Accenture Research introduces the MCP foundation: a large-scale benchmark that evaluates LLM proxy in complex real-worlds through an MCP server
Modern large language models (LLMs) go far beyond simple text generation. Many of the most promising real-world applications now require these models to use external tools such as APIs, databases, and software libraries to solve complex tasks. But how do we really know if AI agents can plan, rationally and coordinate tools in the way human assistants do? This is the question to be answered on the MCP bench.
Problems with existing benchmarks
Most of the benchmarks of previous tools LLM focused on one-time API calls or narrow, artificially sewn workflows. Even more advanced assessments rarely test the agents’ ability to find and link the right tools from vague, real-world instructions, just by whether they can be coordinated in multiple areas and rooted in actual evidence for the answer. In practice, this means that many models perform well on manual tasks but struggle with the complexity and ambiguity of real-world scenarios.

What makes the MCP bench unique
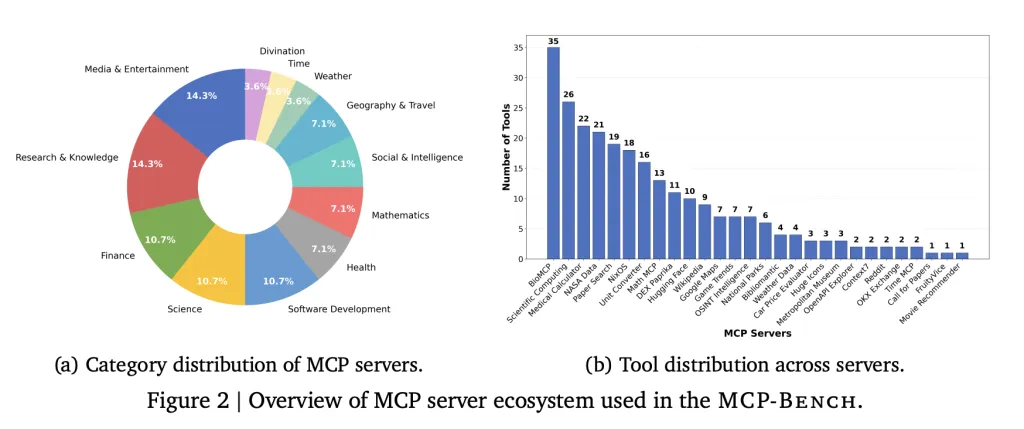
A team of researchers from Accenture introduced MCP Bench, a benchmark for LLM agents based on Model Context Protocol (MCP) that connects them directly to 28 real-world servers, each providing a suite of tools across a variety of fields such as finance, scientific computing, healthcare, travel, travel and academic research. Overall, the benchmark covers a total of 250 tools to make realistic workflows use sequential and parallel tools, and sometimes multiple servers.
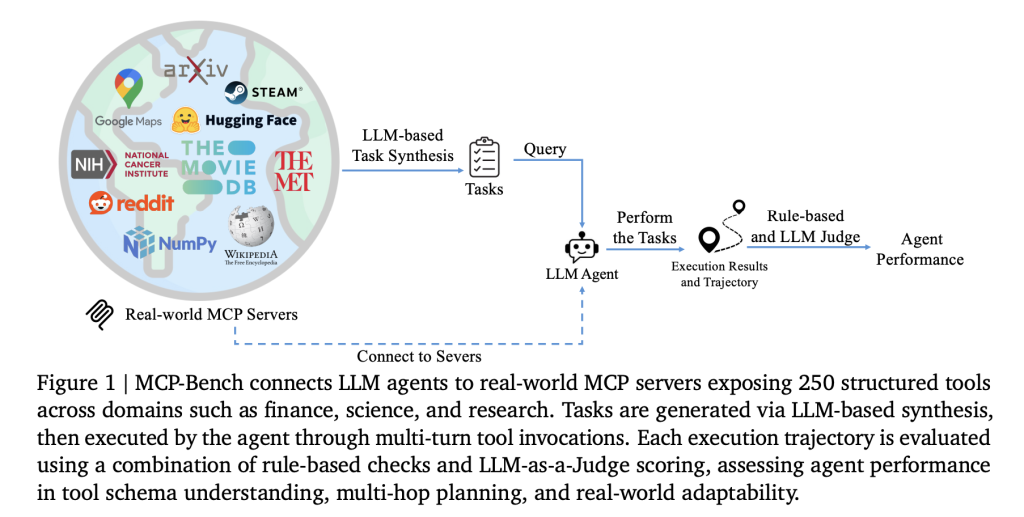
Key Features:
- Real mission: Missions are designed to reflect real user needs, such as planning multi-stop camping tours (involving geospatial, weather and park information), conducting biomedical research or converting units in scientific calculations.
