SwiReasoning: Entropy-driven alternation of latent and explicit thought chains in Reasoning LL.M.
SwiReasoning is a decoding time frame that lets the reasoning LLM decide when Think in potential space and when Write clear ideasuse Block-wise confidence estimated from the entropy trend in the next token distribution. The method is No training required, Model independentand target Pareto superiority Accuracy/efficiency trade-offs for math and STEM benchmarks. The report results show +1.5%–2.8% Increased average accuracy for unlimited tokens and +56%–79% Average token efficiency gain under limited budget; maximum inference accuracy achieved on AIME’24/’25 earlier Higher than standard CoT.
What happens to SwiReasoning when reasoning?
The controller monitors the decoder’s next token entropy form a Block level confidence Signal. When confidence is low (entropy is on the rise), enter underlying reasoning——The model continues to infer No tokens issued. When confidence returns (entropy trends downward), it switches back to clear reasoningissuing CoT tokens to consolidate and commit to a single path. one Switch count control Limit the maximum number Thought Block Transformation Restrain overthinking before finalizing your answer. This dynamic alternation is the core mechanism behind the reported accuracy gains per token.
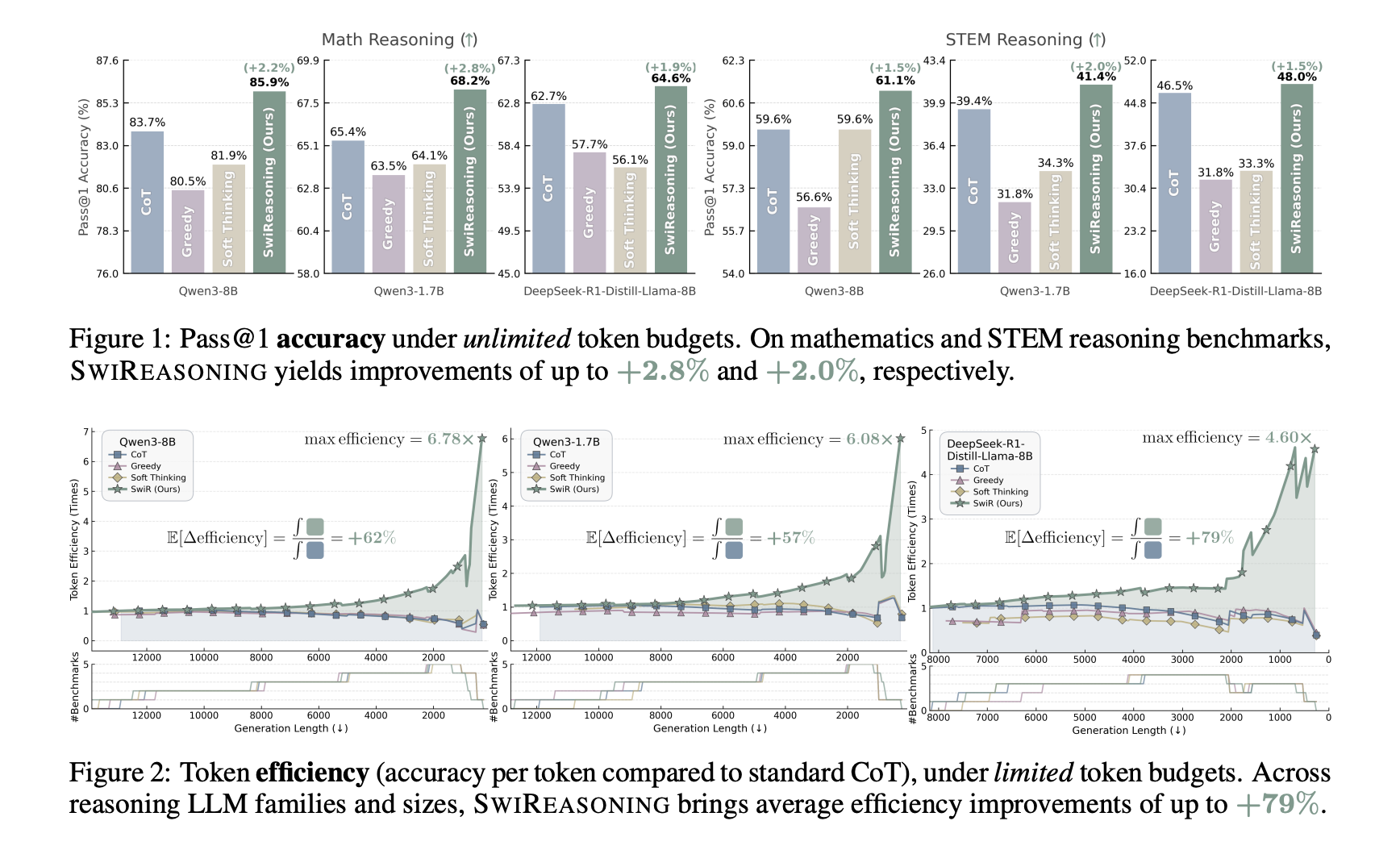
Results: Accuracy and efficiency of the standard suite
It reports improvements on math and STEM reasoning tasks:
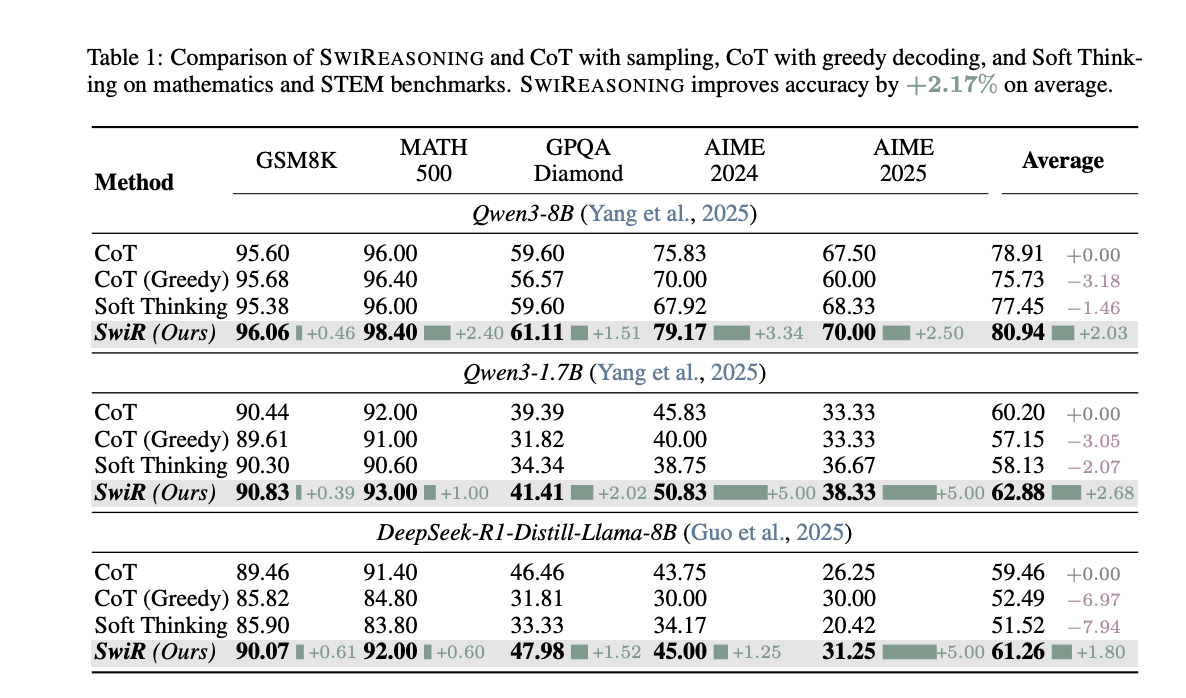
- Pass@1 (no budget limit): Accuracy increased to +2.8% (mathematics) and +2.0% (STEM) As shown in Figure 1 and Table 1, +2.17% Baseline average (sampling CoT, greedy CoT and soft thinking).
- Token efficiency (limited budget): average improvement Up to +79% (Figure 2). Comprehensive comparison shows that SwiReasoning has achieved 13/15 Tokens are the most efficient evaluation, with +84% Average improvement in CoT across these settings (Figure 4).
