UT Austin and ServiceNow research teams release Au Harness: an open source toolkit for overall evaluation of audio LLMS
Voice AI has become one of the most important boundaries in multimodal AI. From clever assistants to interactive agents, the ability to understand and reason audio is reshaping the way machines interact with humans. However, despite the rapid growth in the capabilities of models, the tools to evaluate them have not maintained pace. Existing benchmarks remain scattered, slowly and narrowly concentrated, often making comparison models or testing them in realistic multi-turn settings.
To resolve this gap, UT Austin and ServiceNow Research Team Published au harnessThis is a new open source toolkit designed to evaluate large audio language models (LALMS). Au-Harness is designed to be fast, standardized, and scalable, enabling researchers to test models of various tasks, from speech recognition to complex audio inference, in a single unified framework.
Why do we need a new audio evaluation framework?
Current audio benchmarks have focused on applications such as speech-to-text or emotion recognition. Framework, e.g. Influential,,,,, Voice deskand Dynamicsuperb-2.0 Expanded coverage, but they left some very critical gaps.
Three questions stand out. First of all Throughput bottleneck: Many toolkits do not take advantage of batch processing or parallelism, making large-scale evaluations slow. The second is Inconsistent promptswhich makes the results across models difficult to compare. The third is Limit the scope of the task: In many cases, key areas such as diagnosis (when to speak) and spoken reasoning (following the instructions provided in the audio).
These gaps limit the advancement of LALM, especially when they develop into multimodal agents that must deal with long, context and multi-transform interactions.
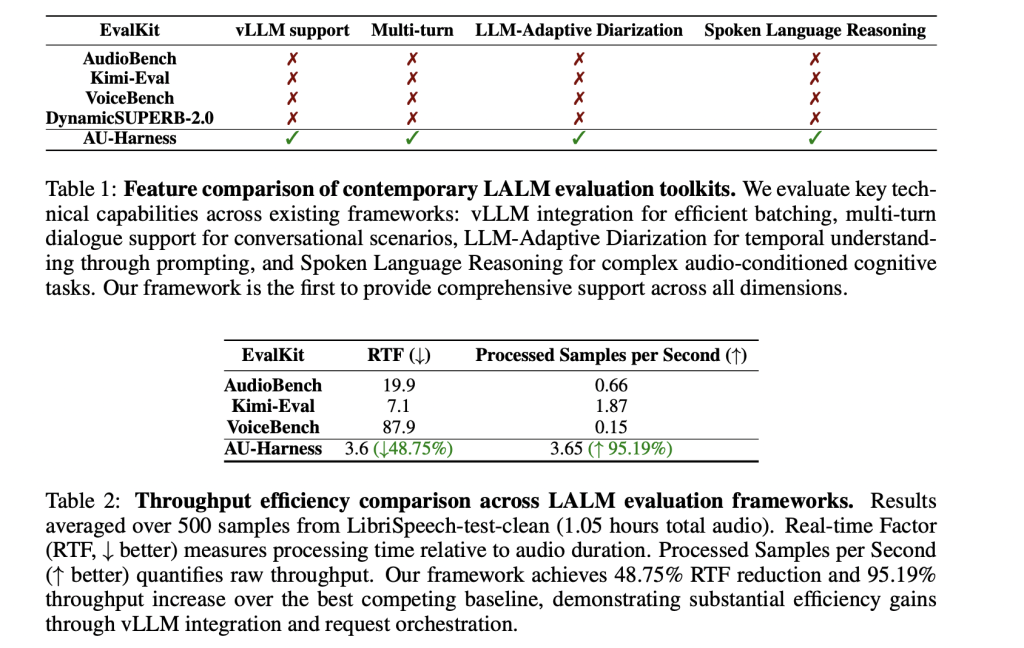
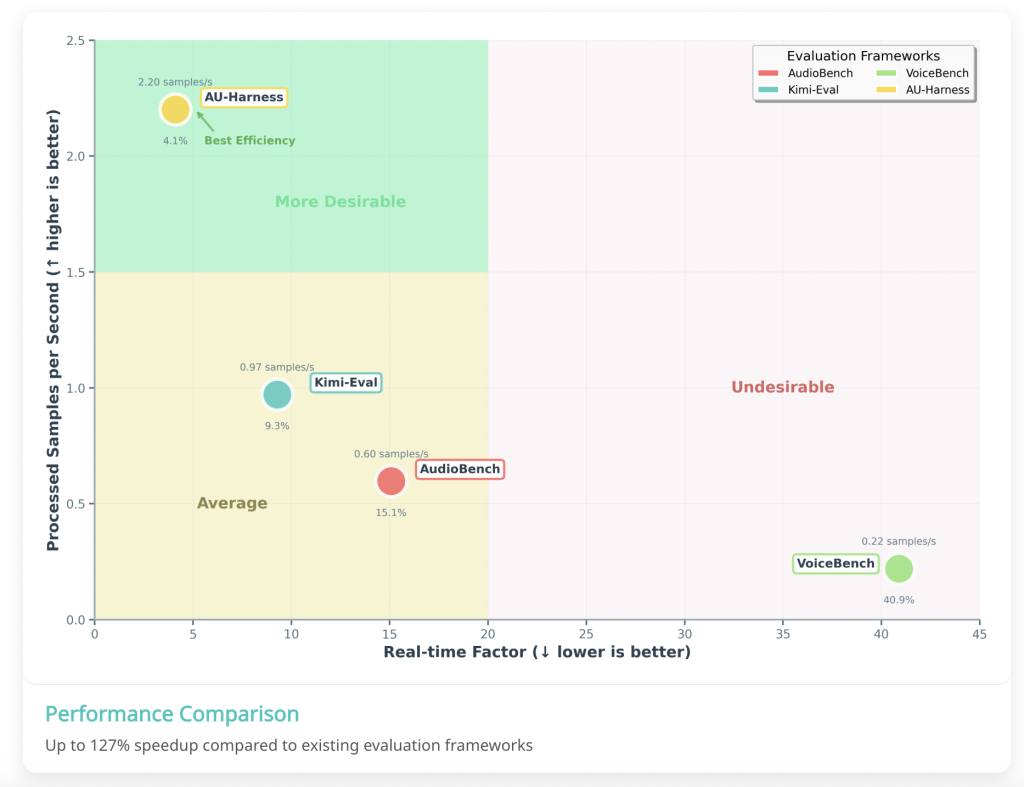
How does Au-Harness improve efficiency?
The research team designed Au Harness, which focuses on speed. By VLLM reasoning engine,It introduces a token-based request scheduler that manages simultaneous evaluation of multiple nodes. It also fragments the dataset so that workloads are distributed proportionally in compute resources.
This design allows for near-linear expansion of evaluation and makes full use of the hardware. In practice, au harness provides 127% higher throughput And reduce Real-time factor (RTF) nearly 60% Compared to existing kits. For researchers, this translates into an assessment that took months and hours to complete.

Can I customize the evaluation?
