Google researchers present LSM-2 (AIM) with adaptive and genetic masking: learning directly from incomplete wearable data
introduce
Wearable devices alter health monitoring by continuously collecting physiological and behavioral signals such as heart rate, activity, temperature, and skin conductance. However, the real data generated by these devices is very prone to missing due to sensor failures, disassembly of devices, charging, motion artifacts, battery saving modes and other interruptions. This presents significant challenges for self-supervised learning (SSL) and underlying models, often expecting a complete conventional data stream. Past solutions often rely on data interpolation or discarding incomplete instances that have the potential to introduce bias or waste valuable information.
A team of researchers at Google DeepMind introduced the LSM-2 (Large Sensor Model 2) framework, which is composed of the new adaptive and inherited masking (AIM) strategy, to directly add these issues to these issues, learning powerful representation representations from incomplete wearable sensor data without explicit insertion. Below, we examine this advance in technological innovation, empirical results and key insights.
Challenge: Loss of wearable data
- Data fragmentation: In a large-scale dataset of wearable data samples (1.6 million days (1440 minutes), 0% The complete integrity of the sample; the loss is everywhere, usually forming a long distance gap rather than a simple random dropout.
- Missing mode: Common reasons include:
- Device off (recharge or not wear)
- Selective sensor deactivation (energy saving or specific operation)
- Moving workpiece or ambient noise
- Ranges or physiologically impossible readings filtered out during pretreatment
- Impact on modeling: Many clinically relevant physiological patterns (e.g., circadian rhythm, heart rate variability) require analysis of long sequences, which almost guarantees the absence.
Adaptive and Inheritance Masking (AIM): Technical Methods
Key concepts
Purpose Integrate two masking types for robust learning:
- Inherited mask: Tagged token, corresponding to the true missing in sensor data
- Artificial mask: Randomly masked the observed tokens to provide reconstruction objectives for self-supervised pre-deliberation
These masks are joint And processed through a transformer-based encoder structure, the model can:
- Learn directly from non-input, incomplete data
- Dynamically adjust to the missing in the real world during reasoning
- Produce a powerful representation of the data gap between parts and systems
Strategies for masking preprocessing
- Random insertion: 80% drop of token analog sensor noise
- Time slice: Discard 50% of the temporal window (all sensors are missing in random time)
- Sensor slice: Discard 50% of sensor channels throughout the day (model the selective sensor)
AIM combines the efficiency of dropout masking (removed from the calculation) and the flexibility of attention masking (supporting loss of dynamic variations), allowing the model to scale to long input sequences (long, > 3,000 tokens per day).
Dataset and preprocessing details
- scale: Up to 40 million hours of multimodal sensor data, collected from 60,440 participants between March and May 2024.
- sensor: Photophotography (PPG), accelerometer, electromuscular activity (EDA), skin temperature and altimeter. Each device forms a clever summary function on a 24-hour window.
- Population diversity: Participants in various ages (18-96), gender and BMI courses.
