Google’s wise proxy re-forms augmented reality (AR) aid into a “what+” decision – so what will happen to this?
A wise proxy is Google’s AI research framework and prototype Both this action Augmented Reality (AR) agents should take Interaction method To deliver/confirm it, conditioned on a real-time multimodal context (e.g., whether it is busy, ambient noise, social environment). Instead of viewing “hint” and “how to ask” as separate questions, it calculates them together to minimize wild friction and social embarrassment.
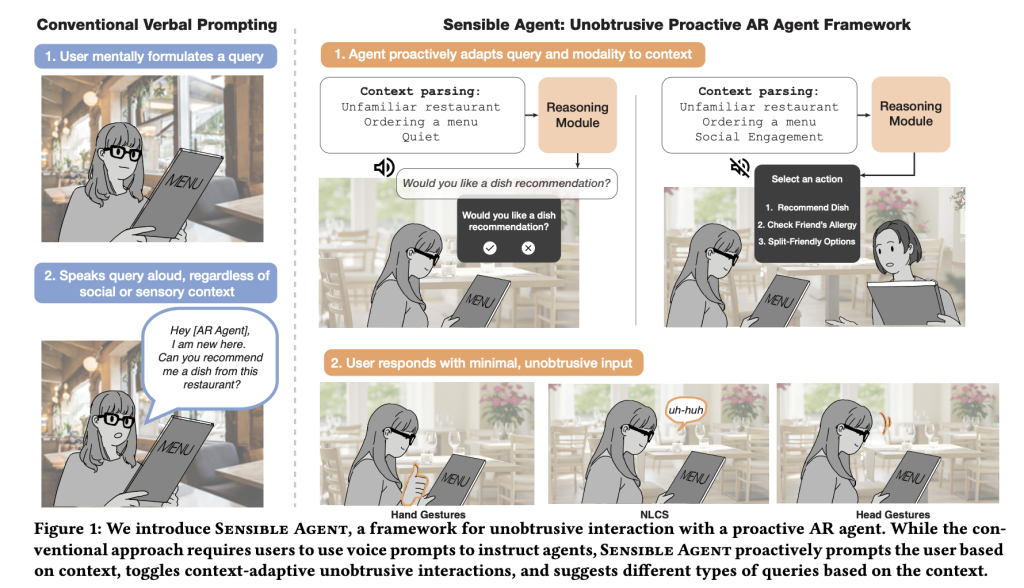
What is its interaction failure mode?
Voice priority tips are fragile: this is slow under time pressure, hands/eyes are busy and unusable, and awkward in public. The core bet of a wise proxy is that high-quality suggestions delivered through the wrong channels are actually noise. The framework is explicitly modeled Joint decision (a) What Agents make (suggestions/guidelines/reminders/automation) and (b) how It has been presented and confirmed (visual, audio or both; nodding/shaking/tilting through head, staring, finger posture, phonograph voice or non-era dialogue sound). By combining content selection with mode feasibility and social acceptability, the system aims to reduce perceived efforts while retaining utility.
How does the system be structured at runtime?
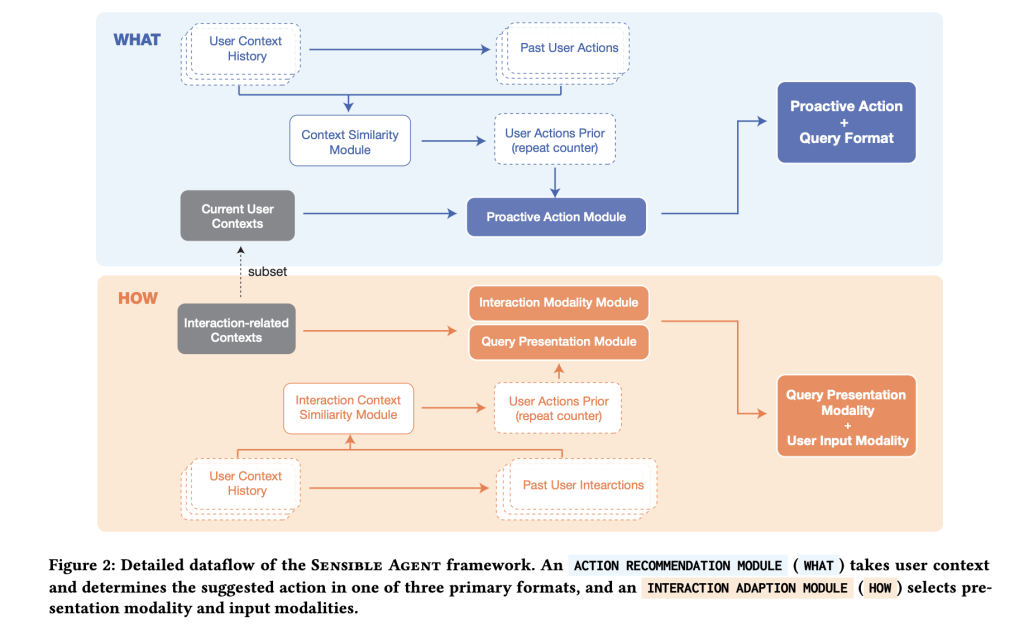
Prototypes on Android-grade XR headsets Three main stages. First, Context parsing Fusing a fusion of ambient audio classifier (YAMNET)-centric images (visual inference of scene/activity/familiarity) to detect conditions such as noise or dialogue. Second, a Active query generator Tip a large multi-modal model with few examples action,,,,, Query structure (Binary/Multiple Selection/Icon Tips) and Demo method. third, Interaction layer Only those input methods that are compatible with perceived I/O availability are enabled, for example, nodding the “yes” head when whispers are unacceptable, or staring when taking up hands.
Where does the policy for a few shots come from – designers’ instincts or data?
The team sowed the policy space through two studies: Expert workshop (n = 12) Enumerate what microinves are socially acceptable when actively helping; and Context Mapping Study (n = 40; 960 Entries) In daily situations Query Type and Way Given a context. These mappings root several example examples used by runtime, shifting the selection of “What + How” from temporary heuristics to data-derived patterns (e.g., multiselectivity in unfamiliar environments, under time pressure, icon + Visual bienter binary in socially sensitive environments).
What specific interaction technologies does the prototype support?
