Acting Environmental Engineering (ACE): LL.M. in self-improvement through evolving environments rather than fine-tuning
long story short: A team of researchers from Stanford University, SambaNova Systems, and UC Berkeley introduced the ACE framework, which improves LLM performance by: Edit and grow input context instead of updating model weights. The context is viewed as a living “script” maintained by three roles –generator, reflector, curator——There are small incremental project Merge incrementally to avoid simplicity bias and context collapse. Reported earnings: +10.6% On the AppWorld agent task, +8.6% about financial reasoning, and The average delay is reduced by about 86.9% Compared to strong context-adapted baselines. On the AppWorld leaderboard snapshot (September 20, 2025), ReAct+ACE (59.4%) ≈ IBM CUGA (60.3%, GPT-4.1) When using DeepSeek-V3.1.
What’s happening with ACE?
ACE positions “contextual engineering” as a first-class alternative for parameter updates. Rather than compressing instructions into brief prompts, ACE Accumulate and organize domain-specific strategies As time goes on, the argument goes higher context density Agent tasks where improving tooling, multi-turn status, and failure modes are important.
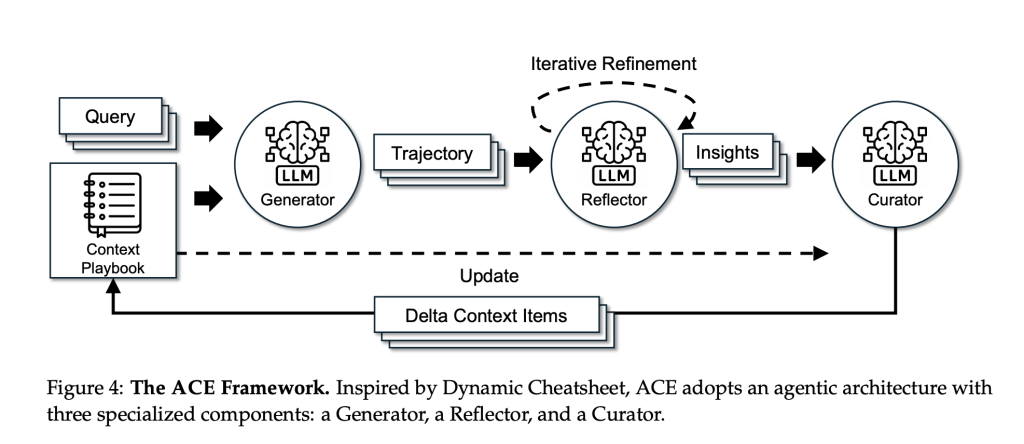
Method: Generator → Reflector → Curator
- dynamo Perform tasks and generate trajectories (inferences/tool calls) that reveal beneficial and harmful actions.
- reflector Concrete lessons are extracted from these traces.
- curator Convert course to typed form incremental project (with useful/harmful counters) and merge them deterministically, with deduplication and pruning to keep the playbook on target.
Two design options –Incremental incremental update and grow and improve– Preserve useful history and prevent “context collapse” caused by wholesale rewrites. To isolate background effects, the research team corrected Same as basic LLM (non-thinking DeepSeek-V3.1) Across all three roles.
