Stanford researchers release AgentFlow: In-flow reinforcement learning RL for modular, tooled AI agents
Long story short: AgentFlow is a trainable agent framework with four modules (Planner, Executor, Validator, Generator) coordinated by an explicit memory and toolset. Planner optimized in loop Using new in-strategy methods, flow-grpowhich broadcasts trajectory-level outcome rewards to each round and applies token-level PPO-style updates with the advantages of KL regularization and group normalization. Across 10 benchmarks, 7B backbone adjusted with Flow-GRPO reports +14.9% (search), +14.0% (agent), +14.5% (math), and +4.1% (science) over the strong baseline.
What is proxy flow?
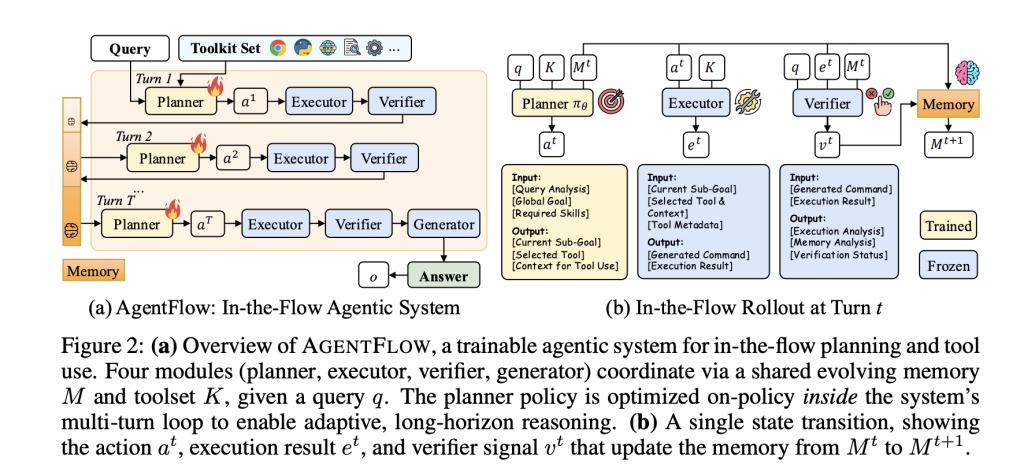
AgentFlow formalizes multi-round, tool-integrated reasoning as a Markov decision process (MDP). In each round, planner Come up with a subgoal and choose a tool and context; this executor Call the tool; this validator Indicates whether to continue; this dynamo The final answer is emitted upon termination. Structured, evolving memory records state, tool calls, and validation signals, limiting context growth and making traces auditable. Only planners are trained; other modules can be fixed engines.
The public implementation demonstrates a modular toolkit (e.g., base_generator, python_coder, google_search, wikipedia_search, web_search) and provides quick-start scripts for inference, training, and benchmarking. This repository is licensed under the MIT license.
Training method: Flow-GRPO
Flow-GRPO (flow-based grouping refinement policy optimization) Convert long-term, sparse reward optimizations into tractable single rounds of updates:
- Final result reward broadcast: A single, verifiable trajectory-level signal (LLM – as judged correctness) is assigned to every roundaligning local planning steps with global success.
- Token-level clipping targets: Importance-weighted ratios are calculated on a per-token basis using PPO-style clipping and a KL penalty on the reference strategy to prevent drift.
- Group standardization advantages: Variance reduction between rollout groups across strategies enables stable updates.
Understand results and benchmarks
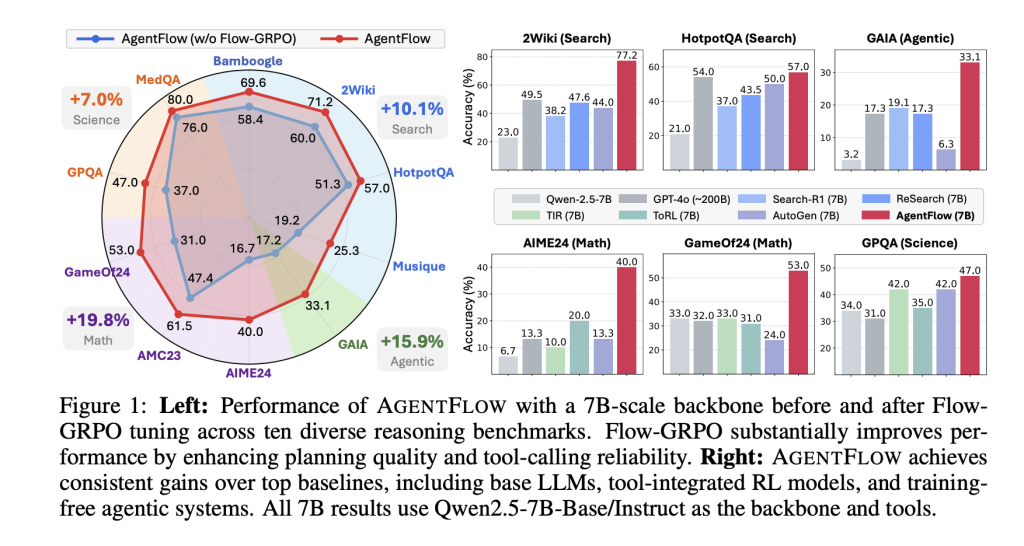
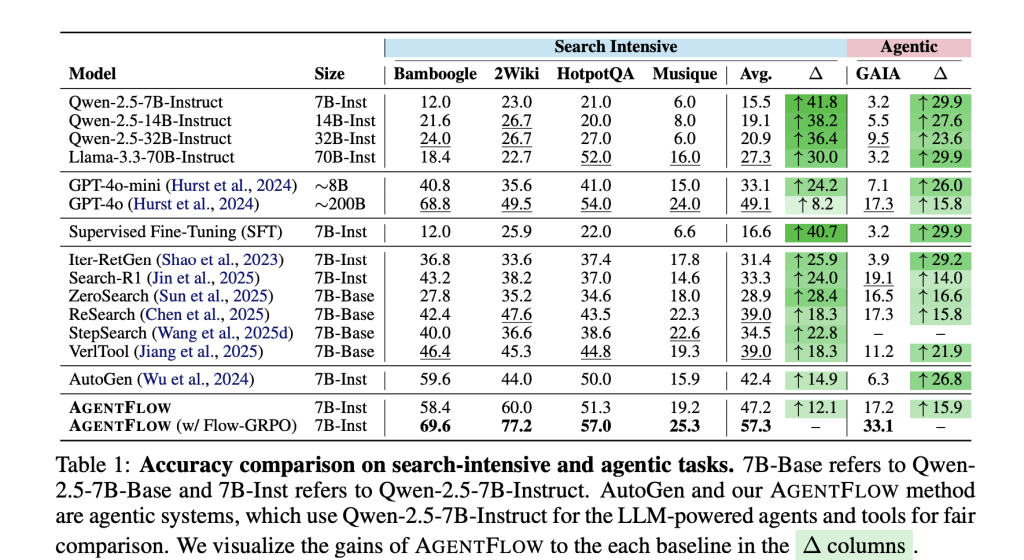
benchmark. The research team evaluated four task types: knowledge-intensive search (Bamboogle, 2Wiki, HotpotQA, Musique), agent reasoning (GAIA text segmentation), mathematics (AIME-24, AMC-23, Game of 24), and science (GPQA, MedQA). GAIA is a benchmark of tools for general-purpose assistants; text segmentation excludes multimodal requirements.
