Moonshotai releases checkpoints – Engine: a simple middleware for updating model weights in LLM inference engine, effective for enhanced learning
Moonshotai open source Checkpoint – EngineThis is a lightweight middleware designed to address one of the key bottlenecks in large language model (LLM) deployment: quickly update model weights of thousands of GPUs without breaking inference.
The library is designed specifically for reinforced learning (RL) and human feedback (RLHF), where models are frequently updated and downtime directly affects system throughput.
How fast can LLM be updated?
CheckPoint-engine is updated via A 1-100 billion billion dollar parameter model spanning thousands of GPUs in about 20 seconds.
A traditional distributed inference pipeline can take several minutes to reload models of this size. By reducing the order of magnitude of update time, checkpoint-engine directly addresses one of the largest inefficiencies in large-scale services.
The system passes:
- Broadcast update Used for static clusters.
- Point-to-point (P2P) update Used for dynamic clustering.
- Overlapping communication and memory copy Used to reduce latency.
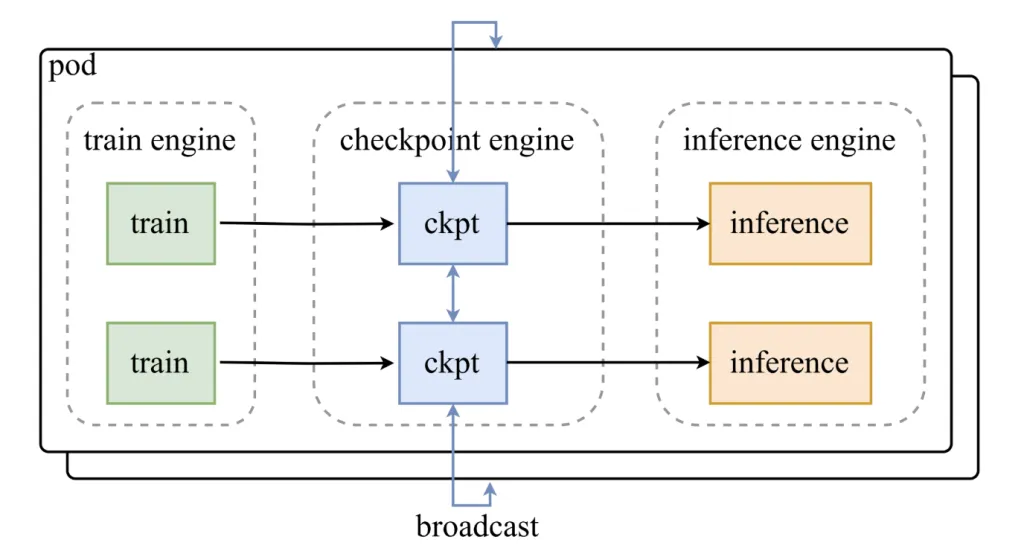
What is the architecture like?
Checkpoint – The engine is located between the training engine and the inference cluster. Its design includes:
- one Parameter Server This coordinated update.
- Worker expansion Integrate with inference frameworks such as VLLM.
The weight update pipeline is divided into three stages:
- Host to Device (H2D): Copy the parameters to GPU memory.
- broadcast: Use CUDA IPC buffers to allocate weights among workers.
- Reload: Each inference fragment reloads only the required subset of weight.
This phased pipeline has been optimized for overlapping, ensuring that the GPU remains active throughout the update process.
How does it manifest in practice?
The benchmark results confirm the scalability of the checkpoint-engine:
- GLM-4.5-Air (BF16, 8×H800): 3.94 (broadcast), 8.83 (P2P).
- QWEN3-235B-INSTRUCT (BF16, 8×H800): 6.75S (Broadcast), 16.47S (P2P).
- DeepSeek-V3.1 (FP8, 16×H20): 12.22s (broadcast), 25.77S (P2P).
- Kimi-K2-Instruct (FP8, 256×H20): ~21.5s (broadcast), 34.49S (P2P).
Even on the trillion-parameter scale, the GPU’s broadcast update is completed within about 20 seconds, verifying its design goals.
What are the trade-offs?
Checkpoint – The engine introduces significant advantages, but also limitations:
- Memory overhead: Overlapping pipelines require additional GPU memory; insufficient memory triggers slower fallback paths.
- P2P Delay: Point-to-point updates support elastic clusters, but with performance costs.
- compatibility: Formal testing with VLLM only; wider engine support requires engineering work.
- Quantification: FP8 support exists, but is still experimental.
Is it suitable for deployment?
Checkpoint – The engine is most valuable:
- Reinforcement learning pipeline Where frequent weight updates are needed.
- Large inference group Service 100B – 1T+ parameter model.
- Elastic environment With dynamic scaling, P2P flexibility offsets the latency trade-off.
Summary
Checkpoint – The engine represents a key solution to one of the most difficult problems in large-scale LLM deployments: fast weight synchronization without stopping inference. With the update of trillion-dollar parameter scales displayed in 20 seconds, flexible support for broadcast and P2P modes and optimized communication pipelines, it provides a practical way to enhance learning pipelines and high-performance inference clusters. Although still limited to VLLM and requires improvements in quantization and dynamic scaling, it establishes an important foundation for an important foundation for effective, continuous model updates in production AI systems.
Check Project page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Max is an AI analyst at Marktechpost, based in Silicon Valley, who actively shapes the future of technology. He teaches robotics at Brainvyne, uses comma to combat spam, and uses AI every day to transform complex technological advancements into clear, understandable insights


