Microsoft AI introduces RSTAR2 Agent: 14B Mathematical Inference Model, which trains learning through proxy enhancement to achieve cutting-edge-level performance
“Think longer” question
Large language models have made impressive progress in mathematical reasoning by extending their chain of ideas (COT) processes, which is actually “think longer” through more detailed reasoning steps. However, this approach has fundamental limitations. When models encounter subtle errors in their chain of reasoning, they often exacerbate these errors rather than detecting and correcting them. Internal self-reflection often fails, especially when the initial reasoning method is fundamentally flawed.
Microsoft’s new research report introduces the RSTAR2 proxy, which takes a different approach: It not only takes longer to think, but instead teaches the model to think smarter by actively using coding tools to validate, explore and refine its inference process.
Proxy method
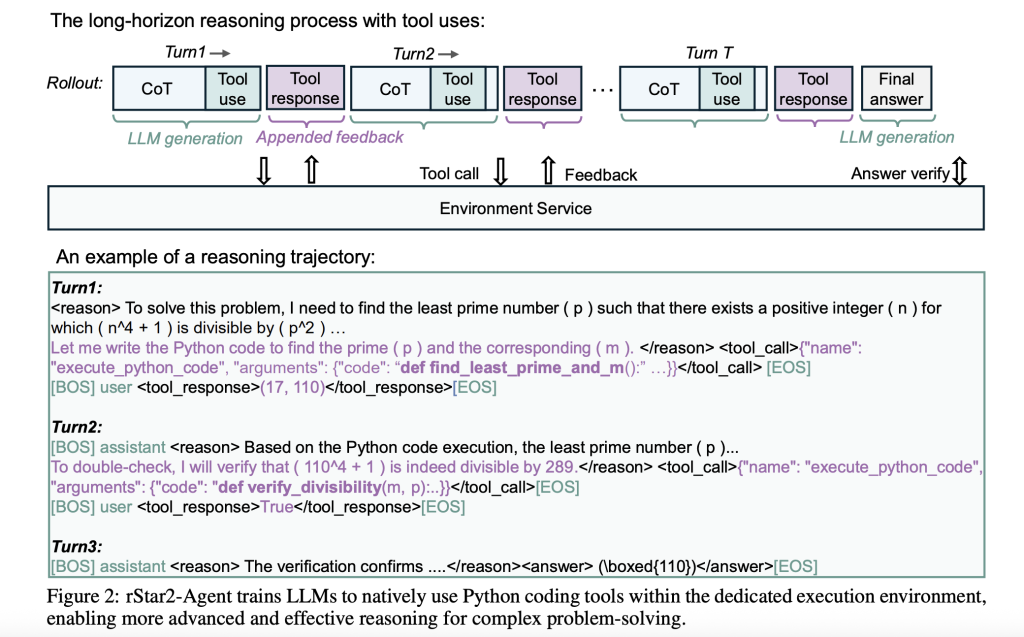
RSTAR2 proxy represents a transition to proxy enhancement learning, where the 14b parameter model interacts with the Python execution environment throughout its inference process. The model can not only rely on internal reflections, but also write code based on specific feedback, execute the code, analyze the results and adjust its methods.
This creates a dynamic problem-solving process. When a model encounters a complex mathematical problem, it may produce initial reasoning, write Python code to test hypotheses, analyze execution results, and iterate over the solution. This approach reflects the way human mathematicians often work – using computational tools to validate intuition and explore different paths to solution.
Infrastructure challenges and solutions
Scaling proxy RL presents significant technical hurdles. During training, a single batch can generate tens of thousands of concurrent code execution requests, creating bottlenecks that can stall GPU utilization. The researchers addressed this problem with two key infrastructure innovations.
First, they built a distributed code execution service that was able to handle 45,000 parallel tool calls and delayed delays. The system isolates the code from the main training process while maintaining high throughput through careful load balancing by CPU workers.
Second, they developed a dynamic rollout scheduler that allocates computational work based on real-time GPU cache availability rather than static allocation. This prevents GPU idle time caused by unbalanced workload distribution – a common problem when some inference traces require more calculations than others.
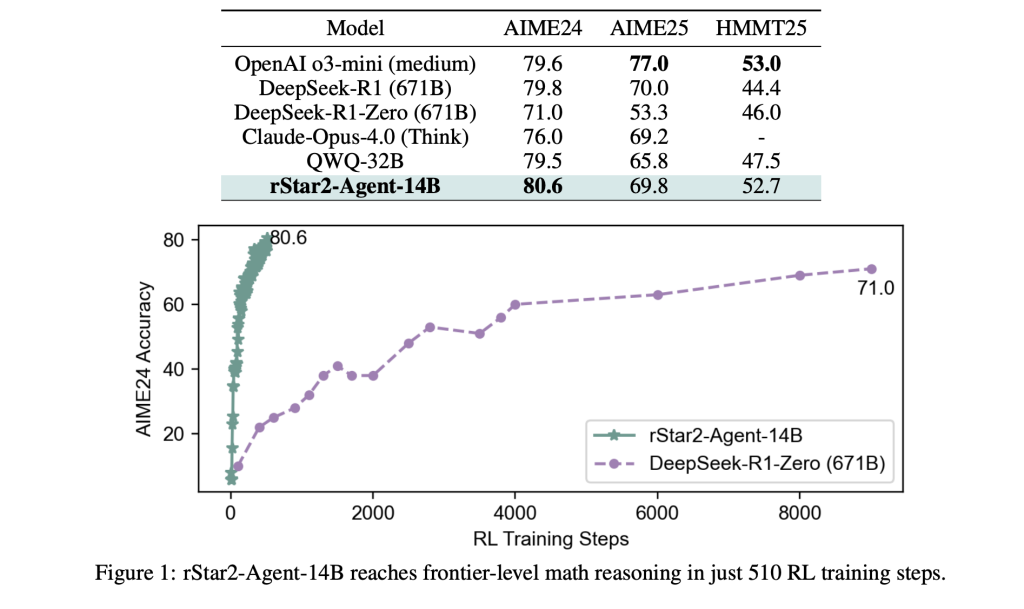
These infrastructure improvements allow the entire training process to be completed in just one week with a 64 AMD MI300X GPU, indicating that border-level reasoning capabilities do not require a large amount of computing resources when effectively orchestrated.
