How to cut your AI training bill by 80%? Oxford’s new optimizer trains 7 times faster by optimizing the way model learns
Hidden cost of AI: GPU bill
AI model training often consumes millions of dollars in GPU computing, a burden that shapes budgets, limits experiments, and slows down progress. Status: Training a modern language model or vision transformer on Imagenet-1k may burn within thousands of GPU hours. It is unsustainable for start-ups, labs and even large tech companies.
But what if you can cut your GPU bill by 87% by changing the optimizer?
That’s Fisher-Ottrotonal projection (FOP)the latest research by the Oxford University team. This article will show you why gradients are not noise, how FOP views topographic maps, and what this means for your business, models, and the future of AI.
How we train the flaws of the model
Modern deep learning dependency Gradient descent: The optimizer nudges the model parameters in the direction that the loss should be reduced. But through large-scale training, the optimizer can be used with Mini batch– Discussion of training data and average value Their gradients are obtained to obtain an update direction.
Here is the capture: The gradient of each element in the batch is always different. The standard method treats these differences as random noise and smooths them to maintain stability. But in fact, This “noise” is a key directional signal about losing the true shape of the landscape.
FOP: Terrain Awareness Navigator
fop treat The difference between gradients within a batch is not noise, but topographic map. It requires an average gradient (main direction) and project Build a difference Geometric, curvature-sensitive components This will keep the optimizer away from the walls and canyon floors, even if the main direction is directly forward.
How it works:
- Average gradient Point to the road.
- Difference gradient As a terrain sensor, revealing whether the landscape is flat (can be moved safely) or steep walls (slow down and stay in the canyon).
- FOP combines two signals: It adds a “bending” step orthogonal in the main direction Make sure it never fights or exaggerates.
- result: Even in Extreme batch size– SGD, ADAMW and even the most advanced KFAC failed regime.
In deep learning terms: FOP is applicable Fisher-Ottrotonal correction On top of standard natural gradient descent (NGD). By retaining this feature In-batch differenceFOP maintenance related Local curvature The signal of the loss pattern was previously lost in the mean.
FOP in practice: 7.5 times faster on Imagenet-1k
The result is dramatic:
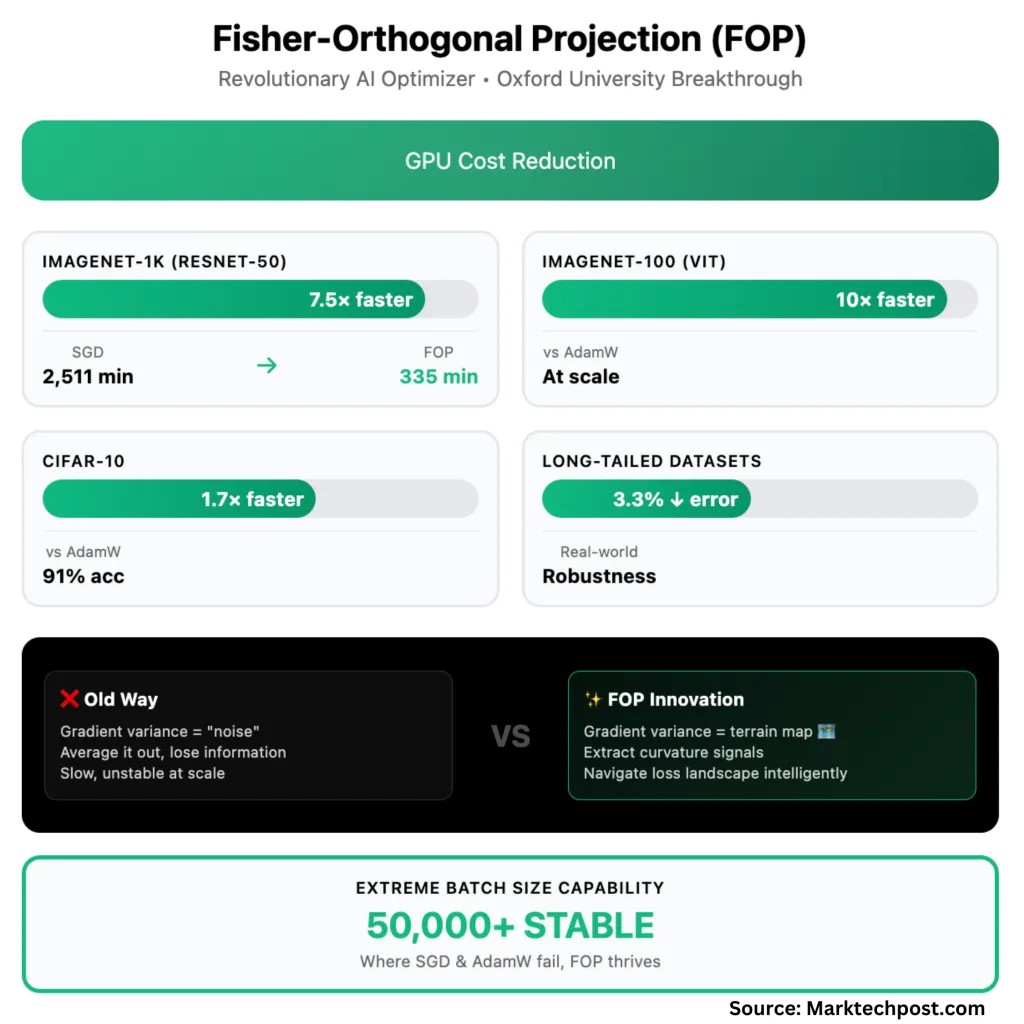
- Imagenet-1k (Resnet-50): To achieve standard verification accuracy (75.9%), SGD It takes 71 eras and 2,511 minutes. FOP achieves the same accuracy in only 40 epochs and 335 minutes – a 7.5x wall-mounted acceleration.
- CIFAR-10: Fop is 1.7 times faster More than Adamw, 1.3 times faster Compared to KFAC. With maximum batch size (50,000), Only FOP achieves 91% accuracy;Others failed completely.
- Imagenet-100 (visual transformer): Fop is Up to 10 times More than Adamw, 2 times faster Compared to KFAC, the largest batch.
