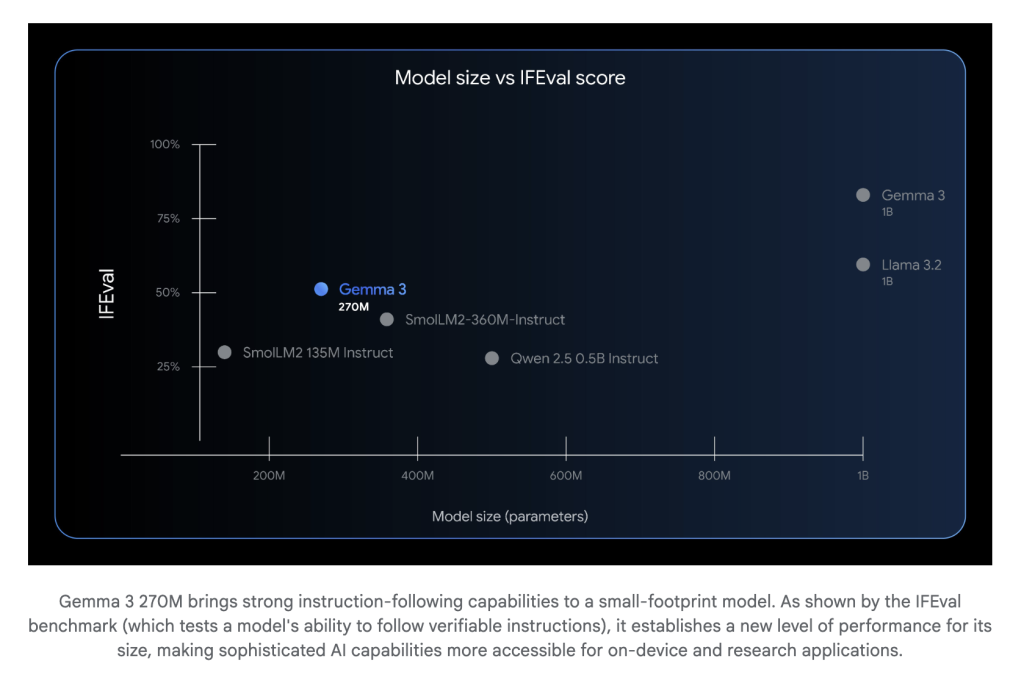
Google AI introduces the Gemma 3 270m: a compact model for task-specific fine-tuning
Google AI introduces the Gemma family Gemma 3 270ma streamlined 270 million parameter basic model, clearly established to improve efficiency, Task-specific fine-tuning. This model proves powerful Guide and follow And advanced Text structure function “Out of the box”, which means it can be deployed and customized immediately with minimal additional training.
Design philosophy: “The right tool for work”
Unlike large models designed for a general understanding, the Gemma 3 270m is designed for target use cases where efficiency exceeds pure power. This is crucial for scenarios such as device AI, privacy-sensitive inferences, and a large number of well-defined tasks. Text classification, entity extraction and compliance checks.
Core functions
- A large number of 256K experts adjust vocabulary:
The Gemma 3 2700M uses approximately 170 million parameters for its embedding layer, supporting a huge 256,000-line vocabulary. This makes it possible to handle Rare and professional tokensmaking it ideal for domain adaptation, niche industry jargon or custom language tasks. - Extreme energy efficiency of device AI:
Internal benchmarks show that the INT4 quantitative version of the Pixel 9 Pro consumes less than 1% of the battery in 25 typical conversations, the most effective Gemma to date. Now developers can deploy capable models into mobile, edge, and embedded environments without sacrificing responsiveness or battery life. - Prepare for production using INT4 Quantitative Awareness Training (QAT):
Gemma 3 270m arrives Quantitative perception training checkpointso it can be 4-bit accuracy, insignificant quality loss. This unlocks production deployments on devices with limited memory and compute, allowing for local, encrypted inference and increased privacy guarantees. - Instructions for packaging frames:
As two Pre-training and Instruction adjustment Model, the Gemma 3 270m can immediately understand and follow structured tips, while developers can further professionally behave with just a few fine-tuning examples.
Highlights of the model architecture
| Element | Gemma 3 270m specifications |
|---|---|
| Total parameters | 270m |
| Embed parameters | ~170m |
| Transformer block | ~100m |
| Vocabulary size | 256,000 tokens |
| Context window | 32K token (1B and 270m sizes) |
| Precision mode | BF16, SFP8, INT4 (QAT) |
| Minimum. RAM usage (Q4_0) | ~240MB |
Fine Tuning: Workflows and Best Practices
The Gemma 3 270m is carefully designed to provide fast, expert surveys centralized data sets. The official workflow explained in Google’s Embrace Face Transformers guide involves:
- Dataset preparation:
Small, well-curved datasets are usually sufficient. For example, teaching a conversation style or a specific data format may only require 10-20 examples. - Coach configuration:
With the SFTTrainer and configurable optimizer (ADAMW, CONSTER scheduler, etc.) embracing Face TRL, the model can be fine-tuned and evaluated, and the loss curve can be compared and overfitted or inadequate are monitored. - Evaluate:
Post-training reasoning tests show dramatic role and format adaptation. Overfitting, often a problem, becomes beneficial here – make sure to “forget” common sense for highly professional characters (e.g., role-playing game NPC, custom journal, industry compliance). - deploy:
Models can be pushed onto the hug hub and run on local devices, cloud or Google’s Vertex AI with near-inherent loading and minimal computing overhead.
Real-world applications
The company likes it Adaptive ML and SK Telecom Use Gemma models (4B size) to outperform larger proprietary systems Multilingual content review– Revealing Gemma’s professional advantages. Smaller models, such as 270m, enable developers to:
- maintain Multiple professional models For different tasks, reduce costs and infrastructure requirements.
- Enable Rapid prototyping and iteration Thanks to its size and calculations thrifty.
- Ensure privacy By specifically executing AI, there is no need to transfer sensitive user data to the cloud.
in conclusion:
Gemma 3 270m Marking a paradigm shift toward efficient, adjustable AI – developers are able to deploy high-quality, guided follow-up models for extremely focused needs. It combines compact size, power efficiency and open source flexibility, which not only makes it a technological achievement, but also a practical solution for next-generation AI-driven applications.
Check Technical details are here and Model embracing face. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.