GRPO-ROC: Learn from high-quality examples
Core algorithm innovation is collective relative strategy optimization, correct sampling (GRPO-ROC). In this case, traditional reinforcement learning faces a quality problem: even if its inference process includes multiple code errors or inefficient use of tools, the model receives positive rewards even if its inference process is used.
GRPO-ROC solves this problem by implementing an asymmetric sampling strategy. During training, the algorithm:
- Example Initial rollout to create larger inference trajectories
- Keep diversity Maintain various error mode learning in failed attempts
- Filter positive examples Emphasize traces with minimal tool errors and cleaner formats
This approach ensures that the model learns from high-quality successful reasoning while still being exposed to various failure patterns. The result is more effective tool usage and shorter, more focused traces of reasoning.
Training Strategy: From Simple to Complex
The training process unfolds in three well-designed phases, first with irrational fine-tuning of supervision, focusing purely on the guide and tool formats that follow, freely avoiding complex examples of reasoning that may produce early bias.
Stage 1 Limiting responses to 8,000 tokens forces the model to develop a concise reasoning strategy. Despite this limitation, performance has risen dramatically – from zero to more than 70% of the benchmarks.
Stage 2 Extending the token limit to 12,000 allows for more complex reasoning while maintaining the efficiency of the first phase.
Stage 3 By filtering out these problems that the model has mastered, focusing on the most difficult problems, thus ensuring that learning continues from challenging situations.
The development from simplicity to extended reasoning, coupled with increasing problem difficulty, can maximize learning efficiency while minimizing computational overhead.
Breakthrough results
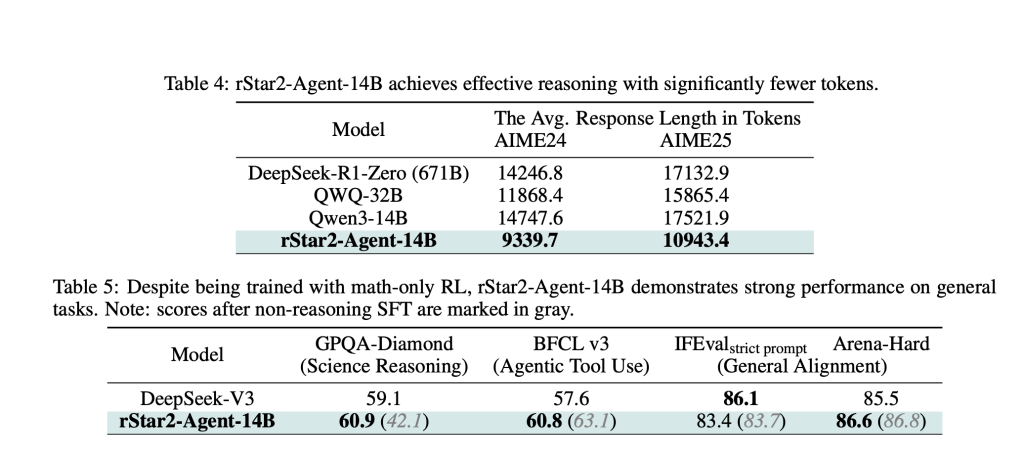
The results are surprising. RSTAR2-AGENT-14B has an accuracy of 80.6% on AIME24, and AIME25 has an accuracy of 69.8%, surpassing the larger number including the 671B parameter DeepSeek-R1. Perhaps more importantly, it achieves this with a significantly shorter inference trajectory, comparing about 10,000 tokens, while comparable models exceed 17,000.
The efficiency improvement range is beyond mathematics. Although trained only on mathematical problems, the model demonstrates strong transfer learning, superior to professional models of scientific reasoning benchmarks, and maintains competitive performance on general consistency tasks.
Understand the mechanism
Analysis of trained models reveals fascinating behavioral patterns. High penetration tokens in the inference trajectory are divided into two categories: traditional “fork tokens” that trigger self-reflection and exploration, and a new category that emerges specifically for tool feedback.
These reflective tokens represent an environment-driven form of reasoning, which carefully analyzes code execution results, diagnoses errors and adjusts its approach accordingly. This produces more complex problem-solving behavior than pure Cot reasoning can achieve.
Summary
RSTAR2 proxy shows that medium-sized models can achieve border-level inference through complex training rather than brute force scaling. This approach proposes a more sustainable approach to advanced AI capabilities – a strategy that emphasizes efficiency, tool integration and intelligent training to raw computing power.
The success of this proxy approach also points to future AI systems that can seamlessly integrate multiple tools and environments instead of static text generation towards dynamic, interactive problem solving capabilities.
Check Paper and github pages. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