Primary number (7B trunk after Flow-GRPO). Average return relative to strong baseline: +14.9% (search), +14.0% (acting), +14.5% (math), +4.1% (science). Research team explains their 7B system Beyond GPT-4o About the reported suite. The project page also reports on training effects such as improved planning quality and fewer tool call errors (up to 28.4% GAIA), and positive trends towards larger round budgets and model sizes.
Dissolve. Online Flow-GRPO improves performance by +17.2% Offline supervised fine-tuning of the planner degrades performance compared to frozen planner baseline −19.0% About their comprehensive indicators.
Main points
- Modular agent, planner training only. AgentFlow constructs the agent as a Planner-Executor-Verifier-Generator with explicit memory; only the planner is trained in a loop.
- Flow-GRPO converts long-view RL into single-round updates. Trajectory-level outcome rewards are broadcast to each round; updates use token-level PPO-style clipping with the advantages of KL regularization and group normalization.
- The research team reports progress on 10 benchmarks. With the 7B backbone, AgentFlow reports average improvements of +14.9% (search), +14.0% (agent/GAIA text), +14.5% (math), +4.1% (science) over the strong baseline, and outperforms GPT-4o on the same suite.
- Tool usage reliability is improved. The research team reported that tool calling errors (e.g., on GAIA) were reduced and planning quality improved at larger turn budgets and model sizes.
AgentFlow formalizes the tool-using agent into four modules (Planner, Executor, Verifier, Generator) and trains the planner only in a loop via Flow-GRPO, which broadcasts a single trajectory-level reward to each round through token-level PPO-style updates and KL control. Reported results across ten benchmarks show average gains of +14.9% (search), +14.0% (agent/GAIA text segmentation), +14.5% (math), and +4.1% (science); the research team also stated that the 7B system surpassed GPT-4o on this suite. The implementation, tools, and quickstart scripts are available in a GitHub repository under the MIT license.
Check Technical papers, GitHub pages, and project pages. Please feel free to check out our GitHub page for tutorials, code, and notebooks. In addition, welcome to follow us twitter And don’t forget to join our 100k+ ML SubReddit and subscribe our newsletter. wait! Are you using Telegram? Now you can also join us via telegram.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for the benefit of society. His most recent endeavor is the launch of Marktechpost, an AI media platform that stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easy to understand for a broad audience. The platform has more than 2 million monthly views, which shows that it is very popular among viewers.
🙌 FOLLOW MARKTECHPOST: Add us as your go-to source on Google.


