Google AI’s new regression language model (RLM) framework allows LLM to predict industrial system performance directly from raw text data
Google’s new regression language model (RLM) approach allows large language models (LLMS) to predict industrial system performance directly from raw text data without relying on complex functional engineering or rigid tabular formats.
Challenges of industrial system forecasting
Traditionally, the performance of large-scale industrial systems (such as Google’s Borg computing cluster) traditionally requires extensive domain-specific functional engineering and tabular data representations, making scalability and adaptability difficult. For classic regression models, logs, configuration files, variable hardware mixes and nested job data cannot be easily flattened or normalized. As a result, optimization and simulation workflows often become vulnerable, expensive, and slow, especially when introducing new workloads or hardware.
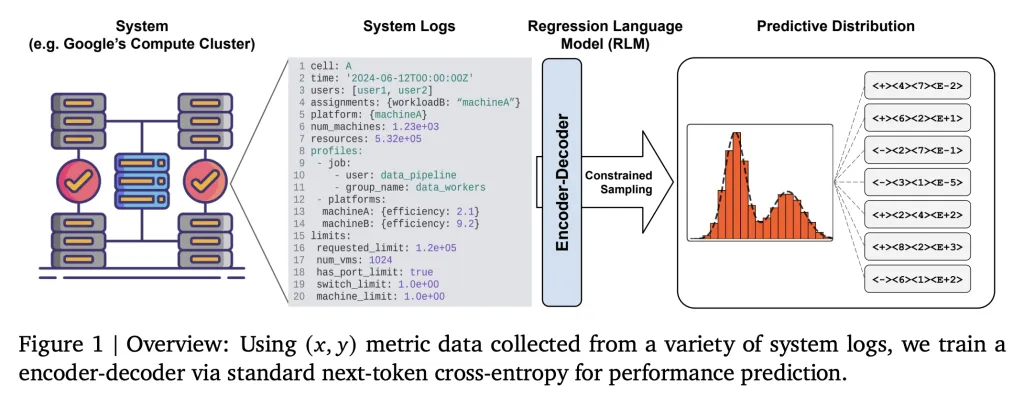
Main idea: text to text return
Google’s regression language model (RLM) redefines regression as text generation tasks: all system state data (configuration, logs, workload configuration files, hardware descriptions) are serialized into structured text formats such as YAML or JSON and used as input prompts xxx. The regression model then outputs a numerical target YYY (such as efficiency metrics (instructions per second per second, instructions per GCU) as a text string response.
- No table function required: This eliminates the need for predefined feature sets, normalization and rigid coding schemes.
- General Applicability: Any system state can be represented as a string; heterogeneous, nested or dynamically developed features are supported locally.
Technical details: Architecture and training
This method uses a relatively small encoder decoder llm (60m parameter), which is trained by the next cross-penetration loss on the string representation of XXX and YYY. The model has not been identified on general language modeling – training can start with random initialization, focusing directly on the system state associated with the digital results.
- Custom digital tokenization: The results are effectively tokenized (e.g. P10 Mantissa-Sign-Exponent encoding) to represent floating point values in the model vocabulary.
- Almost no adaptations: Preprocessed RLM can be quickly fine-tuned in new tasks for new tasks, adapting to new cluster configurations or within hours (rather than weeks).
- Sequence length scaling: The model can process very long input text (thousands of tokens), ensuring that complex states are fully observed.
Performance: Results of Google’s Borg cluster
Tested on BORG cluster, RLMS achieved 0.99 Spearman level related (Average 0.9 per GCU and real MIPS), 100 times lower square error Compared with the table baseline. These models support probabilistic system simulation and Bayesian optimization workflows by quantitatively quantifying the uncertainty by performing multiple outputs on each input.
- Quantification of uncertainty: Unlike most black box regressors, RLMS captures both non-existent (inherent) and cognitive (due to limited observability) uncertainty (unknown).
- General simulator: The density modeling capabilities of RLMS show that they are used for universal digital twins for large-scale systems, accelerating infrastructure optimization and real-time feedback.
Comparison: RLM vs. Regression of Traditional
| method | Data format | Functional Engineering | Adaptability | Performance | uncertain |
|---|---|---|---|---|---|
| Table Regression | Flat tensor, number | Need to be manually | Low | Restricted by functions | Minimum |
| RLM (text to text) | Structured nested text | No need | High | Close to perfect ranking | Full spectrum |
Application and Summary
- Cloud and Computing Clusters: Direct performance prediction and optimization of large dynamic infrastructures.
- Manufacturing and the Internet of Things: Universal simulator to predict results across various industrial pipelines.
- Scientific experiments: End-to-end modeling, complex input state, text description and digit diversification.
This new approach (processing regression as language modeling) occupies a long-standing obstacle in system simulations, can quickly adapt to new environments and support strong uncertainty-aware predictions, which are crucial for next-generation industrial AI.
Check Paper, code and technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


