Meta-AI researchers release mapanything: end-to-end transformer architecture that directly regresses standard 3D scene geometry in the body
A team of researchers at Meta Reality Labs and Carnegie Mellon University introduces mapanythingan end-to-end transformer architecture that regresses metered 3D scene geometry directly from images and optional sensor inputs. Released under Apache 2.0 and released with full training and benchmarking code, MapAnything advances beyond professional pipelines by supporting 12 different 3D visual tasks in a single feed pre-pass.

Why do general model for 3D reconstruction?
Image-based 3D reconstruction has historically relied on fragmented pipelines: feature detection, two-view posture estimation, beam adjustment, multi-view stereo or monocular depth inference. Although effective, these modular solutions require task-specific tweaks, optimizations, and major post-processing.
Recent transformer-based feed models such as DUST3R, MAST3R, and VGGT simplify the portion of this pipeline, but are still limited: a fixed number of views, rigid camera assumptions or dependencies that require expensive optimizations.
mapanything overcomes these constraints go through:
- accept 2,000 input images In a reasoning.
- Flexible use of auxiliary data, e.g. Camera inner, pose and depth map.
- Production Direct metric 3D reconstruction No bundled adjustments.
The biased scene representation of this model (composed of ray maps, depth, posture, and global scale factors) provides unparalleled modularity and versatility of previous methods.
Architecture and representation
Mapanything takes this as the core Multiple views alternately pay attention to transformers. Each input image is encoded dinov2 vit-l function, while optional inputs (rays, depths, postures) are encoded into the same latent space by shallow CNN or MLP. one Learnable proportional tokens Enable metric normalization across views.
Network output Representation of consideration:
- Viewed again Ray indicator (Camera calibration).
- Depth along the raypredict the latest.
- Camera Pose Relative to the reference view.
- one Metric factors Transform local reconstruction into a globally consistent framework.
This clear breakdown avoids redundancy, allowing the same model to handle single-eye depth estimation, multi-view stereo, structure-glue-glue (SFM) or depth completion without the need for a dedicated head.
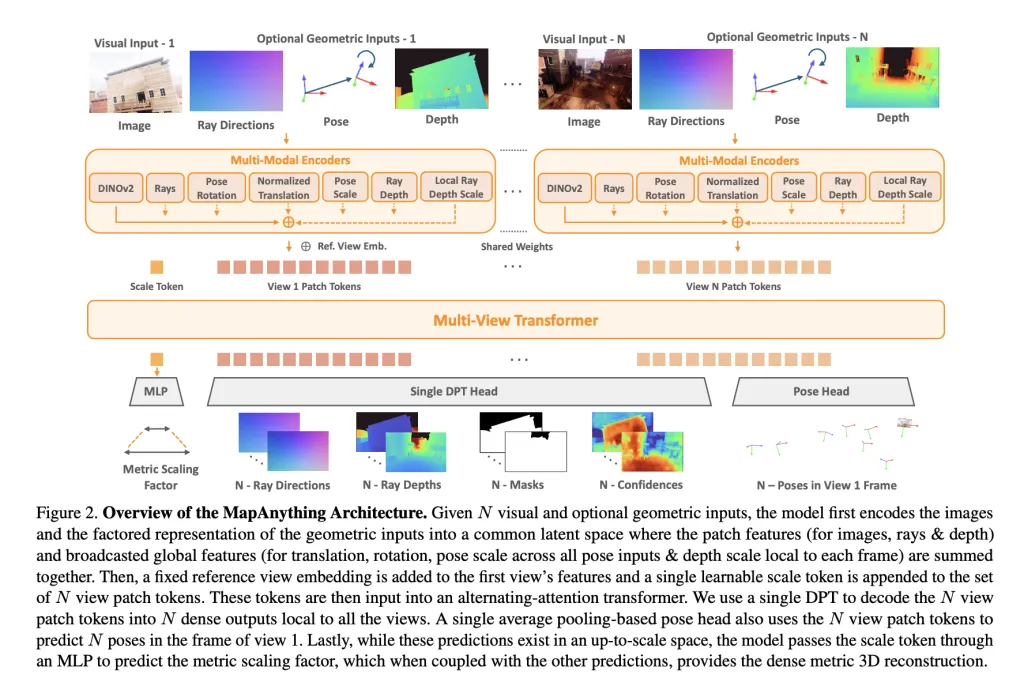
Training Strategy
Mapanything has been trained 13 different data sets Spreads indoor, outdoor and synthetic domains including mixtures, Mapillary Planet size depth, scanner++ and Tartanairv2. Two variants have been released:
- Apache 2.0 license Models trained on six datasets.
- CC BY-NC model All 13 datasets were trained to improve performance.
Key training strategies include:
- Probability input drop: During training, geometric inputs (rays, depths, postures) are provided with different probabilities, enabling robustness in heterogeneous configurations.
- Based on covalent sampling: Ensure that the input views have meaningful overlap, supporting reconstruction of up to 100+ views.
- Loss log space: Depth, scale bar and posture are optimized using constant proportions and robust regression losses to improve stability.
Carry out training 64 H200 GPU With mixed precision, gradient checkpoints and course schedule, zoom from 4 to 24 input views.
Benchmark test results
Multi-view intensive reconstruction
Mapanything achievement on ETH3D, Scanner++ V2 and Tartanairv2-WB State-of-the-art (SOTA) Performance across tip, depth, posture and ray estimation. Even if limited to images, it surpasses baselines such as VGGT and POW3R and is further improved by calibration or posture priors.
For example:
- Relative index error (rel) Use only images to improve to 0.16, while VGGT is 0.20.
- Using image + intrinsic + posture + depth, the error drops to 0.01while reaching a near ratio of 90%.
Rebuilding of two views
For Dust3R, MAST3R and POW3R, MapAnying always outperforms performance in terms of scale, depth and posture accuracy. It is worth noting that with other priors it has achieved > 92% internal ratio On the two-view task, the previous feedforward model is significantly exceeded.
Single view calibration
Although there is no training specifically for monolithic image calibration, Mapanything can still be achieved The average angle error is 1.18°exceeds Anycalib (2.01°) and Moge-2 (1.95°).
Depth Estimation
Under a strong MVD benchmark:
- mapanything sets new sota Multi-view metrics depth estimate.
- Use auxiliary inputs, which have error rates that rival or surpass specialized depth models such as MVSA and Metric3d V2.
Overall, benchmark confirmation 2× Improved previous SOTA methods In many tasks, validate the benefits of unified training.
Key Contributions
The research team highlighted four major contributions:
- Unified feed model Able to handle more than 12 problem settings from monocular depth to SFM and stereo.
- Consider scenario representation Achieve clear separation of rays, depths, postures and metrics.
- The most advanced performance There is less redundancy and higher scalability in various benchmarks.
- Open source version Includes data processing, training scripts, benchmarking and preprocessing weight under Apache 2.0.
in conclusion
MapAnything establishes a new benchmark in 3D vision by unifying multiple reconstruction tasks (SFM, stereo, depth estimation and calibration) that has a scenario representation with classification under a single transformer model. Not only does it outperform the professional approach of benchmarks, it also seamlessly adapts to heterogeneous inputs, including intrinsic, pose and depth. With open source code, predicted models and support for over 12 tasks, Mapanything lays the foundation for a truly universal 3D reconstruction of the main chain.
Check Paper, code and project pages. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.
🔥[Recommended Read] NVIDIA AI Open Source VIPE (Video Pose Engine): A powerful and universal 3D video annotation tool for spatial AI