Benchmark
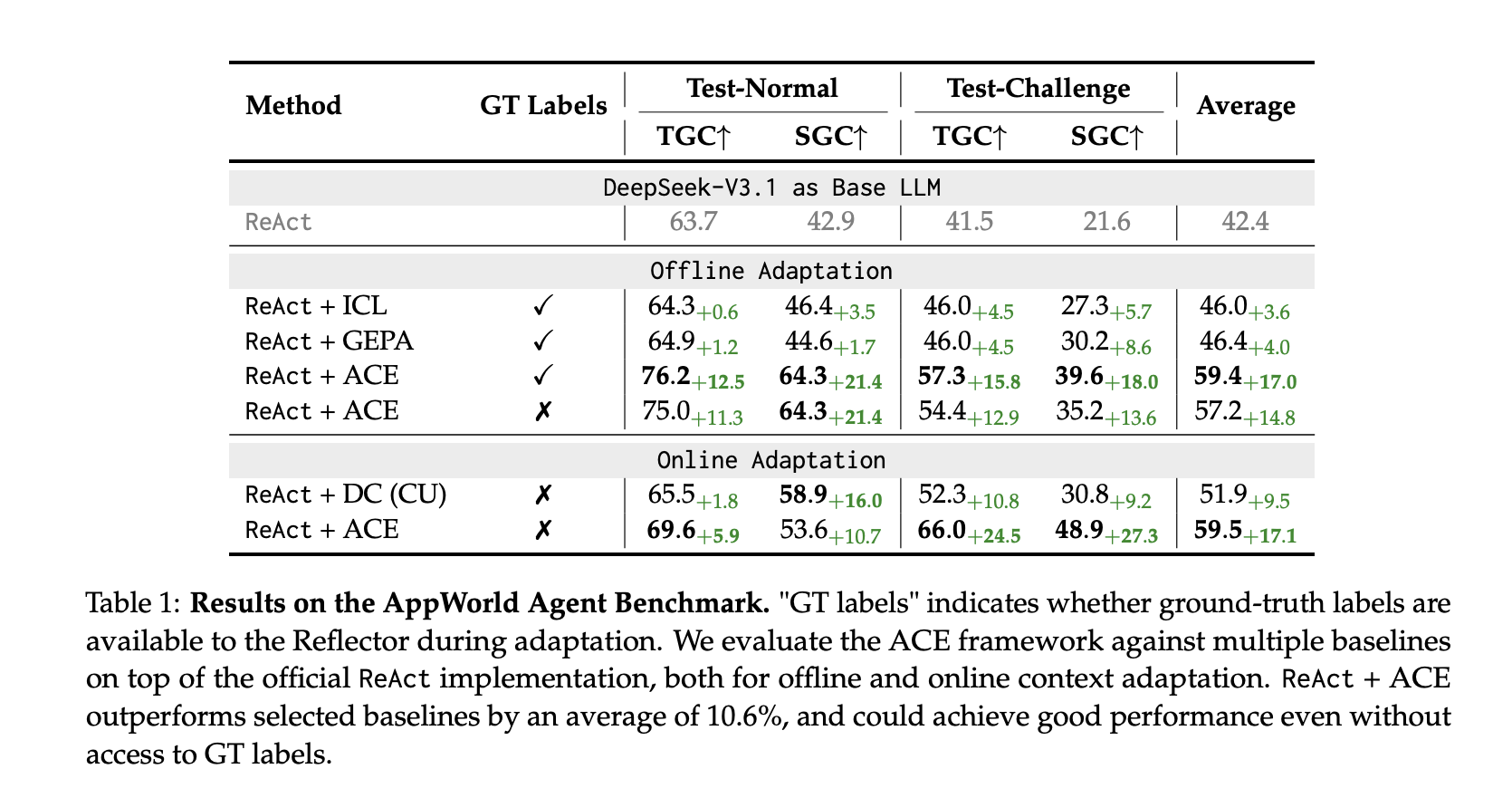
Application World (Agent): Built based on the official ReAct baseline, Reaction+ACE Outperforms powerful baselines (ICL, GEPA, Dynamic Cheatsheet), Average +10.6% exceeds the selected baseline and ~+7.6% A dynamic cheat sheet in online adaptation. superior Ranking list for September 20, 2025, ReAct+ACE 59.4% and IBM CUGA 60.3% (GPT-4.1);master Beyond CUGA The harder it is Test challenge Split while using smaller open source base models.