- Fuzzy explanation: Rather than specifying tools or steps, describe tasks in natural, sometimes vague language and ask the agent to infer what to do, just like a human assistant.
- Tool diversity: Benchmarks include everything from medical calculators and scientific computing libraries to financial analysis, icon collection, and even niche tools like I Ching divination services.
- Quality Control: Tasks are automatically generated and then filtered for the relevance of the solution and real-world. Each task also comes in two forms: an accurate technical description (for evaluation) and a dialogue, a fuzzy version (what the agent sees).
- Multi-layer evaluation: Two automatic metrics (such as “The agent uses the right tools and provides the right parameters?”) and LLM-based judges (for evaluation of planning, grounding and reasoning).
How to test agents
Agents running the MCP bench receive a task (e.g., “plan to camp in Yosemite in a detailed logistics and weather forecast”) and must gradually decide which dialing tools, what order, and how to use their output. These workflows can span multiple rounds of interaction, synthesising agents into a coherent, evidence-backed answer.
Each agent is evaluated on several dimensions, including:
- Tool selection: Did it choose the right tool for each part of the task?
- Parameter accuracy: Does it provide complete and correct input for each tool?
- Planning and coordination: Does it handle dependencies and parallel steps correctly?
- Evidence basis: Does its final answer reference output directly from the tool, avoiding unsupported claims?
What the results show
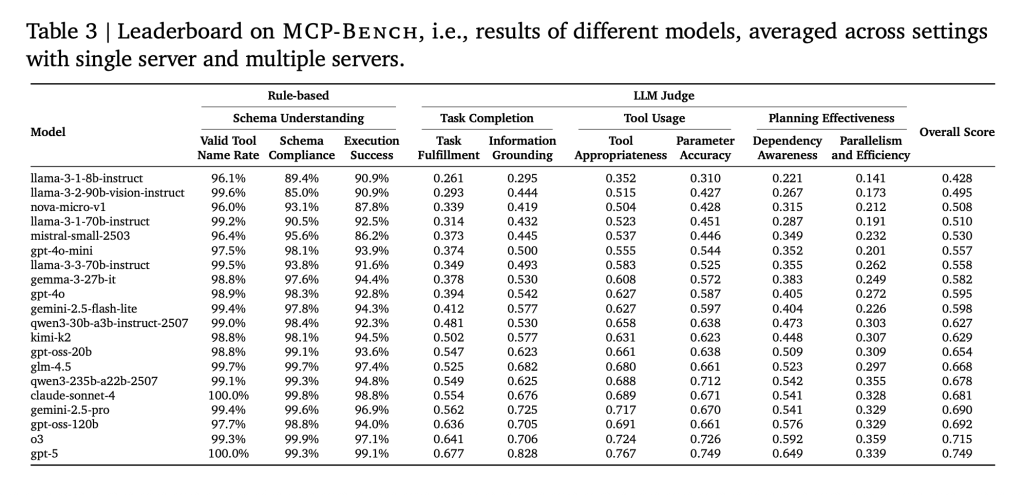
The researchers tested 20 state-of-the-art LLMs in 104 tasks. Main findings:
- The use of basic tools is reliable: Most models can call tools correctly and handle parameter patterns, even for complex or domain-specific tools.
- Planning is still difficult: Even the best models struggle with a long multi-step workflow, not only requiring a tool selection, but also understanding when to move to the next step, which parts can run in parallel, and how to handle unexpected results.
- Smaller models lag behind: As tasks become more complex, especially those that span multiple servers, smaller models are more likely to make mistakes, repeat steps, or miss subtasks.
- Efficiency differences are very large: Some models require more tool calls and interactions to achieve the same results, which suggests inefficiency in planning and execution.
- Humans still need nuances: Although benchmarks are automated, human inspections ensure that tasks are realistic and solvable, a reminder that truly powerful assessments still benefit from human expertise.
Why is this research important?
MCP Bench provides a practical way to evaluate how AI agents act as “digital assistants” in the real world, i.e. users are not always accurate, and the correct answer depends on weaving information from many sources together. This benchmark reveals the gap in current LLM capabilities, especially around complex planning, cross-domain reasoning and evidence-based synthesis, which is critical for deploying AI agents in business, research and specialization fields.
Summary
MCP Bench is a serious, large-scale test of AI agents using actual tools and real tasks, without shortcuts or manual setup. It shows that the current models perform well and that they are still lacking. For anyone who builds or evaluates AI assistants, these results, as well as the benchmarks themselves, can be useful reality checks.
Check Paper and github pages. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex datasets into actionable insights.


