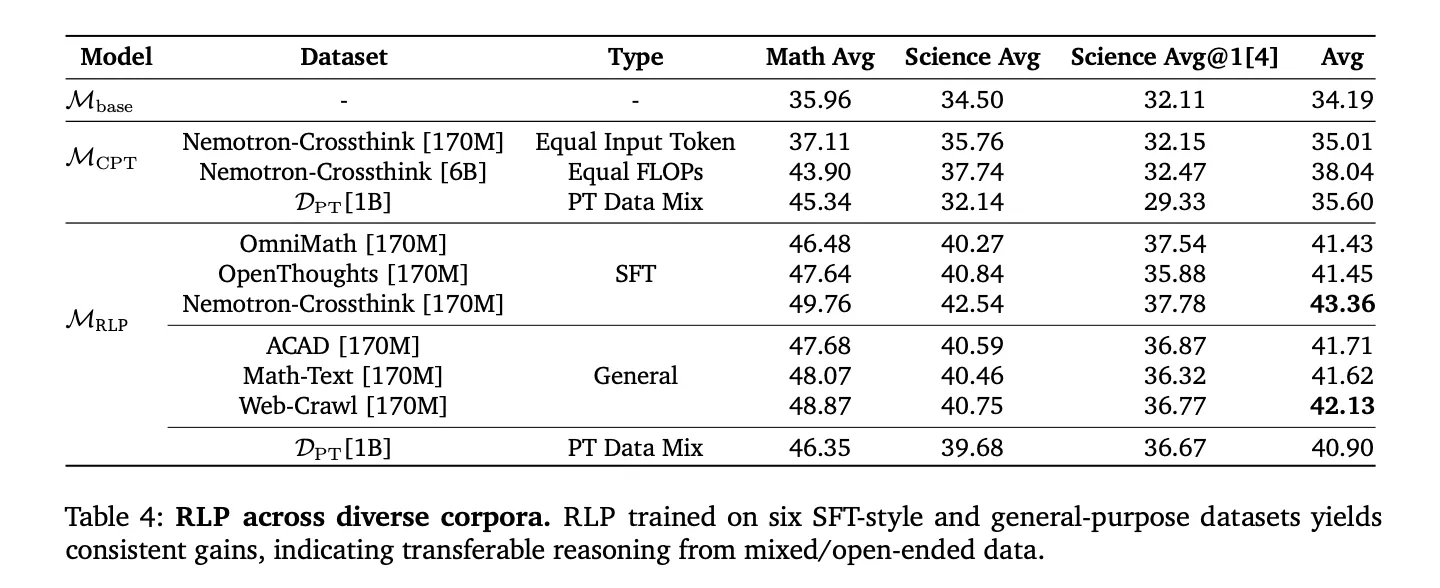
Positioning and post-training reinforcement learning and data management
Reinforcement learning pre-training (RLP) is orthogonal to the post-training pipeline (Fast Fourier Transform, RV VR) and display compound interest Improvements after standard adjustments. Because rewards are calculated Evidence from model logs It is not an external validator but extends to domain-independent corpora (web scraping, academic texts, textbooks) and SFT style inference corpus,avoiding the fragility of narrow administrative data sets. In calculating match comparisons (including CPT token increased 35 times to match FLOPs), RLP still leads the overall average, indicating that the improvement comes from objective designnot the budget.
Main points
- RLP uses inference as a pre-training goal: Sample the thought chain before the next token prediction and reward it by information gain Exceed the no-think EMA baseline.
- No validators, dense, location signals: Works on normal text streams without the need for external scorers, allowing for scalable pre-trained updates per token.
- Qwen3-1.7B results: During pre-training, +19% compared to base and +17% compared to calculated matched CPT; using the same SFT+RLVR, RLP retains about 7-8% gain (maximum on AIME25, MMLU-Pro).
- Nemotron-Nano-12B v2: Overall average rise 42.81% → 61.32% (+18.51 pp; ~35–43% relative) and +23 points Based on scientific reasoning, approximately 200B of NTP tokens are used.
- Important training details: Only update gradients on thought markers with pruning agents and swarm relative strengths; more pushouts (~16) and longer think lengths (~2048) would help; token-level KL anchoring does nothing.
in conclusion
RLP restructures pre-training to directly reward “think first, predict later” behavior using a validator-less information gain signal, resulting in long-lasting inference gains that persist and scale across architectures (Qwen3-1.7B, Nemotron-Nano-12B v2) via the same SFT+RLVR. The approach aims to compare CoT conditional likelihood against a no-brainer EMA baseline and can be cleanly integrated into large-scale pipelines without the need for elaborate validators, making it a practical upgrade to pre-training for the next coin rather than a post-training add-on.
Check paper, code and Project page. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.

")
