Baidu releases Ernie-4.5-21B-A3B thinking: a compact MOE model for deep reasoning
Baidu AI research team just released Ernie-4.5-21B-A3B Thinkinga new large-scale language model focused on reasoning, designed around efficiency, novel reasoning, and tool integration. As part of the Ernie-4.5 family, this model is Experts’ mixture (MOE) structure with 21B total parameters, but only 3B active parameters per tokenwhile maintaining competitive reasoning ability, make it computationally effective. exist Apache-2.0 Licensethrough research and commercial deployment can be Hug the face.
What is the architectural design of Ernie-4.5-21B-A3B thinking?
Ernie-4.5-21B-A3B believes that it is based on Expert’s Mixed Main Chain. Instead of activating all 21b parameters, the router selects a subset of experts, resulting in 3B activity parameters per token. This structure can reduce the calculation without compromising the specialization of different experts. Research teams are suitable Router quadrature loss and Loss of token balance Encourage diverse expert activation and stable training.
The design provides a middle ground between small intensive models and oversized systems. The research team’s hypothesis includes a theory that ~3b each token may represent a practical active parameter The best points for inference performance and deployment efficiency.
How does this model deal with novel reasoning?
Ernie-4.5-21B-A3B believes that the ability to define is it 128K context length. This allows the model to process long documents, perform extended multi-step inference, and integrate structured data sources such as academic papers or multi-file code bases.
The research team passed Stepwise scaling of rotation position embed (rope)– During training, the rate group increases from 10K to 500K. Other optimizations, including Flashmask’s attention and memory efficient scheduling makes these novel operations computationally feasible.
Which training strategy supports its reasoning?
This model follows a multi-stage formula defined in the Ernie-4.5 family:
- Phase 1 – Read and write only Build a core language backbone, starting with an 8K context and expanding to 128K.
- Phase 2 – Vision Training This is skipped with text variations only.
- Phase 3 – Joint multi-mode training Not used here, because A3B believes it is purely textual.
The focus after training is Reasoning Task. Research team hire Supervised fine-tuning (SFT) Crossing mathematics, logic, coding and science, then Progressive Reinforcement Learning (PRL). The reinforcement phase begins with logic, then expands to mathematics and programming, and finally to a wider range of reasoning tasks. This is through Unified Preference Optimization (UPO)integrate preference learning with PPO for stable alignment and reduce reward hacking.
What role does tool usage play in this model?
Ernie-4.5-21B-A3B believes support Structured tools and function callsmaking it useful for schemes that require external calculations or retrieval. Developers can integrate it vllm,,,,, Transformer 4.54+and FastDeploy. This tool is particularly suitable for use Program synthesis, symbolic reasoning and multi-agent workflows.
Built-in feature calls allow models to reason in a longer context while dynamically calling external APIs, which is a key requirement for applying reasoning in enterprise systems.
Ernie-4.5-21B-A3B thinks about how to execute on reasoning benchmarks?
It shows powerful performance improvements Logical reasoning, mathematics, scientific quality inspection and programming tasks. In the evaluation, the model proves:
- Improve accuracy Multi-step inference dataseta long chain of thought is needed.
- Competitiveness with greater intensive models STEM reasoning task.
- Stable Text generation and academic comprehensive performancebenefit from extended context training.
These results show MOE structure amplification reasoning professionalmaking it effective without trillions of dense parameters.
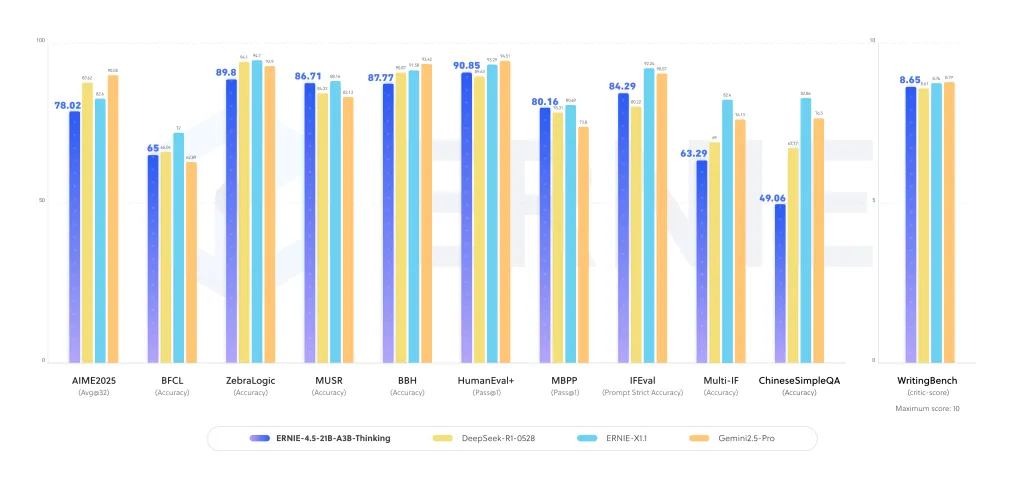
How about it compared to other reasoning-centric LLMs?
This version enters the following: Openai’s O3, Human’s Claude 4, DeepSeek-R1 and Qwen-3. Many of these competitors rely on dense architectures or larger counts of active parameter. Baidu research team selection Compact MOE with 3B activity parameters Provides different balances:
- Scalability: Sparse activation reduces computational overhead while expanding expert capacity.
- Long cultural preparation: The 128K context is directly trained and not renovated.
- Commercial openness: The Apache-2.0 license reduces corporate adoption friction.
Summary
Ernie-4.5-21B-A3B believes that explains how In-depth reasoning can be achieved without a large number of dense parameter counts. By combining effective MOE routing, 128K context training and tool integration, Baidu’s research team provides a model that balances research-level reasoning with deployment feasibility.
Check Model embracing face and Paper. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.

 for real-time resource and tool integration")
