Alibaba QWEN unveils QWEN3-4B-INSTRUCT-2507 and QWEN3-4B-INCKINGING-2507: The importance of refreshing small language models
Smaller models with smarter performance and 256K context support
Alibaba’s Qwen team introduced two powerful additions to its small language model lineup: QWEN3-4B-INSTRUCT-2507 and QWEN3-4B-INCKINGING-2507. Despite only 4 billion parameters, these models offer excellent functionality in general and expert tasks while operating effectively on consumer hardware. Both are designed Native 256K Token Context Windowwhich means they can handle very long inputs, such as large code bases, multi-file archives, and extended conversations without external modifications.
Architecture and core design
Both models have Total parameters are 4 billion (3.6b does not include embedding) 36 transformer layers. They use Group Query Attention (GQA) and 32 query headers and 8 keys/value headersimproves the efficiency and memory management of a very large environment. They are Dense transformer architecture– Not a mixture of experts – ensures consistent task performance. A long post says support 262,144 tokens Bake directly into the model architecture and make extensive predictions for each model before proceeding After training alignment and after safety To ensure responsible high-quality output.
QWEN3-4B-INSTRUCT-2507 – A multilingual, follower generalist
this QWEN3-4B-INSTRUCT-2507 Models have been optimized for speed, clarity and user alignment instructions. It aims to provide direct answers without clear step-by-step reasoning, making it ideal for situations where users want concise responses rather than detailed thinking processes.
Multilingual coverage More than 100 languagesmaking it ideal for global deployment of chatbots, customer support, education and cross-language search. It is Local 256K context support Enable it to handle tasks such as analyzing large legal documents, processing multi-hour transcripts, or aggregating large data sets without breaking down content.
Performance benchmark:
| Benchmark tasks | Fraction |
|---|---|
| Common Sense (MMLU-PRO) | 69.6 |
| Reasoning (AIME25) | 47.4 |
| SuperGPQA (QA) | 42.8 |
| Encoding (livecodebench) | 35.1 |
| Creative Writing | 83.5 |
| Multilingual understanding (Multiif) | 69.0 |
Actually, this means qwen3-4b-instruct-2507 can handle the Language Tutoring Multilingual arrive Generate rich narrative contentwhile still providing qualified performance in reasoning, coding and domain-specific knowledge.
QWEN3-4B-INCKINGING-2507 – Expert-level thinking reasoning
Where the instructing model focuses on concise responsiveness QWEN3-4B-INCKINGING-2507 The model is for Deep reasoning and problem solving. It will automatically generate an explicit Thought chain In its output, make its decision-making process transparent – especially beneficial to complex areas such as mathematics, science and programming.
The model is Technical diagnosis,,,,, Scientific data explanationand Multi-step logic analysis. It is suitable for advanced AI agents, research assistants, and coding partners who need to reason through questions before answering.
Performance benchmark:
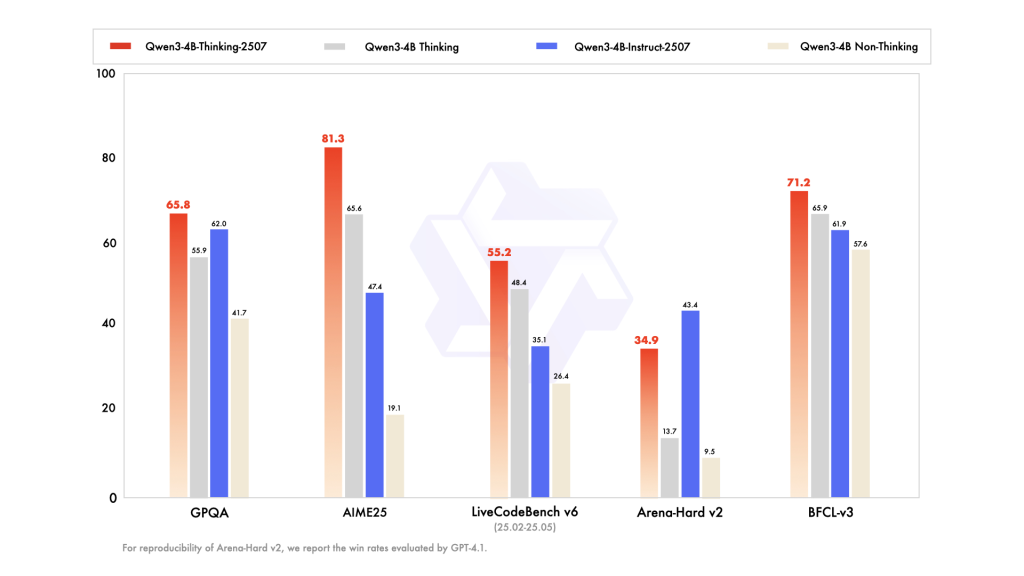
| Benchmark tasks | Fraction |
|---|---|
| Mathematics (AIME25) | 81.3% |
| Science (HMMT25) | 55.5% |
| General Quality Inspection (GPQA) | 65.8% |
| Encoding (livecodebench) | 55.2% |
| Tool usage (BFCL) | 71.2% |
| Human Alignment | 87.4% |
These scores suggest that QWEN3-4B-INCKINGING-2507 can match or exceed larger models in heavier benchmarks, thus providing more accurate and interpretable results for mission-critical use cases.
In two models
Both mentoring and thinking variants share key advancements. this 256K local context window Allows seamless work on extremely long inputs without external memory hacks. They also have characteristics Improved alignmentgenerates more natural, coherent and context-aware responses in creative and multi-turn dialogue. Furthermore, both are Agent preparationsupports API calls, multi-step reasoning and workflow orchestration.
From a deployment standpoint, they are very effective and can continue to run Mainstream consumer GPU Quantify lower memory usage and is fully compatible with modern inference frameworks. This means that developers can Run them locally or scale them in a cloud environment No large investment in resources.
Actual deployment and application
The deployment is simple. Extensive framework compatibility Make integration into any modern ML pipeline. They can be used in edge devices, enterprise virtual assistants, research institutions, coding environments and creative studios. Example scenarios include:
- Guidance Following Mode: Customer support robot, multilingual education assistant, real-time content generation.
- Thinking mode: Scientific research analysis, legal reasoning, advanced coding tools and proxy automation.
in conclusion
QWEN3-4B-INSTRUCT-2507 and QWEN3-4B-INCKINGING-2507 prove this Small language models can compete in a specific domain, or even surpass large models When thought through. They blend long-term cultural processing, strong multilingual abilities, profound reasoning (in thinking patterns) and alignment improvements make them powerful tools for everyday and expert AI applications. With these versions, Alibaba sets new benchmarks for production 256K prepared high-performance AI model Developers around the world are accessible.
Check QWEN3-4B-INSTRUCT-2507 model and QWEN3-4B-INCKINGING-2507 model. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to subscribe Our newsletter.

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex data sets into actionable insights.


 by 64 times, better in planning, reaching 94% accuracy")