Xiaomi launches Mimo-Audio, a 7B language model that uses high-fidelity tokens for training within 100m+ hours
Xiaomi’s MIMO team released Mimo-Audio, a 7 billion parameter audio language model that takes a next step toward interlaced text and discrete speech, predicting over 100 million hours of audio.
What is actually?
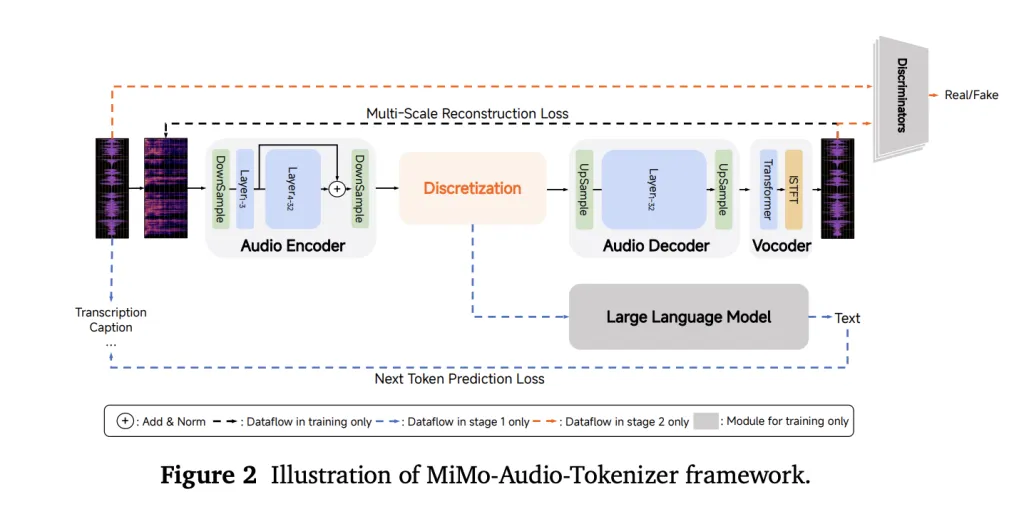
Instead of relying on task-specific heads or loss-based acoustic tokens, Mimo-Audio uses custom RVQ (residual vector quantization) tokens to target semantic fidelity and high-quality reconstruction. The token runs at 25 Hz and outputs 8 RVQ layers (≈200 tokens/s), giving LM access to the “lossless” voice function, which can be modeled with the same automatic pressurization as text.
Architecture: Patch Encoder → 7B LLM → Patch Decoder
To handle audio/text rate mismatch, the system consumes four time periods for LM (downsampling 25 Hz → 6.25 Hz) and then reconstructs the full RVQ stream with a causal patch decoder. Delayed multi-layer RVQ generation scheme staggers staggers codebooks stable integration and respect inter-layer dependencies. All three parts – the drawing encoder, MIMO-7B main chain and the patch decoder were trained for a next step of goal.
The ratio is the algorithm
The training is divided into two major stages: (1) “understanding” stage, optimized text loss with the interwoven voice text corpus, and (2) the joint “understanding + generation” stage, opening up voice continuation, audio loss of S2T/T2S tasks, S2T/T2S tasks and guiding data. The report highlights a calculation/data threshold where there seems to be very few “on” behaviors “on”, which echoes the occurrence curve in large text only LMS.