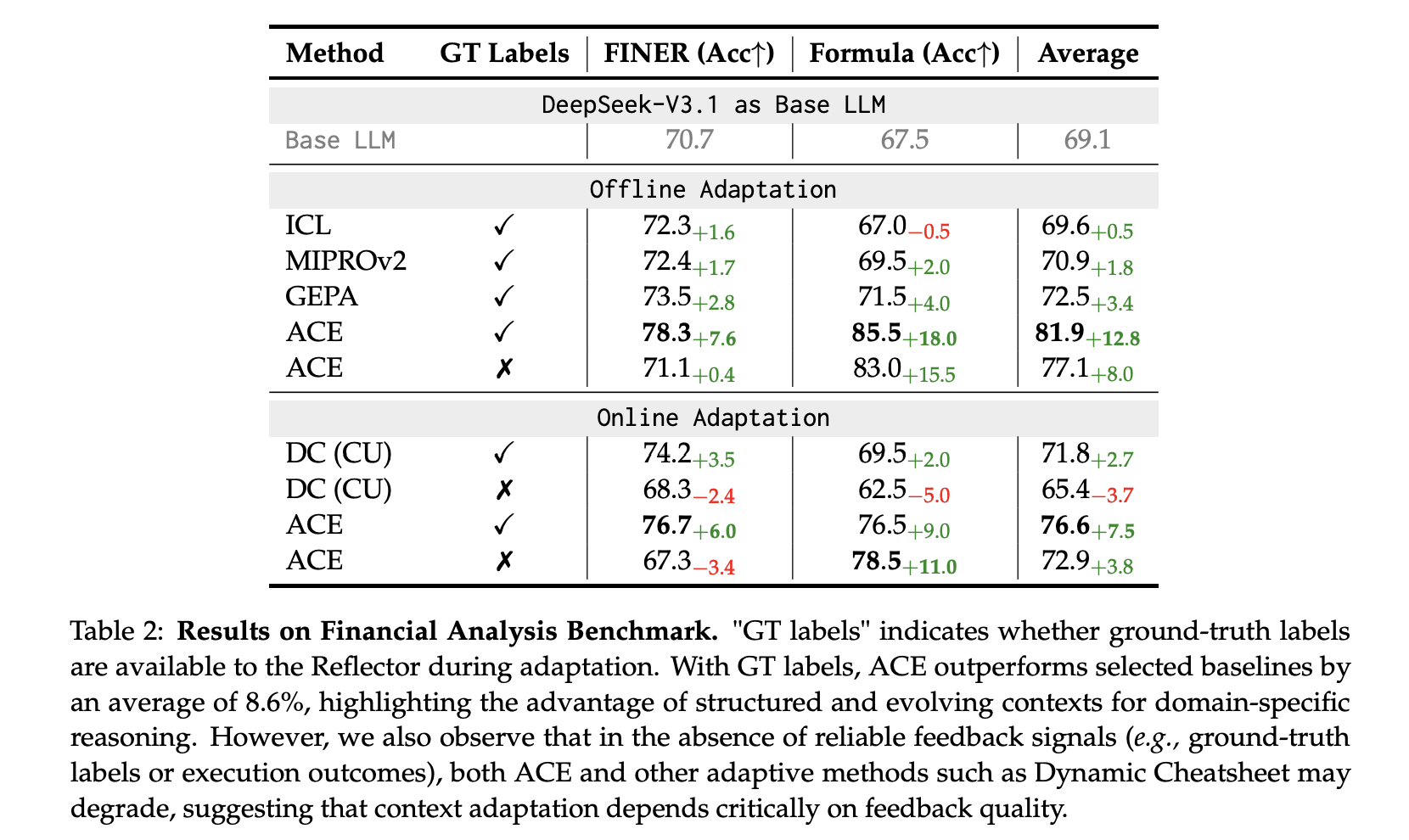
Finance (XBRL): exist Fina token tag and XBRL formula Numerical Reasoning, ACE Report Average +8.6% Exceeds the baseline with true labels for offline adaptation; although signal quality is important, it also applies to execution-only feedback.