for Binary Confirm, system identification Nodding/shaking;for Multiple choices, Head tilted Scheme map left/right/return option 1/2/3. Finger setting Gestures support numerical selection and thumbs up/down; Stare at Trigger the visual button and the ray broadcast pointing will be picky; Short Vocabulary speech (e.g., “yes”, “no”, “one”, “two”, “three”) provides the smallest command path; and Non-time dialogue voice (“mm-hm”) covers a noisy or whisper-only environment. Crucially, the pipeline provides only ways that are feasible under the current constraints (e.g., suppressing audio prompts in a quiet space without the user viewing the HUD; avoiding gaze).
Will joint decision-making actually reduce interaction costs?
Preliminary internal user study of subjects (n = 10) Comparison of frameworks with speech baselines across AR and 360° VR Lower perceptual interaction work and Reduce invasiveness Keep usability and preferences at the same time. This is a typical sample of early HCI validation; it is directed evidence, not product-level proof, but it is consistent with papers that couple intent and modal overhead reduction.
How does the audio side work and why does Yamnet need?
Yamnet is a lightweight, Mobilenet-V1-based audio event classifier that is trained on Google’s Audioset and predicts 521 courses. In this case, detecting rough environmental conditions (rumor, music, crowd noise) is a practical option enough to make audio prompts or biases toward visual/gestic interactions, while voice can be awkward or unreliable. This model is everywhere in TensorFlow Hub and Edge guides, making it deployed directly on the device.
How do you integrate it into an existing AR or mobile assistant stack?
The minimal adoption plan looks like this: (1) The instrument’s lightweight context parser (self-centric framework + ambient audio tag) produces a compact state; (2) Build A few tables Context → (action, query type, modal) mapping of internal experiments or user research; (3) prompt LMM emission Both “What” and “How” immediately; (4) Expose only Feasible Input method for each state and keep confirmation Binary By default; (5) Offline log selection and results Policy Study. Smart proxy artifacts show that this is feasible in Webxr/Chrome on Android-grade hardware, so migration to native HMD runtimes and even phone-based HUDs is mostly engineering exercises.
Summary
Smart Agents operate proactive AR as a coupling policy issue – Select action and Interaction method The method was verified in a single, contextual conditional decision and through working WebXR prototypes and small N user studies, showing that interactions with respect to speech baselines are lower. The contribution of this framework is not a product, but a repeatable recipe: context → (what/way) mapping, few shot prompts to bind them at runtime, and inefficient input primitives that respect social and I/O restrictions.
Check Paper and technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