Benchmark: Voice Intelligence and General Audio
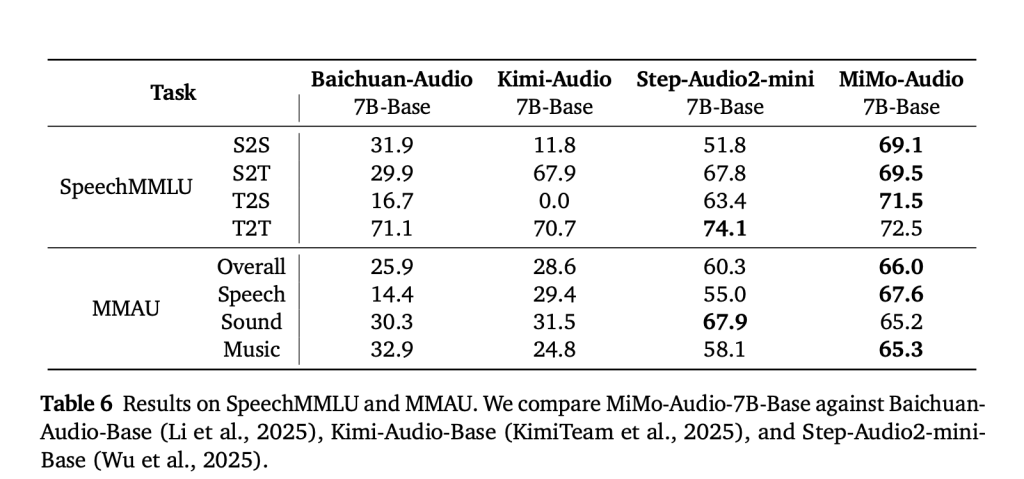
Mimo-Audio was evaluated, with high scores reported between speech planning suites (e.g. Speechmmlu) and extensive audio comprehension benchmarks (e.g., MMAU), and a reduction in the “mode gap” between speech, sound and music in text and in-speech/voice insertion/voice publishing. Xiaomi also released mimo-audio-evala common toolkit for replicating these results. Listening to the demo (voice continuation, voice/emotional conversion, denoing and voice translation) is available online.
Why is this important?
This method is intentionally simple – no multi-task tower, no customized ASR/TTS targets, and the preprocessing time is just the next prediction of GPT-style No loss Audio tokens and text. The key engineering idea is (i) the token machine that the LM can actually use without discarding the rhythm and speaker identity; (ii) patches to make the sequence length manageable; and (iii) delay RVQ decoding to retain quality in a generation. For teams that build spoken agents, these design choices translate into speech-to-speech editing with little pinyin and robust speech continuation with minimal task-specific fill.
6 technical points:
- High fidelity tokenization
Mimo-Audio uses a 25 Hz custom RVQ token with 8 active code manuals, ensuring that the voice token saves rhythm, tone and speaker identity while making it LM-friendly. - Patched Sequence Modeling
The model reduces the sequence length by grouping 4 time periods into a single patch (25 Hz → 6.25 Hz), allowing the 7B LLM to effectively process long speech without discarding details. - The next goal of unification
Instead of separating ASR, TTS, or conversation headers, Mimo-Audio is trained under a next-step prediction loss for interweaving text and audio, simplifying the architecture while supporting multitasking generalizations. - The ability to launch suddenly
Once training exceeds the large-scale data threshold, behaviors such as speech continuation, speech conversion, emotion transfer and speech translation occur (~100m hours, trillions of tokens). - Benchmark leadership
Mimo-Audio sets state-of-the-art scores on Speechmmlu (S2S 69.1, T2S 71.5) and MMAU (overall 66.0), while minimizing the text-to-speech mode gap to 3.4 points. - Open ecosystem issuance
Xiaomi provides tokens, 7B checkpoints (basics and instructions), MIMO-AUDIO-EVAL TOOLKIT and public demonstrations, enabling researchers and developers to test and extend voice-to-voice intelligence in an open source pipeline.
Summary
Mimo-Audio shows that RVQ-based high-fidelity “lossless” tokens combined with next-step preprocessing of patches is enough to unlock a small amount of voice intelligence that has few task-specific minds. 7B Stack – Use → Patch Encoder → LLM → Patch Decoder – Bridge audio/text rate gap (25 → 6.25 Hz) and preserve rhythm and speaker identity through delayed multi-layer RVQ decoding. Empirically, the model narrows the text voice gap, summarizes across voice/sound/music benchmarks, and supports S2S editing and continuation in Chinese.
Check Paper, technical details and Github page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


