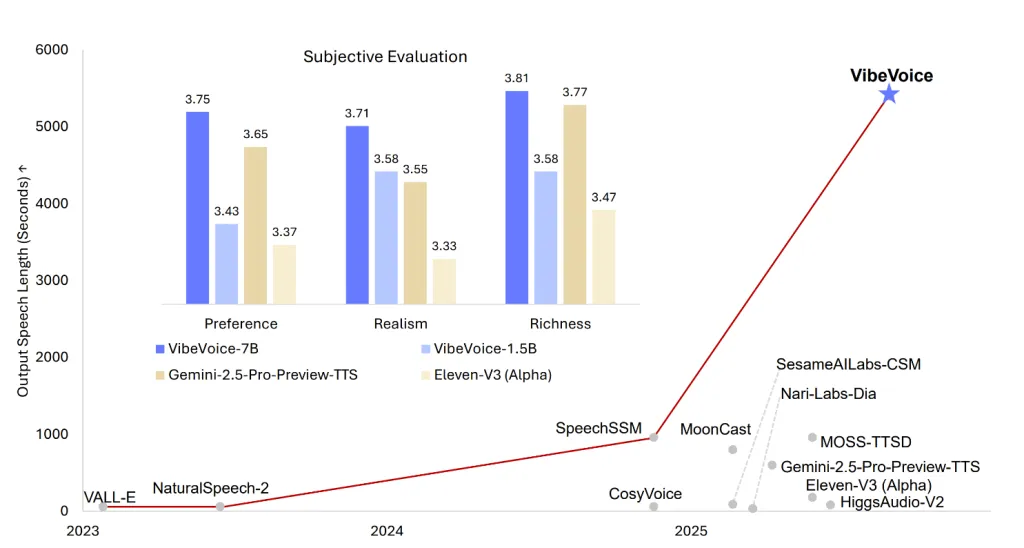
Microsoft releases Vibevoice-1.5B: an open source text-to-speech model that synthesizes 90 minutes of voice with four different speakers
Microsoft’s latest open source version, VIBEVOICE-1.5BRedefines the boundaries of text-to-speech (TTS) technology – delivering expressive, long form, multi-speaker-generated audio that has been licensed by MIT, scalable and highly flexible for research use. This model is not only another TTS engine. This is a framework designed to generate uninterrupted, natural sound audio for up to 90 minutes, supports simultaneous generation of up to four different speakers, and even handles synthetic scenarios across languages and singing. With its streaming architecture and larger 7B model, Vibevoice-1.5B positioned itself as a major advance in AI-powered dialogue audio, podcasting and synthetic voice research.
Key Features
- Lots of background and multiple speaker support: vibevoice-1.5b can be synthesized 90-minute speech most Four different speakers In one session, the typical speaker limit for the traditional TTS model exceeded the typical 1-2 speaker limit.
- Generate at the same time: This model not only stitches single element clips together; it is designed to support Parallel audio stream For multiple speakers, imitate natural dialogue and turn.
- Translinguality and singing synthesis: Although mainly trained in English and Chinese, this model can Translingual synthesis Even singing can be produced – functionality is rarely demonstrated in previous open source TTS models.
- MIT License: Fully open source and business-friendly with a focus on research, transparency and repeatability.
- Scalable streaming and long audio: The architecture is for Effective long-term synthesis And expected to be coming soon 7B can stream media Model, further expanding the possibility of real-time and high-fidelity TT.
- Emotion and expressiveness: The model is touted as Emotional control and Natural Expressionmaking it suitable for applications like podcasts or conversation scenes.
Architecture and technology dive
The basis of Vibevoice is 1.5B parameter LLM (QWEN2.5-1.5B) This blends with two new primers –acoustics and Semantics– aimed at Low frame rate (7.5Hz) Used for computational efficiency and consistency across sequences.
- Sound Token: A σ-VAE variant with mirror encoder decoder structure (about 340m parameters each), implementing 3200x downsampling Original audio from 24kHz.
- Semantic Token: Training through ASR proxy tasks, this code-only architecture reflects the design of the acoustic token (minus VAE components).
- Diffusion decoder head: Lightweight (approximately 123 million parameters) conditional diffusion module predicts acoustic characteristics, classifier-free guidance (CFG) and DPM-solvent agent perceived quality.
- Context-length course: Training starts with 4K tokens and then expands to 65K token– Make the model generate very long, coherent audio bands.
- Sequence Modeling:LLM understands the dialogue flow to turn, while the diffusion head produces fine-grained acoustic details – separating semantics and synthesis while retaining the speaker’s identity for a long time.
Model limitations and responsible use
- English and Chinese only: This model trains only these languages; other languages may produce unintelligible or offensive output.
- No overlapping speeches: While it supports turn, Vibevoice-1.5b does Voice not overlapping models Between the speakers.
- Pure voice:Model No background sound, Foley or music– Strict voice output is speech.
- Legal and moral hazard: Microsoft explicitly prohibits use Voice imitation, false information or authentication bypass. Users must abide by the law and disclose content generated by AI.
- Not suitable for professional real-time application: Although valid, this version is Not optimized for scenarios with low latency, interactive or real-time processes;This is what the upcoming 7B variant is aimed at.
in conclusion
Microsoft’s VIBEVOICE-1.5B is a breakthrough for open TTS: scalable, expressive and multi-speaker with a lightweight diffusion-based architecture that unlocks long format, dialogue audio synthesis for researchers and open source developers. Although currently used Research-centered And limited to English/Chinese, the functionality of the model and the promise of the upcoming version – the paradigm of signals shifts the paradigm shift in how AI generates and interacts with synthetic speech.
For technical teams, content creators and AI enthusiasts, VIBEVOICE-1.5B Is a compulsory tool for the next generation of synthetic voice applications – clear documentation and open licenses are available now on Embrace Face and Github. With the scene moving toward a more expressive, interactive and morally transparent TT, Microsoft’s latest offering is a landmark of open source AI voice synthesis.
FAQ
What makes Vibevoice-1.5b different from other text-to-speech models?
Vibevoice-1.5b can be generated 90 minutes of expressive audio (up to four spokespersons), support for cross-language and singing synthesis, and fully open source under MIT license – exhausted the boundaries of long-term conversation AI audio generation
What hardware is recommended to run locally?
Community testing shows that multispeaker dialogs are generated using 1.5 B checkpoints ≈7GB GPU VRAMso an 8 GB consumer card (e.g., the RTX 3060) is usually enough to infer.
What languages and audio styles are supported by this model today?
Vibevoice-1.5b is Only receive English and Chinese training And can be executed Translingual narrative (e.g. English tips → Chinese speech) and basic Singing synthesis. It produces only speech – no background sound, and does not model overlapping speakers; the turns are sequential.
Check Technical Report,,,,, Model embracing face and Code. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


