Zenflow: A new DeepSpeed extension designed as a stall-free offload engine for large language models (LLM) training
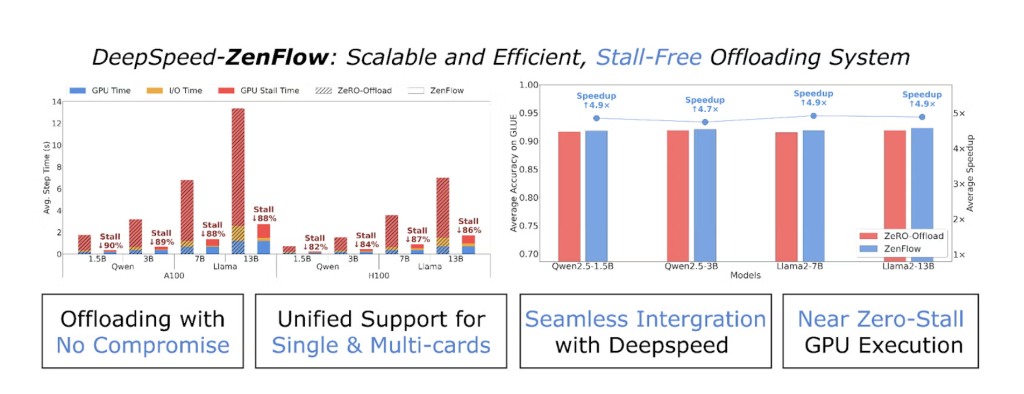
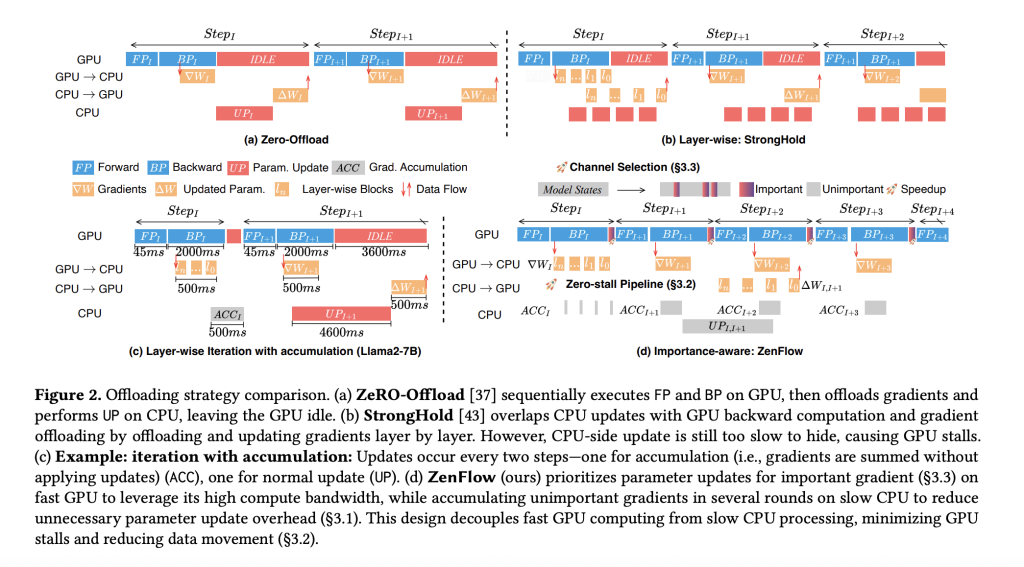
DeepSpeed team unveiled ZenflowThis is a new uninstall engine designed to overcome the main bottleneck of large language model (LLM) training: CPU-induced GPU stalls. Traditional frameworks like Zero Local Framework and Zero Intelligence often leave expensive GPU idle in every training step when uninstalling optimizers and gradients to relieve GPU memory pressure – waiting in terms of slow CPU updates and PCIE transfers. For example, a fine-tuned milk pull 2-7b on a 4×A100 GPU with complete unloading can gradually decelerate from 0.5 seconds to over 7 seconds, and 14× speed deceleration. Zenflow By dismantling GPU and CPU calculations, these stalls are eliminated and with importance-aware pipe lining, it provides up to 5x end-to-end speeds on zero downloads and reduces GPU stalls by more than 85%.