Flexibility is another core feature of Au-Harness. Evaluation Each model in the run can have its own hyperparameters, such as temperature or maximum token settings without breaking the standardization. Configuration allows Dataset filtering (for example, through accent, audio length, or noise curve), achieve target diagnosis.
Perhaps most importantly, Au Harness supports it Multi-turn dialogue evaluation. Earlier toolkits were limited to single-to-do tasks, but modern voice agents ran in extended conversations. With Au-Harness, researchers can benchmark conversation continuity, contextual reasoning, and adaptability across multi-step communication.
What tasks does Au Harness cover?
Au Harness greatly expands mission coverage, supports More than 50 datasets, more than 380 subsets and 21 tasks Spanning six categories:
- Voice recognition: From simple ASR to long and code-converted voice.
- Paralinguistics: Emotion, accent, gender and speaker recognition.
- Audio understanding: Scene and music understanding.
- Oral comprehension: Question answers, translations and conversation summary.
- Oral reasoning: The following speech pair encoding, function calls and multi-step instructions.
- Safety and security: Robustness assessment and fraud detection.
Two innovations stand out:
- LLM Adaptive Diagnosisevaluate diagnosis by prompts rather than specialized neural models.
- Oral reasoningit tests the model’s ability to process and justify spoken statements, rather than just transcribing them.

What does the benchmark reveal to today’s models?
When applied to leading systems GPT-4O,,,,, qwen2.5-omniand Voxtral-Mini-3bAu Harness emphasizes strengths and weaknesses.
The model is ASR and question answersdemonstrates strong accuracy in speech recognition and spoken quality check tasks. But they fall in Time reasoning tasksuch as diagnosis and Complex guidance trackingespecially when giving instructions in audio format.
A key discovery is Indication method gap: Performance drops to as many as possible when the same task is presented as spoken description rather than text 9.5 points. This suggests that while models are good at dealing with text-based reasoning, adapting these skills to audio methods remains an open challenge.
Summary
Au-Harness marks an important step towards standardized and scalable audio language model evaluation. By combining efficiency, repeatability, and a wide range of task coverage, including diagnostics and spoken reasoning, it addresses the long-term gap in benchmarking voice AI. Its open source releases and public rankings invite communities to collaborate to compare and break through the scope that voice-first systems can achieve.
Check Paper, project and Github page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