- Data for downstream tags:
- Metabolic Studies (Hypertension, Anxiety Prediction; n = 1,250 Markers Users)
- Activity Identification (20 Activity Categories, 104,086 Events).
Evaluation and results
Downstream tasks
AIM-based LSM-2 was evaluated:
- Classification: Binary hypertension, anxiety and level 20 activity recognition
- return: Age and BMI
- generate: Recover missing sensor data (random interpolation, time/signal gap)
Quantitative results
| Task | Metric system | The best LSM-1 | LSM-2 W/ AIM | improve |
|---|---|---|---|---|
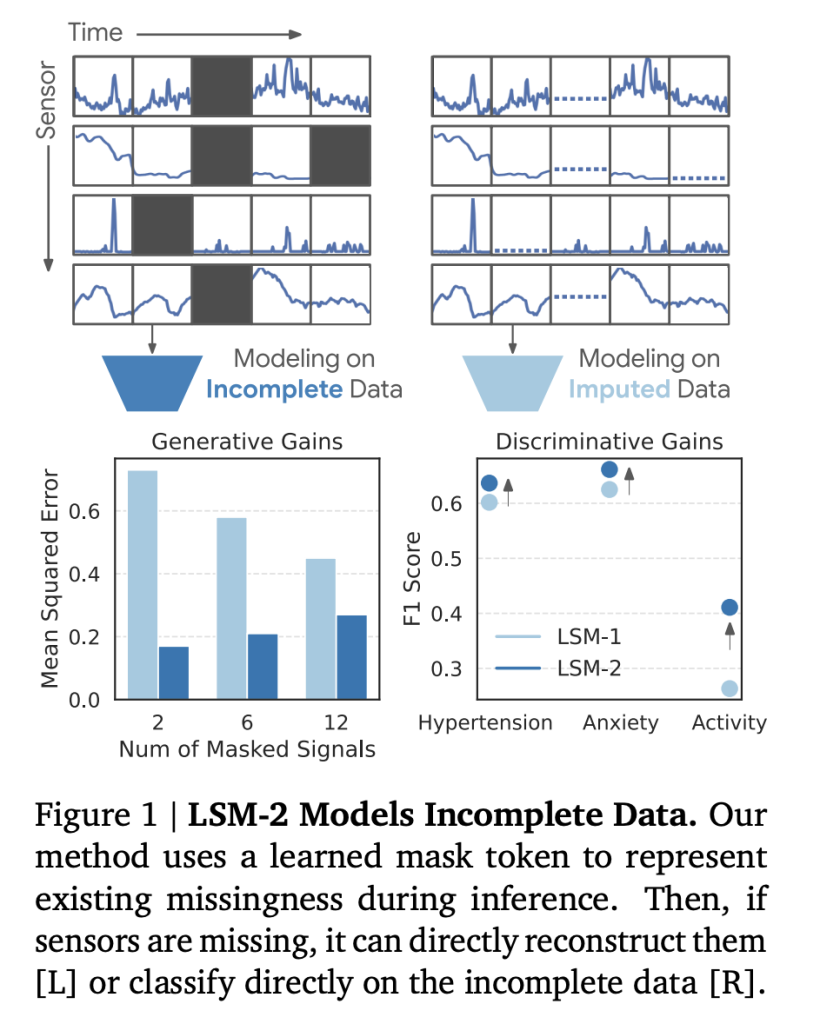
| hypertension | F1 | 0.640 | 0.651 | +1.7% |
| Activity recognition | F1 | 0.470 | 0.474 | +0.8% |
| BMI (Regression) | corr | 0.667 | 0.673 | +1.0% |
| Random interpolation (80%) | MSE(↓) | 0.30 | 0.20 | + 33% reduction in error |
| 2 Signal Recovery | MSE(↓) | 0.73 | 0.17 | +Reduce error by 77% |
- Robustness for targeted disappearances: When a specific sensor or time window is manually deleted, LSM-2 with AIM reduces performance drop by 73% on average compared to LSM-1 (average). For example, after the acceleration assay for removing activity recognition, the F1 loss of LSM-2 was -57%, while the F1 loss of LSM-1 was -71%, and after ablation, LSM-2 retained an absolute F1 of +47%.
- Clinical coherence: The performance degradation of the model matches the domain expectation. Nocturnal biosignal removal significantly reduced the accuracy of hypertension/anxiety predictions (reflecting the realistic diagnostic value of the nocturnal data).
- Zoom: LSM-2 exhibits a better scaling rate than LSM-1 in terms of subjects, data, calculations, and model sizes, and no saturation is observed in performance growth.
Technical Insights
- Directly deal with real-world disappearances:LSM-2 is the first wearable basic model to be directly trained and evaluated without explicit imputation.
- Hybrid masking mechanism: Adaptive and inherited masking can achieve both computational efficiency (through dropout) and flexibility (through attention masking).
- Promoable embedding: Even with frozen backbone and simple linear probes, LSM-2 can achieve state-of-the-art clinical/human and event-level tasks, thus outperforming supervised and contrasted SSL benchmarks.
- Generation and discrimination ability:LSM-2 is the only evaluation model capable of reconstructing lost signals and generating embedded embedded applications for a variety of downstream tasks, demonstrating the utility of real-world medical and behavioral monitoring applications.
in conclusion
The LSM-2’s adaptive and inherited masking forms an important step in deploying AI-driven health insights using real-world wearable sensor data. By directly including ubiquitous, structured loss and unified generation and discrimination capabilities under an efficient and powerful fundamental model, this approach provides an important foundation for the future of wearable and healthy AI in realistic, imperfect data environments.
Check Paper and technical details. All credits for this study are to the researchers on the project.
Researchers with Nvidia, OpenAI, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgan, Amgan, Aflac, Aflac, Wells Fargo and 100s read AI Dev newsletters and researchers read. [SUBSCRIBE NOW]

Michal Sutter is a data science professional with a master’s degree in data science from the University of Padua. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels in transforming complex datasets into actionable insights.


 in the casino")