How Zenflow works
- Importance Awareness of Gradient Updates: Zenflow prioritizes the most influential gradients for immediate GPU updates while deferring less important gradients to the asynchronous CPU side accumulation. This reduces gradient flow per step by nearly 50% compared to zero downloads and reduces PCIE bandwidth pressure by about 2×.
- Limited – Synchronous CPU accumulation: The non-critical gradients are batched and updated on the CPU, hiding CPU work behind GPU calculations. This ensures that the GPU is always busy, avoids stalls and maximizes hardware utilization.
- Lightweight gradient selection: Zenflow replaces the full-gradient Allgather with a lightweight, per-column specification agent, reducing traffic by more than 4,000 times, with little impact on accuracy. This can be scaled efficiently on multi-GPU clusters.
- Zero code changes, minimum configuration: Zenflow is built into DeepSpeed and requires only minor JSON configuration changes. User settings parameters such as
topk_ratio(For example, the top 5% of the gradient is 0.05), and enable adaptive policiesselect_strategy,,,,,select_intervalandupdate_intervalSet as"auto". - Automatic performance adjustment: The engine adjusts the update intervals during operation, eliminating the need for manual adjustments as training dynamics develop and ensuring maximum efficiency.
Performance Highlights
| feature | Influence |
|---|---|
| Up to 5× end-to-end speed | Faster convergence speed, lower cost |
| > 85% GPU stall reduction | High GPU utilization |
| ≈2×Reduce PCIE traffic | Smaller cluster bandwidth pressure |
| No accuracy loss for glue benchmarks | Maintain model quality |
| Lightweight gradient selection | Efficiently scale to multi-GPU clusters |
| Automatic adjustment | No manual parameter adjustment required |
Practical usage
Integration: Zenflow is a zero-downloaded pour extension for DeepSpeed. No code changes are required; only configuration updates are required in the DeepSpeed JSON file.
Example Use Cases: The DeepSpeedExamples repository includes a Zenflow Finetuning Example On the glue benchmark. Users can run this using a simple script (bash finetune_gpt_glue.sh), follow the settings and configuration instructions in the repository’s reading. This example demonstrates the uninstallation of the CPU optimizer with Zenflow asynchronous updates, providing a practical starting point for experiments.
Configuration example:
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"zenflow": {
"topk_ratio": 0.05,
"select_strategy": "auto",
"select_interval": "auto",
"update_interval": 4,
"full_warm_up_rounds": 0,
"overlap_step": true
}
}
getting Started: See the DeepSpeed-Zenflow Finetuning example and official tutorial for step-by-step instructions.
Summary
Zenflow It’s a big leap for anyone who trains or works on large language models on limited GPU resources. By effectively eliminating CPU-induced GPU stalls, it unlocks higher throughput and lower overall training costs without sacrificing the accuracy of the model. This approach is particularly valuable for organizations that scale LLM workloads in heterogeneous hardware or seek to maximize GPU utilization in cloud or on-premises clusters.
For technical teams, Automatic adjustment,,,,, Minimum configurationand Seamless integration Use DeepSpeed to make Zenflow both accessible and powerful. The examples and files provided reduce barriers to adoption and enable rapid experimentation and deployment.
Zenflow redefined the offload of LLM training, providing booth-free high-throughput fine-tuning with minimal configuration overhead, which is essential for anyone pushing the boundaries of large-scale AI.
Check Technical papers,,,,, Github page and blog. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Sana Hassan, a consulting intern at Marktechpost and a dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. He is very interested in solving practical problems, and he brings a new perspective to the intersection of AI and real-life solutions.