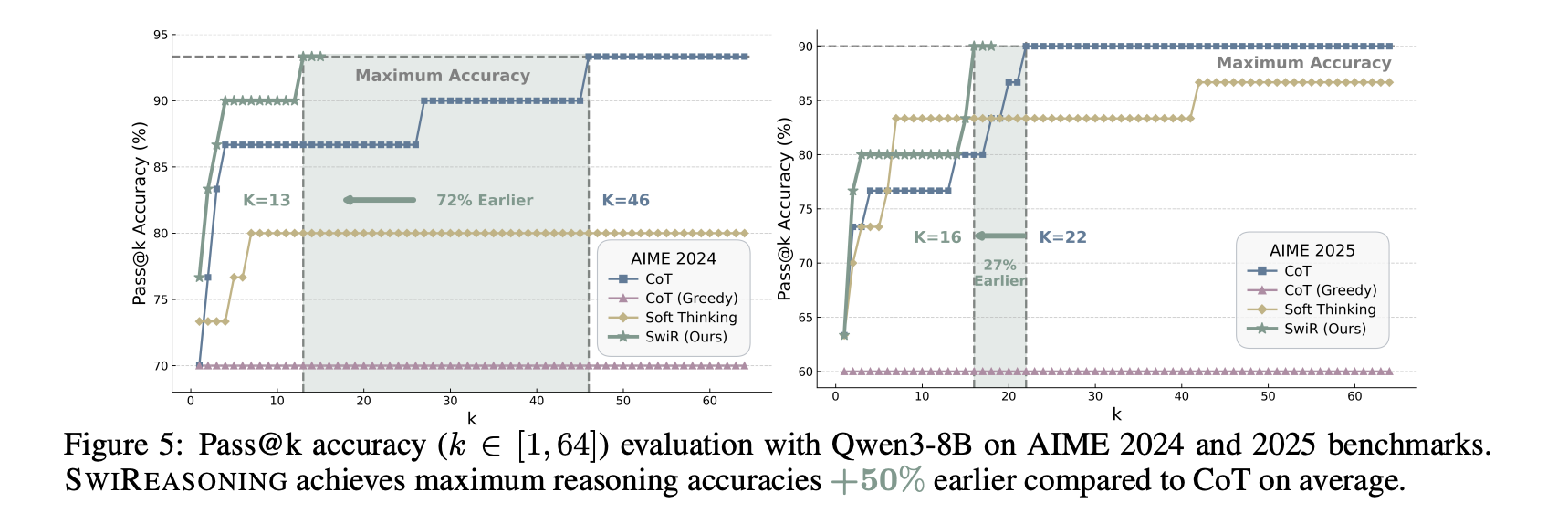
- Pass@k news: Turn on Qwen3-8B Aimee 2024/2025, Reach maximum inference accuracy +50% early The average is higher than the CoT (Fig. 5), indicating faster convergence to the upper bound with fewer sampled trajectories.
Why switching helps?
Explicit CoT is discrete and readable, but locks into a single path prematurely, which may discard useful alternatives. underlying reasoning is continuous and information-dense at each step, but a purely latent strategy may disperse the probability mass and hinder convergence. SwiReasoning added a Faith-led alternation: When the model is uncertain, the latent stage will broaden the scope of exploration; the explicit stage develop Growing confidence in solidifying solutions Submit tokens only when beneficial. this Switch count control Regulate the process by limiting oscillations and limiting long periods of “silent” wandering – solving both problems Accuracy loss due to diffusion and The symbolic waste of overthinking Challenges considered potential training-free approaches.
Positioning and Baseline
The project compares CoT with sampling, CoT greedyand soft thinkingreport a +2.17% Average accuracy improvement under unlimited budget (Table 1) and consistent Efficiency per token Advantages within budget constraints. visual Pareto front Move outward – either Higher accuracy within the same budget or Use fewer markers to achieve similar accuracy– pass through Different model series and sizes. On AIME’24/’25, by@k Curve shows SwiReasoning reaches performance ceiling Fewer samples Reflects improvements over CoT convergence behavior And not just better original ceilings.
Main points
- Training-free controller: SwiReasoning alternates between latent reasoning and explicit thought chains using chunked confidence derived from the next token’s entropy trend.
- Efficiency gain: Report +56–79% Compared to CoT, the average token efficiency increases under limited budgets, with greater gains as budgets tighten.
- Improved accuracy: accomplish +1.5–2.8% Average Pass@1 improvement on math/STEM benchmarks under unlimited budget.
- Faster convergence: Achieve maximum inference accuracy on AIME 2024/2025 earlier Than CoT (improved Pass@k dynamics).
SwiReasoning is a useful step towards practical “reasoning strategy” control when decoding: it requires no training, sits behind a tokenizer, and shows measurable gains on math/STEM suites by switching between latent and explicit CoT using an entropy trending confidence signal with an upper bound switch count. Open source BSD implementation and clear flag (--max_switch_count, --alpha) makes replication simple and lowers the barrier to stacking with orthogonal efficiency layers (e.g. quantization, speculative decoding, KV cache tricks). The value proposition of this approach is “per-token accuracy” rather than raw SOTA accuracy, which is operationally important for budget inference and batch processing.
Check Paper and Project page. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


