ERARAG: A scalable, multi-layer graph-based retrieval system for dynamic and growing corpus
Large language models (LLMS) revolutionize many areas of natural language processing, but they still face key limitations when dealing with the latest facts, domain-specific information, or complex multi-hop-on reasoning. Retrieval-enhanced generation (RAG) approaches are designed to address these gaps by allowing language models to retrieve and integrate information from external sources. However, as data continues to grow (such as in news feeds, research repositories, or user-generated online content), most existing graph-based rag systems are optimized for static corpus and struggle with efficiency, accuracy, and scalability.
Introducing Erarag: Effective updates of evolving data
Recognizing these challenges, researchers at Huawei, the Hong Kong University of Science and Technology, as well as the network have developed EraragThis is a novel search generation framework designed for dynamic, ever-expanding corpus. Instead of rebuilding the entire search structure when new data arrives, Erarag relies on localized selective updates that touch only those parts of the search graph affected by the changes.
Core functions:
- Locally sensitive hashing (LSH) based on hyperplane:
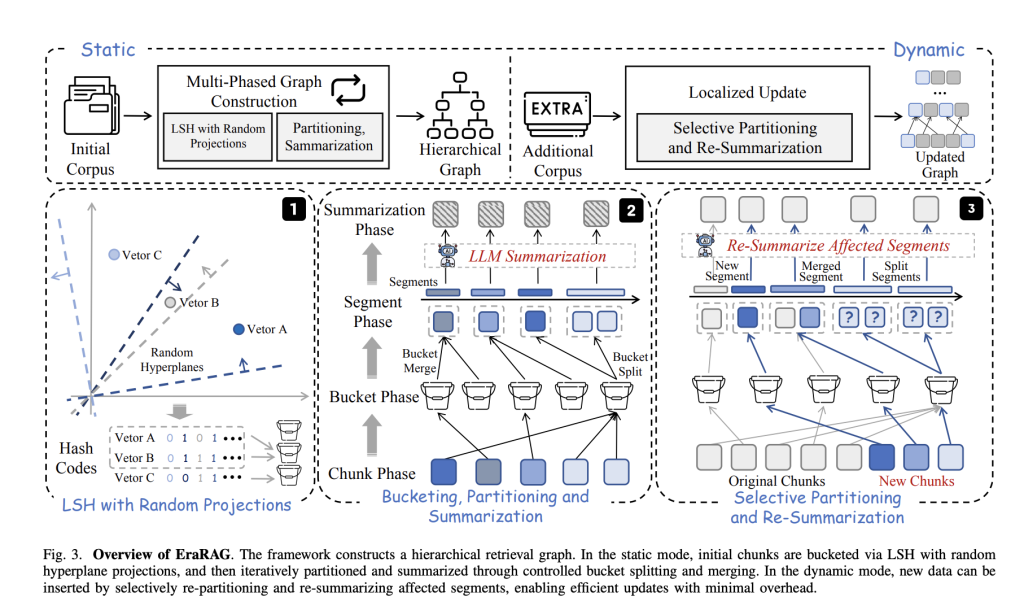
Each corpus is broken down into small text paragraphs embedded as vectors. Erarag then uses a randomly sampled hyperplane to cast these vectors into binary hash codes, which process groups semantically similar blocks into the same “buckets”. This LSH-based approach maintains both semantic coherence and efficient grouping. - Hierarchical, multi-layer graph structure:
The core search structure in Erarag is multi-layered graph. In each layer, text-like fragments (or buckets) are summarized using language models. Fragments that are too large are separated, while segments that are too small are merged to maintain semantic consistency and balanced granularity. A summary of higher-levels indicates that it can be retrieved effectively for fine-grained and abstract queries. - Incremental localization update:
When new data arrives, its embedding will use the original hyperplane scatter to ensure consistency with the initial graph structure. Only buckets/segments directly affected by new entries can be updated, merged, split or re-united, while the rest of the chart is still not touched. The update propagates the graph hierarchy but always maintains localization with the affected area, saving a lot of computing and token costs. - Repeatability and certainty:
Unlike standard LSH clustering, Erarag retains a set of hyperplanes used during the initial hashing. This makes bucket allocation certain and reproducible, which is crucial for consistent, effective updates over time.
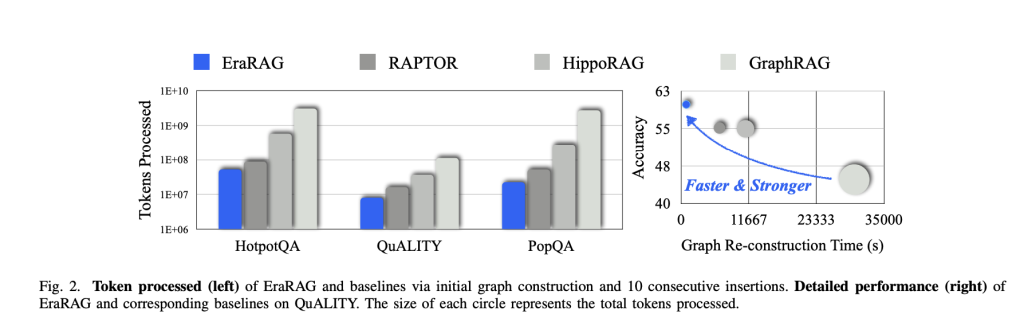
Performance and impact
A comprehensive experiment on various questions about the answer benchmark shows that Erarag:
- Reduce update costs: Graph Rebuild Time and Token Usage are up to 95% compared to graph-based rag methods (e.g., GraphRag, Raptor, Hipporag).
- Maintain high accuracy: Erarag always outperforms other search architectures in accuracy and recollection, i.e. static, growth and abstract answer tasks – with minimal tradeoffs in terms of retrieval quality or multi-hop reasoning ability.
- Support multi-function query requirements: Multi-layer graph design allows Erarag to effectively retrieve fine-grained factual details or high-level semantic summary, thereby tailoring its search pattern based on the sexual quality of each query.
Actual meaning
Erarag provides a scalable and powerful retrieval framework that is ideal for real-world settings that constantly add data such as real-time news, academic archives, or user-driven platforms. It strikes a balance between retrieval efficiency and adaptability, making LLM-powered applications more factual, responsive and trustworthy in rapidly changing environments.
Check Paper and github. All credit to this study is attributed to the researchers on the project | Get to know AI development communication read 40K+ developers And researchers from NVIDIA, OpenAi, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgan, Aflac, Aflac, Wells Fargo and 100s [SUBSCRIBE NOW]
Nikhil is an intern consultant at Marktechpost. He is studying for a comprehensive material degree in integrated materials at the Haragpur Indian Technical College. Nikhil is an AI/ML enthusiast and has been studying applications in fields such as biomaterials and biomedical sciences. He has a strong background in materials science, and he is exploring new advancements and creating opportunities for contribution.