- Long tail (unbalanced) dataset: FOP passed 2.3–3.3% Over powerful baselines – meaningful benefits of messy data in the real world.
Memory usage: The peak GPU memory footprint of FOP is high for small-scale jobs, but when distributed on many devices, it matches KFAC – savings far outweigh the cost.
Scalability: fop Even if the batch size climbs to thousands– Others that can be done without other optimizers. With more GPUs, Training time decreases almost linearly– Unlike existing methods, it usually degrades with parallel efficiency.
Why this is important for business, practice and research
- Business: Training costs reduced by 87% Changed the economics of the development of artificial intelligence. This is not an increment. Teams can reinvest savings into larger, more ambitious models, or build moats with faster, cheaper experiments.
- Practitioners: FOP is a plugin: This article’s open source code can be removed into an existing Pytorch workflow with single-line changes No additional adjustments. If you use KFAC, you’re already half there.
- Researchers: FOP redefines the “noise” in gradient descent. In-batch differences are not only useful, but are essential. The robustness of data imbalanced data It is a reward for realistic deployment.
How FOP changes landscape
Traditionally, large quantities are a curse: They unstable SGD and ADAMW, and even KFAC (with natural gradient curvature) collapses. FOP turned it to it. By preservation and utilization Gradient variation in batchesit unlocked Stable, fast, scalable training in unprecedented batch sizes.
FOP is not an adjustment, but a basic thinking about which signals are valuable in optimization. The average “noise” you make today is Your terrain map tomorrow.
Summary table: FOP and current situation
| Metric system | SGD/ADAMW | KFAC | FOP (this job) |
|---|---|---|---|
| Wall lock acceleration | Baseline | 1.5–2x faster | Faster speed up to 7.5 times |
| Large batch stability | fail | Stall, need damping | Extreme work |
| Robustness (unbalanced) | Poor | Modesty | The best lesson |
| Plugin | Yes | Yes | Yes (installable PIP) |
| GPU memory (distributed) | Low | Easing | Easing |
Summary
Fisher-Ottrothonal projection (FOP) is a leap in large-scale AI training, with convergence speeds up to 7.5 times on Imagenet-1k (Imagenet-1k) in very large batch sizes, while also improving generalization – reducing the error rate by 2.3-3.3%, while facing adverse, unfavorable, unfavorable base markers. Unlike traditional optimizers, FOP extracts and utilize gradient variance to browse the true curvature of the lost landscape, using information that was previously discarded as “noise”. Not only does this cut GPU compute costs (87%), it also enables researchers and companies to train larger models, iterate faster and maintain robust performance, even on real-world data imbalanced data. Through Pytorch implementation of plug-in and minimal tweaking, FOP provides a practical and scalable path for next-generation machine learning.
Check Paper. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
 framework that can partially reveal tokens during sampling")