cost and delay
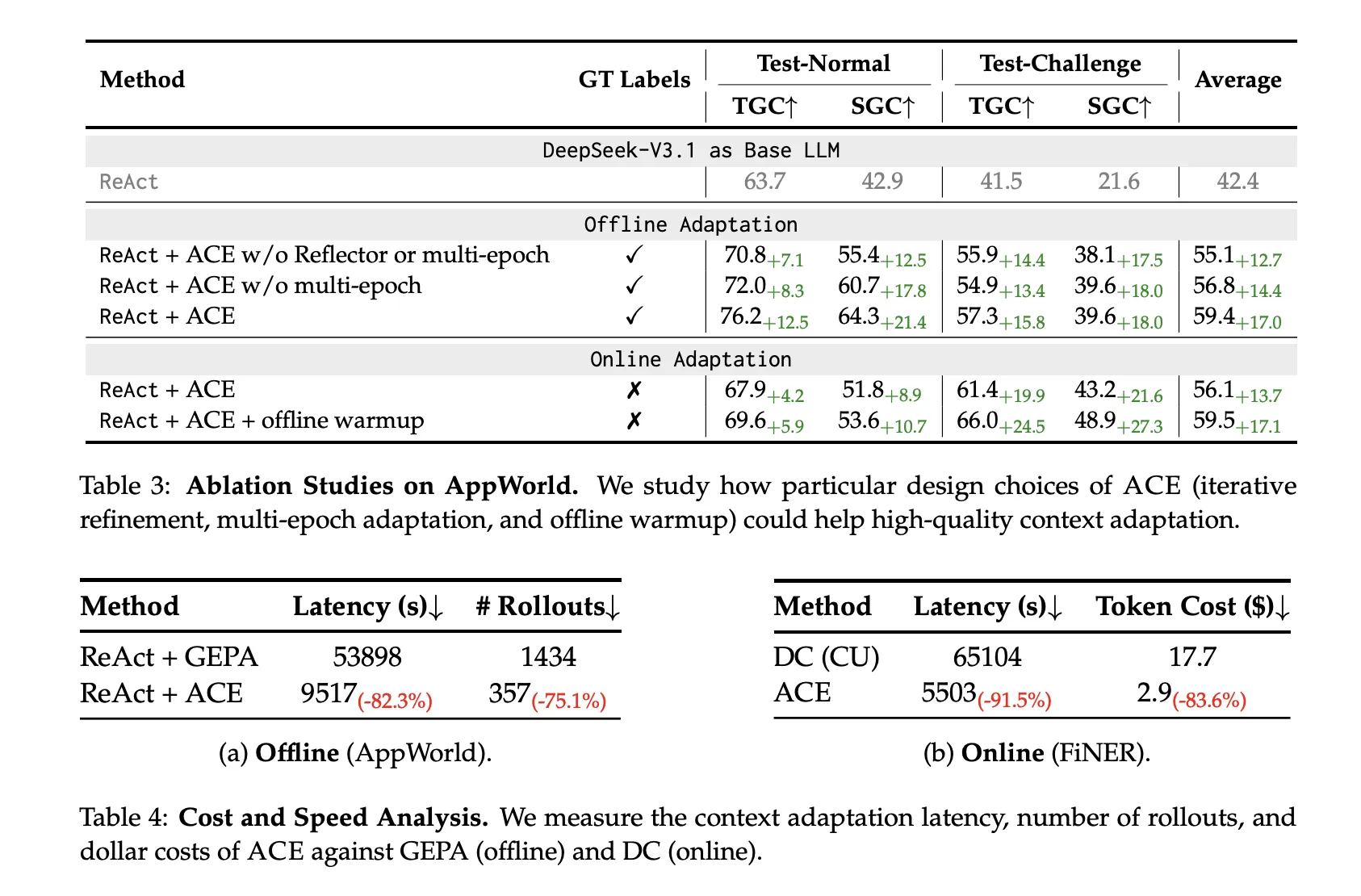
ACE Non-LLM merge Plus localized updates greatly reduce adaptation overhead:
- Offline (app world): −82.3% latency and −75.1% launched and Gepa.
- Online (FiNER): −91.5% latency and −83.6% Token Cost and Dynamic Cheat Sheet.
Main points
- ACE = context-first adaptation: Improve the LLM by incrementally editing an evolving “playbook” (incremental project) curated by Generator → Reflector → Curator, using same Basic LLM (non-thinking DeepSeek-V3.1) to isolate contextual effects and avoid crashes caused by overall rewriting.
- Measurement gain: ReAct+ACE Report +10.6% Exceed AppWorld’s strong baseline and achieve 59.4% and IBM CUGA 60.3% (GPT-4.1) Leaderboard snapshot as of September 20, 2025; financial benchmark (FiNER + XBRL formula) shown +8.6% average over baseline.
- Lower overhead than reflective rewrite baseline: ACE reduces adaptation delays by ~82–92% and launch/token costs ~75–84%in contrast to the persistent memory of Dynamic Cheatsheet and the Pareto prompt evolution method of GEPA.
in conclusion
ACE positions context engineering as a best-in-class alternative to weight updates: maintain a persistent, curated playbook, accumulate task-specific strategies, and generate measurable gains in AppWorld and financial reasoning while reducing adaptation latency and token deployment compared to reflective rewrite baselines. The approach is practical—deterministic merges, incremental projects, and long-context-aware services—and its limitations are obvious: outcome tracking feedback quality and task complexity. If adopted, the agent stack can “self-adjust” primarily through changing context rather than new checkpoints.
Check Paper is here. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an artificial intelligence media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


